Slack's massive failure early in the year was caused by a 'start of work'

Slack has released a report summarizing the causes of the
Slack's Outage on January 4th 2021 --Slack Engineering
https://slack.engineering/slacks-outage-on-january-4th-2021/

Slack suffered a major access failure on January 4, 2021 Pacific Standard Time. The failure began around 6am on January 4th and continued to be inaccessible to Slack from 7am to 8:30 am.
Status Site
On January 4, 2021, Slack's infrastructure team observed an increase in service error rates and abnormalities in the monitoring system, and began investigating. The internal console, status screen, logging infrastructure, metrics output infrastructure, etc. were working properly, but the percentage of messages that failed to be sent on Slack was a little high. Since the cause was found to be an upstream network failure, Slack reported to the cloud provider AWS. At this point, it wasn't a big obstacle.
However, during the 'mini-peak' of 7am Pacific Standard Time, Slack's web layer couldn't handle access and began to lose packets, eventually downing the entire service. This 'mini-peak' is an access pattern that is characteristic of Slack, and refers to the phenomenon in which access increases rapidly to '0 minutes per hour' and '30 minutes' due to the message transmission that is executed regularly. In order to cope with these mini peaks, Slack's web layer is set to autoscale based on 'CPU usage' and 'Apache worker thread status', but in this failure, network failures occurred at the same time. As a result, Slack explains that autoscaling behaved unexpectedly.
Below is a timeline diagram of the automatic scaling operation at that time. The CPU usage of the instance decreased because the worker thread was put on standby due to a network failure that occurred before 7:00 am. Based on that information, the web tier is being scaled down. However, when network failures began to affect communication between the web layer and the backend, the number of waiting worker threads surged. Along with that, a significant scale-up was carried out. Between 7:01 am and 7:15 am, 1200 new instances were launched at the web tier.
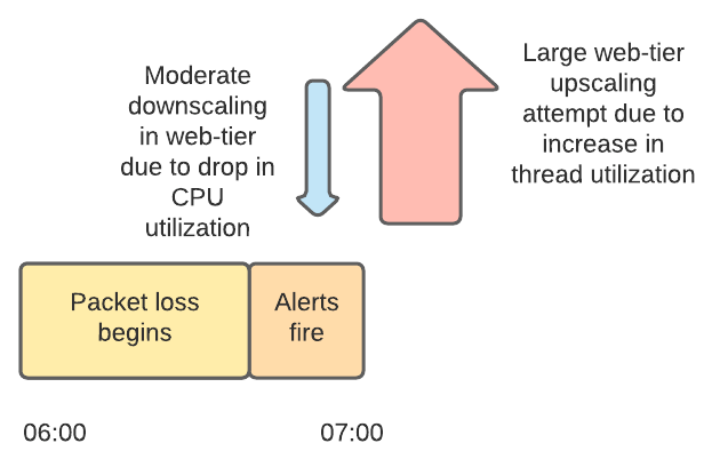
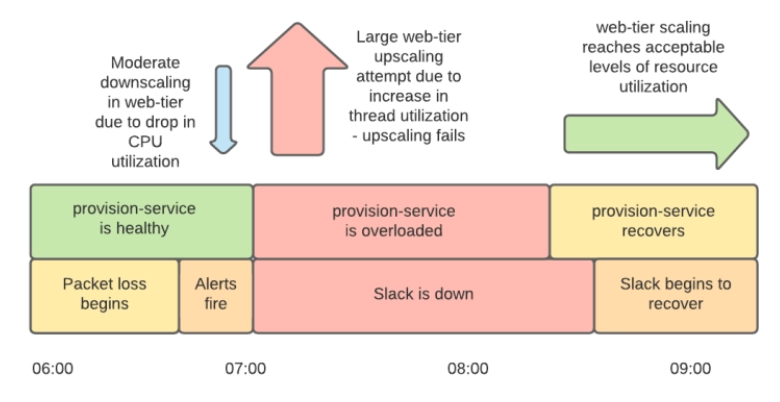
In addition, the provisioning service that performs automatic scaling is also affected by the communication delay due to the network failure, and by performing the process of starting a large number of instances under that situation, the provisioning service also says 'the maximum number of file open in Linux'. I reached the 'AWS
At around 8:15 am, the infrastructure team restored the provisioning service and the web tier was ready to serve. Although errors still occurred in the load balancing layer, Slack's service could be recovered by using ' panic mode ' that distributes traffic evenly to all instances when a large number of errors occur. That thing. However, due to the effects of network failures, Slack's services were still delayed.
Eventually, an AWS engineer's investigation revealed that the network failure occurred in the
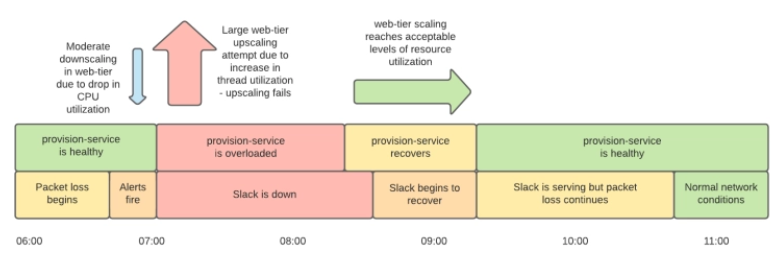
The initial monitoring system anomaly was also due to TGW, where the dashboard instance and backend database were located in separate VPCs and depended on communication via TGW. Following this failure, AWS reported to Slack that it would review TGW's scaling algorithm. Slack also reports that it has set reminders to pre-scale TGW during the next long vacation, load-test provisioning services, and review alive monitoring and auto-scaling settings.
Related Posts:







in Web Service, Posted by darkhorse_log