What kind of method did Dropbox take, which achieved a cost reduction of 170 million yen by machine learning?

Dropbox has achieved a cost reduction of 1.7 million dollars (about 170 million yen) by streamlining the 'file preview function' on its service with machine learning. Win Suen, a machine learning engineer, explains the specific contents of the system.
Cannes: How ML saves us $ 1.7M a year on document previews --Dropbox
Suen explained that Dropbox uses an internal system called 'Riviera' to generate preview data of files in advance in order to preview uploaded files quickly. However, there were cases where pre-generated data was not used and wasted, so a project 'Cannes' was launched to predict the data to be pre-generated by machine learning and save machine resources during data generation. I did.
When developing Cannes, the team focused on 'tolerance of performance degradation in the event of misprediction' and 'simplicity of machine learning models,' Suen said. The former has drawn a line of tolerance in cooperation with the preview display team, and it seems that the line has been set as an accuracy target for machine learning. Regarding the latter, Suen said that the aim was to clarify 'why the prediction result was born' and facilitate debugging in the early stages of introduction by simplifying the machine learning model as much as possible.
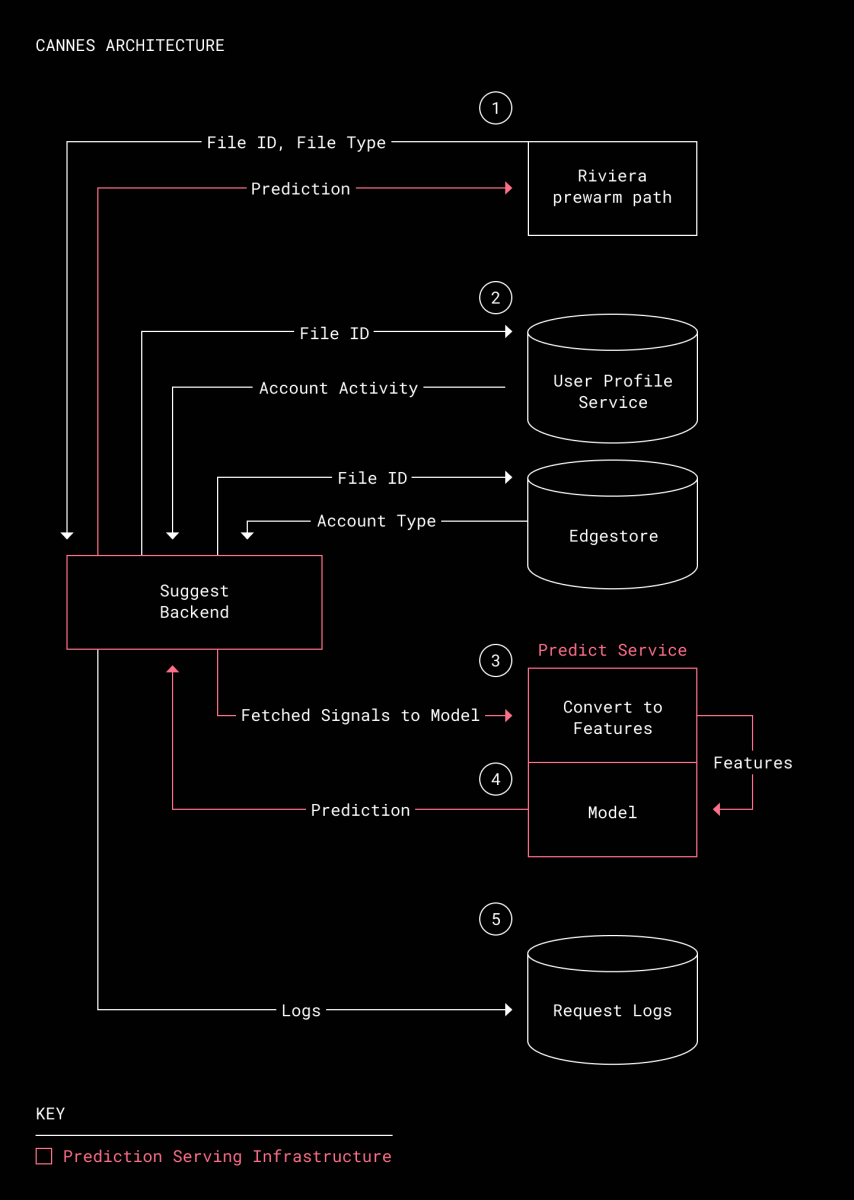
The image below shows the big picture of the preview system, and the pink highlighted part is Cannes. Riviera, which is responsible for generating preview data, first sends the file ID and type of the target for which preview data is to be generated in advance to Cannes. Cannes collects account types and usage from external databases based on file IDs. After the collected data is converted into a vector representing the feature quantity, it is input to the machine learning model, and the model predicts 'whether the file will be previewed in the next 60 days' from the feature quantity. The prediction result is sent to Riviera and is saved as a log together with the features for debugging.
At the time of writing the article, Cannes was applied to almost all traffic on Dropbox, and the development team reduced the annual cost of pre-generating preview data by about 170 million yen as estimated. Since the annual cost of operating Cannes is $ 9000 (about 900,000 yen), you can see that we have achieved a very large cost cut. In the future, the development team will experiment with more complex models to improve prediction accuracy, and will relearn the weights for features and perform 'fine tuning' to fine-tune the model.
Related Posts:






in Software, Web Service, Posted by darkhorse_log