How does Slack deliver software development that balances speed and reliability?

Amid the ever-changing environment surrounding IT services, balancing software development speed and reliability is one of the most important points in development sites.
Deploys at Slack-Several People Are Coding
https://slack.engineering/deploys-at-slack-cd0d28c61701
Slack uses Git for development, and after passing internal code reviews and tests, developers can merge pull requests into the master branch . The deployment of the master branch to the development environment occurs during business hours at our North American base to address any unexpected issues. The deployment is performed 12 times a day, and a responsible person is assigned to each deployment. It seems that the deployment is subdivided to minimize the effects of errors.
When Slack releases a new build of software, it first creates a release branch on Git. The release branch is needed to tag the release history, and is the point of fixing any issues found during the rollout to production. After working on the release branch, deploy the new build to a closed test environment and test. Builds that pass the test are tested by internal employees and, if successful, deployed to an early release environment that accounts for 2% of Slack users. Then, if stable operation can be confirmed, engineers say that it is a mechanism to gradually release new builds to 10%, 25%, 50%, 75%, 100% of all users You.
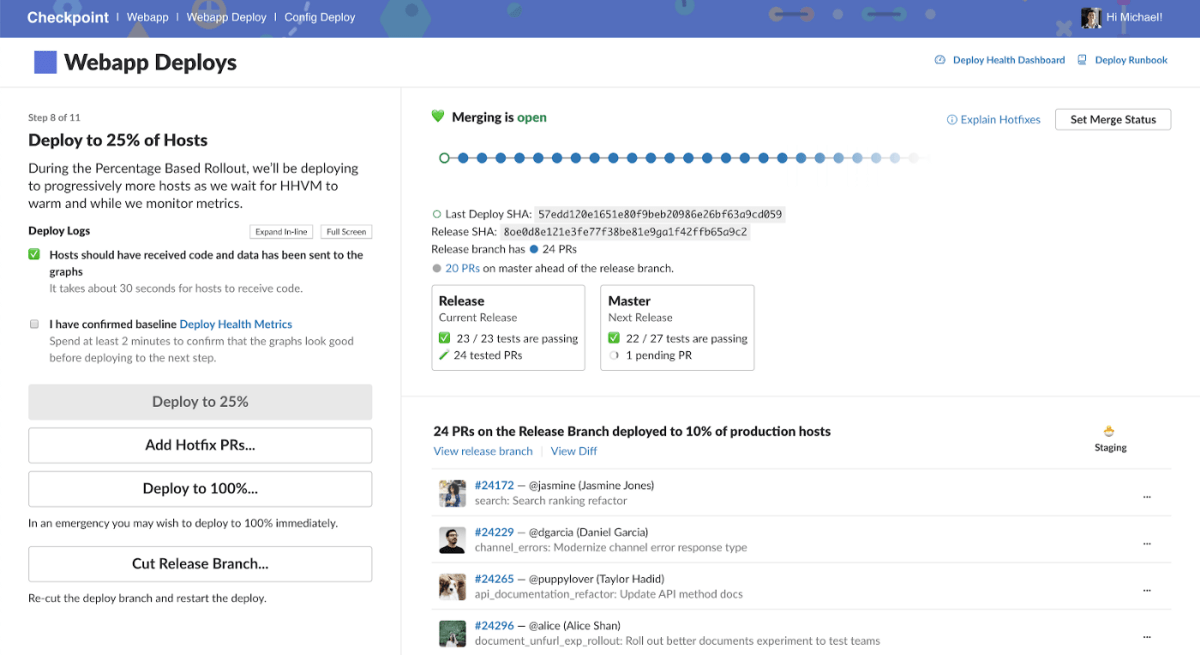
If there is a problem with the deployment, the person responsible for each deployment will direct the response. Find the pull request that caused the problem as soon as possible, fix the problem, and create a new build, but if there is a problem after deploying to the production environment, roll back to the previous build. is.
There was a lot of trial and error before establishing such a development flow. In the days when Slack itself was much smaller than today, it was a system that ran services on 10 instances of
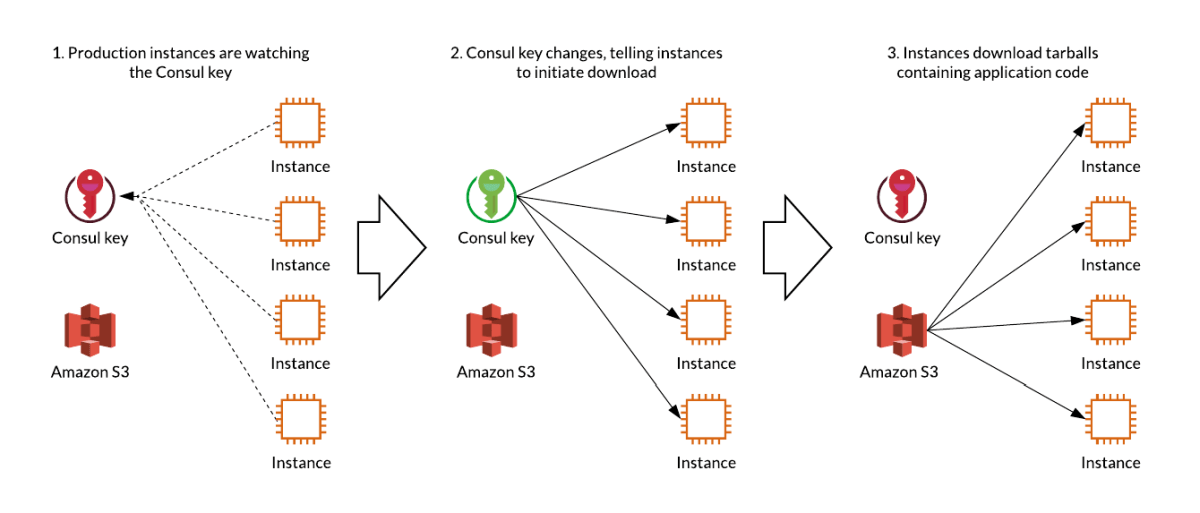
However, as development has accelerated due to Slack's scale, developers have reached their limits by deploying code to each server and synchronizing all servers with rsync. Therefore, each server monitors Consul 's key, and the server that received the key change notification changed to a method that requests deployment to Amazon S3 . This change seems to have enabled it to respond to the acceleration of development due to the expansion of the service scale.
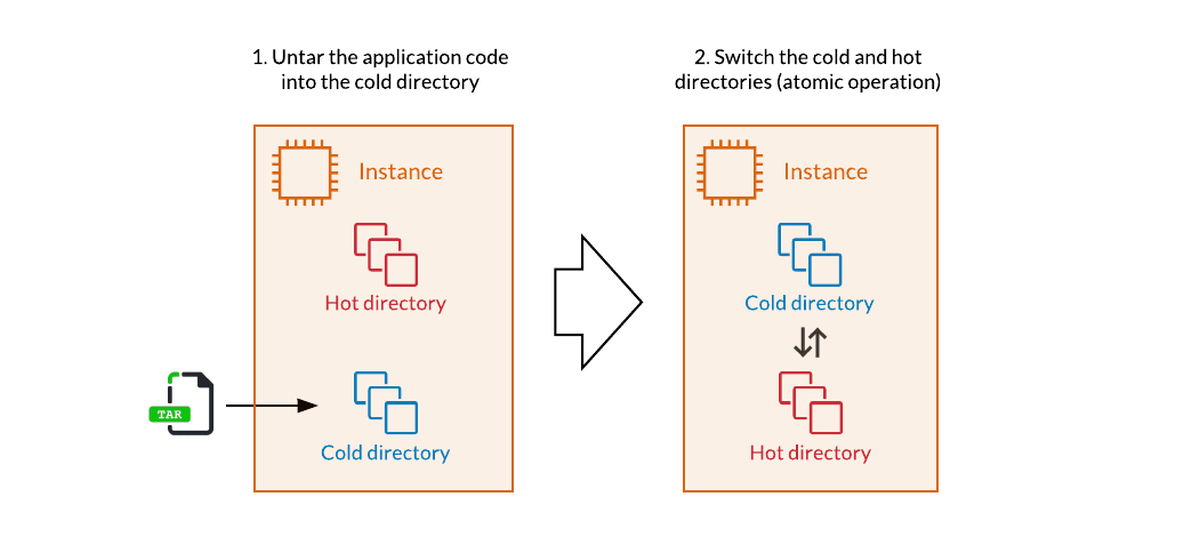
Another project that supports the current deployment system is 'atomic deployment'. Before adopting atomic deployment, deployment was performed directly to the live production environment, so the description for calling the new function was applied before the new function, resulting in an error or broken web page It seems that there was something that happened. In an atomic deployment, a hot directory that is the working version and a cold directory that is not running are prepared, the new version is applied to the cold directory, and the hot directory is replaced with the cold directory. It states that the version can now be deployed.
'We will continue to improve our development systems with better tools and automation,' Chang and Deng comment.
Related Posts:







in Software, Web Service, Posted by darkhorse_log