Google publishes detailed report of large-scale failure affecting YouTube, Gmail, Google calendar, etc.

Google has released a detailed report summarizing the causes and extent of the
Google Cloud Status Dashboard
https://status.cloud.google.com/incident/zall/20013#20013004
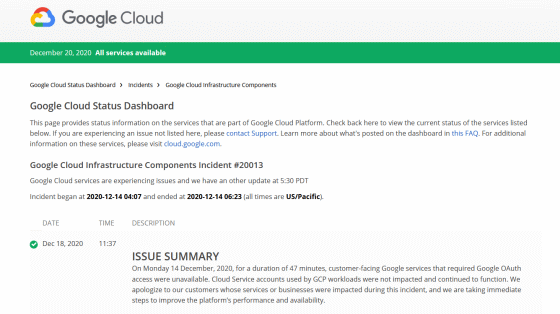
On Monday, December 14, 2020 Pacific time, a major failure occurred that made services such as YouTube and Google Calendar unavailable. The cause was a malfunction of the authentication service, and the failure lasted for about 45 minutes.

The contents of the trouble report by Google are as follows.
◆ Cause
Google's user ID service manages identifiers assigned to each user and controls tokens and cookies for
Google uses a quota system to limit the resources allocated to each service. The quota system was updated in October 2020, but there was an omission in some updates, and the old quota system remained. In addition, older systems were misrepresenting the User ID service as 'no capacity available'. Since the quota had a grace period, it did not fail for a while after the system update, and the monitoring system could not detect the problem.
However, Google said that the quota grace period was over, the distribution database update was restricted and the account data became outdated, and as a result, the request from the user ID service to the database was rejected and the authentication function failed. Explains.

◆ Impact
From 3:46 am to 4:33 am local time on December 14, 2020, all Google accounts were unable to authenticate and search for metadata. As a result, the service loses control of the authenticated request and an error occurs for all authenticated traffic. Basically, all Google services that use authentication were affected, but the services that were significantly affected are as follows.
-Google Cloud Console: Unlogged-in users could not log in, and logged-in users could use the service except for some functions.
-Google BigQuery:
· Google Cloud Storage (GCS): Approximately 15% of requests were affected by the failure, especially when using OAuth, HMAC , and email authentication. Even after the failure was resolved, up to 1% of the users who started uploading during the failure were still unable to complete the upload.
-Google Cloud Networking: In the control plane, the error rate continued to rise until 5:21 am on December 14, 2020. For the data plane, only VPC networking change operations were affected.
-Google Kubernetes Engine (GKE): During the failure, up to 4% of the requests to GKE's control plane API were in error. Also, almost all services were unable to send metrics to Cloud Monitoring . During the first hour of the failure, there was a problem processing users running on up to 1.9% of GKE nodes.
· Google Workspace: All Google Workspace services are no longer available during a failure. Almost all Google Workspace services were restored at 5am, but there was a surge in traffic on Google Calendar and the admin console shortly after the restoration. Regarding Gmail, the problem continued because it was referring to the error data cache for up to 1 hour after the failure recovery.
· Cloud Support: Google Cloud Platform and Google Workspace Status Dashboard were affected by a failure, delaying failure sharing with users. The user was unable to create or view the case in the Cloud Console. After 5:34 am, the problem was resolved.
◆ Countermeasures and future measures
The failure was notified to engineers by an automatic alert about capacity in the US Pacific region at 3:43 am, a user ID service error at 3:46 am, and a user notification at 3:48 am. At 4:08 am, the root cause and potential remediation were identified and the quota enforcement was disabled at the data center at 4:22 am. This quickly improved the situation, with the same mitigation applied to all data centers at 4:27 am and error rates returning to normal levels by 4:33 am.

In addition, Google will take the following measures to prevent the recurrence of the failure.
・ Review of quota system
・ Review the monitoring system so that failures can be detected immediately.
-Improve the reliability of tools and procedures that notify externally of failures in the event of a failure that affects internal tools such as dashboards.
-Evaluate and implement the recovery function of the user ID service write to the database.
· Improve the fault tolerance of GCP services and further reduce the impact of user ID services on the data plane in the event of a failure
Google commented, 'We apologize for the impact this accident has had on our users and their businesses.'
Related Posts:





in Software, Web Service, Posted by darkhorse_log