How did Figma scale its database to handle high volumes of traffic?
The database (DB) of the browser-based design tool ' Figma ' has expanded 100-fold since 2020. The official blog provides a detailed explanation of how the DB, which was originally built on a single PostgreSQL database, was migrated to a distributed system.
How Figma's Databases Team Lived to Tell the Scale | Figma Blog
Figma first performed 'vertical partitioning' by dividing the database into tables such as 'Figma files' and 'organizations.' By 2022, the database will be divided into 10 partitions, and each partition will be monitored to prioritize scaling.

As the number of Figma users increased, table-based partitioning reached its limits, and it became necessary to perform 'horizontal partitioning' to partition the data within a table. By partitioning tables horizontally on the application side, any number of shards can be used at the physical layer, dramatically improving scale.
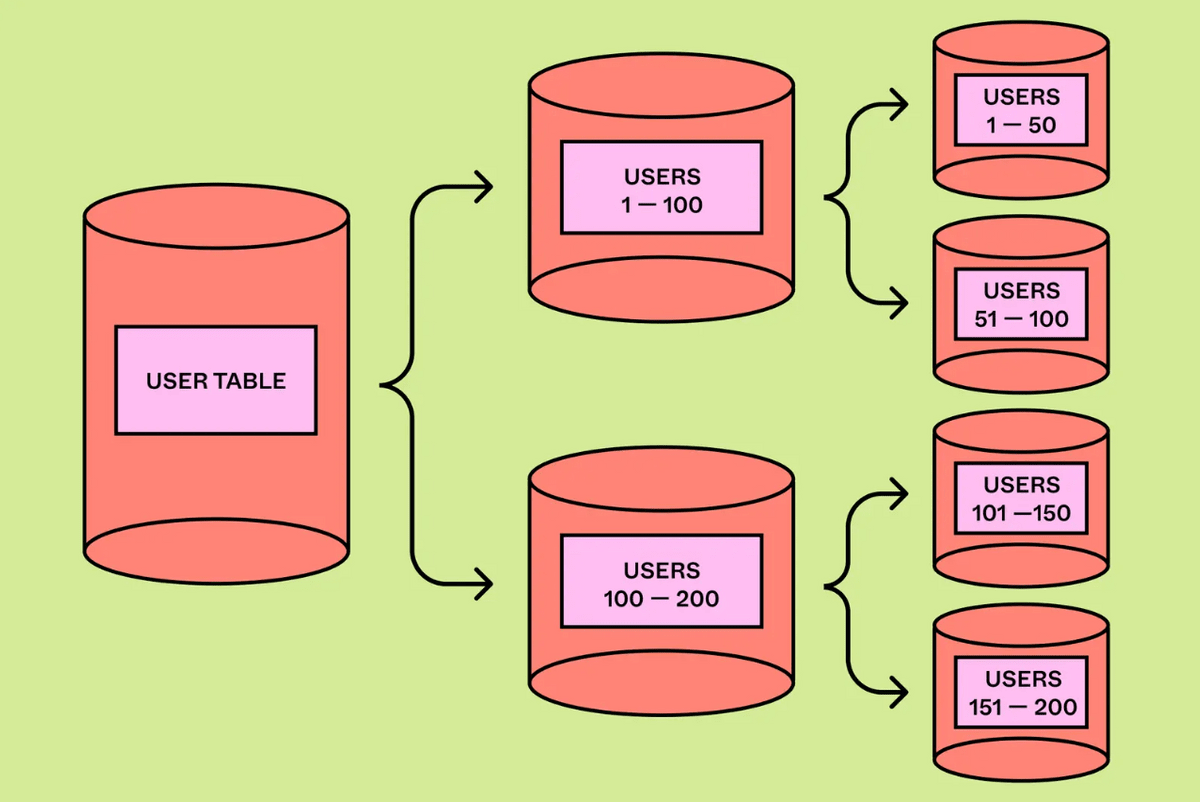
However, horizontal division causes the following problems:
Some SQL queries will become inefficient or unsupportable
The code needs to be updated to provide information that allows it to efficiently route queries to the correct shards.
Foreign keys and globally unique indexes cannot be enforced
Transactions that span multiple shards may partially fail
Knowing that achieving full horizontal partitioning would be a long journey, the Figma development team first partitioned a simple but highly trafficked table to prove the feasibility of horizontal partitioning while reducing the load on the DB. It took the team 9 months to partition their first table.
When using horizontal partitioning, most queries must include a shard key so that they can be routed to the appropriate shard. 'What to use as a shard key' is an important question for distributing traffic appropriately. Figma decided to use several IDs, such as UserID, FileID, and OrgID, as shard keys.
Figma introduced the concept of 'Colos' to allow related tables to be horizontally partitioned in the same way and stored in the same physical shard, allowing queries using a single shard key to support joins between tables and full transactions. Using Colos also minimized code changes to the application.
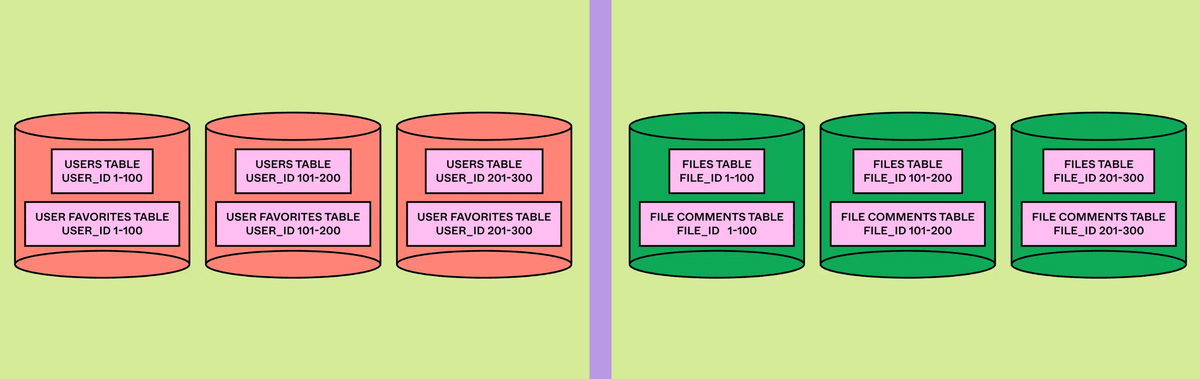
In addition, the various IDs used as shard keys were auto-incremented or contained Snowflake timestamps as prefixes, which did not ensure randomness and could result in concentrated load on specific shards, so we decided to use a hash of the shard key for routing. This approach reduces the efficiency of range scans because consecutive keys are placed on different shards, but this was acceptable because queries requiring range scans are not common in Figma.
In Figma, to avoid risks when performing horizontal partitioning, the process of preparing the table in the application layer is separated from the process in the physical layer that performs the actual partitioning. When a table is logically partitioned in the application layer, it can be operated from the application side as if the horizontal partitioning has already been performed, even if it is actually on a single physical shard. After performing logical sharding and confirming that the data was being processed without any problems, we performed physical horizontal partitioning.

Initially, applications communicated directly with PGBouncer, a connection pooling layer to the DB. However, horizontal partitioning requires advanced query analysis, planning, and execution, so we implemented a new DBProxy.

DBProxy includes a lightweight query engine in addition to load reduction, monitoring, transactions, and database topology management. The main components of the query engine are the query parser, logical planner, and physical planner. The query parser reads SQL and converts it into an abstract syntax tree (AST).
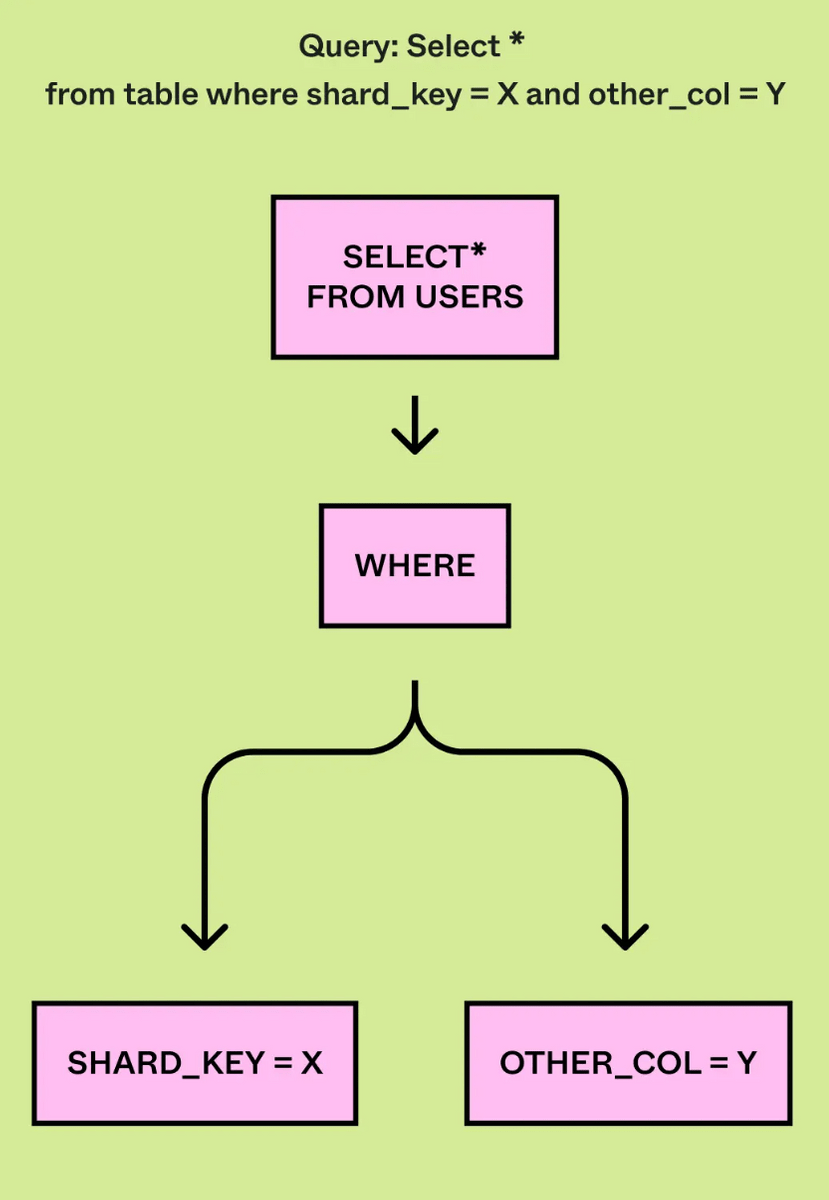
The logical planner parses the AST and extracts the query type (e.g., “Insert” or “Update”) and the logical shard ID from the query plan.
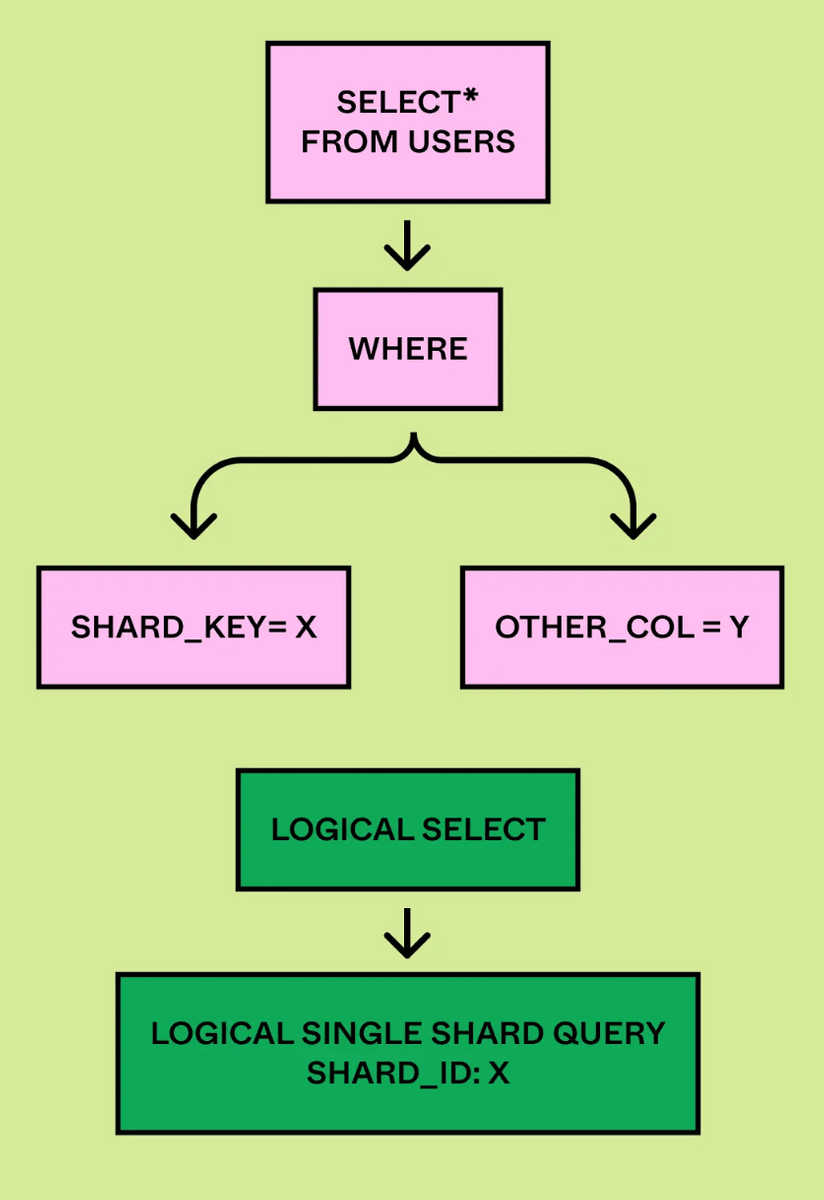
The physical planner maps queries from logical shard IDs to physical databases and rewrites the queries to run on the appropriate physical shards.
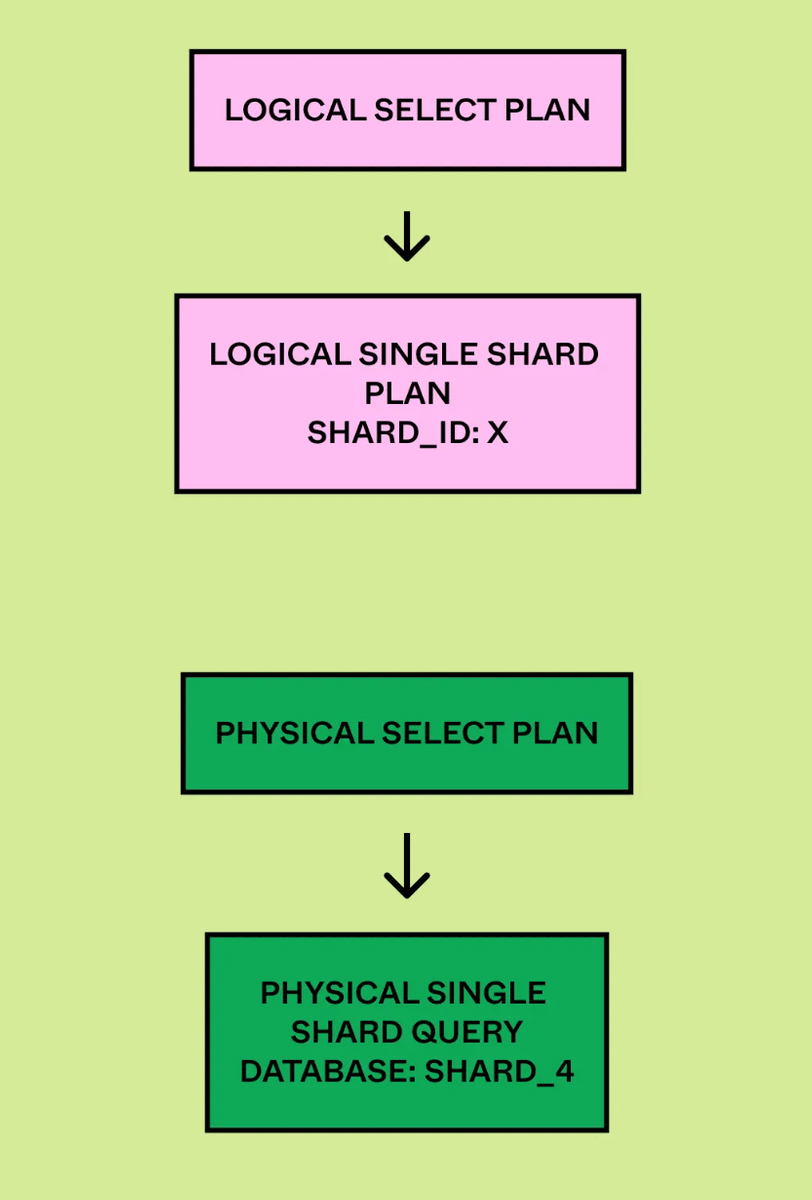
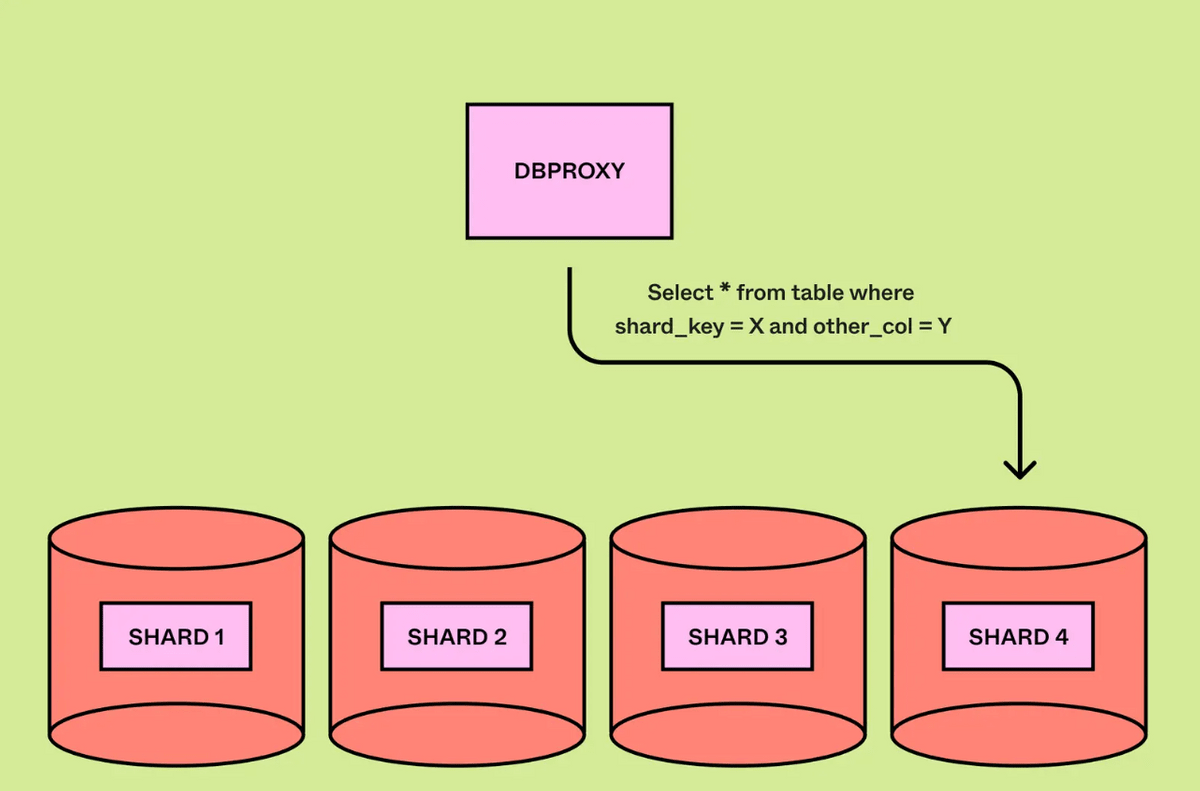
If the query is a single-shard query, the query engine's only job is to extract the shard key and route the query to the appropriate physical shard.
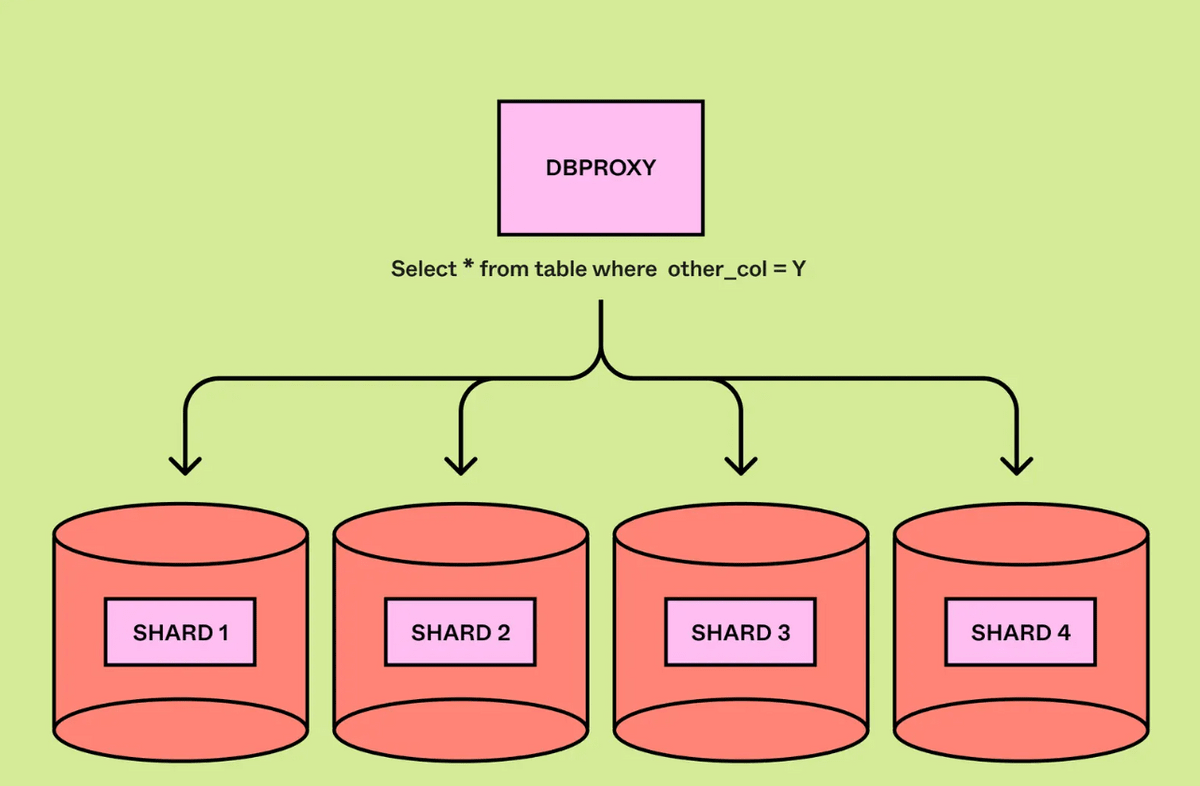
On the other hand, if a query needs to be processed across multiple shards, the query engine must pass the query to all shards and aggregate the results. A query that spans multiple shards incurs the same overhead as if the database were not partitioned.
To encapsulate logical shards, PostgreSQL's 'view' feature was used. By creating multiple views that refer to only certain ranges of the DB in response to shard splitting, and writing and reading via the views, it is possible to operate as if the shards have already been split. By gradually rolling it out using the query engine's feature flags, they were able to verify that appropriate horizontal splitting was being performed with reduced risk.
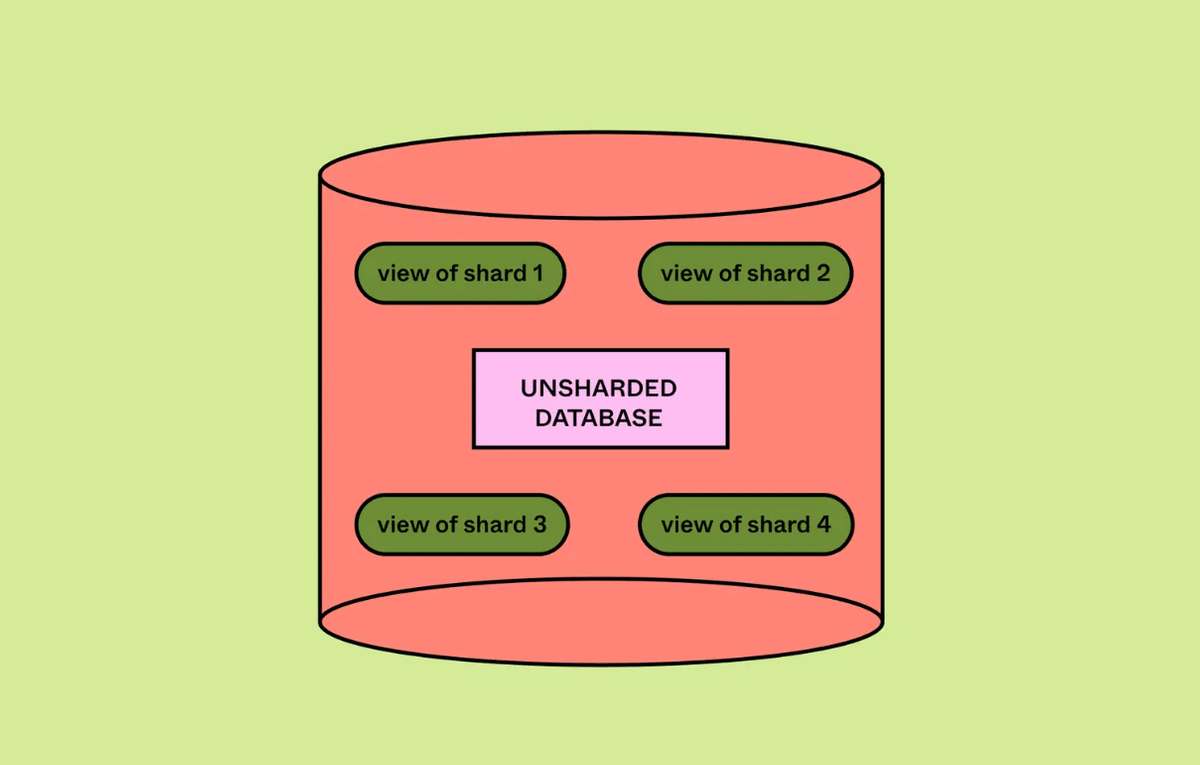
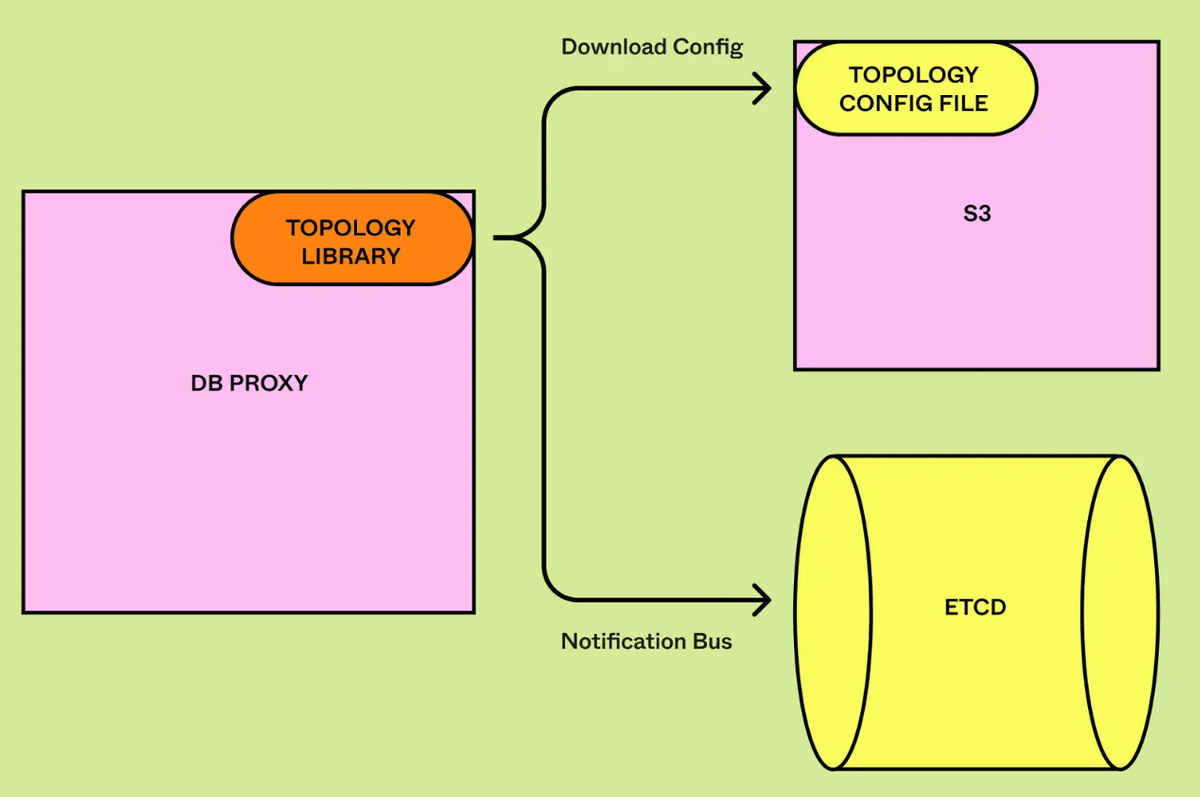
To perform appropriate query routing, DBProxy needs to know the relationship between tables and physical databases. When vertical partitioning was performed, which tables were located in which partitions was hard-coded in the configuration file, but with horizontal partitioning, the connection relationships change dynamically during shard splitting, so the relationships had to be updated quickly to avoid routing to the wrong shard. Figma encapsulates the metadata of horizontal partitioning, allowing real-time updates within one second.
Once the horizontal split is ready, the last step is to fail over from the original DB to the sharded physical DB. Figma performed its first horizontal split in September 2023. The impact on availability was only 10 seconds on the primary, and there was no impact on availability on the replica side. There was also no degradation in latency or availability after the horizontal split.
Figma said it will work on horizontally partitioning a complex database with dozens of tables and thousands of call sites in 2024, stating that 'to remove the last scaling limitations and truly make the leap, we need to horizontally partition all of Figma's tables.'
Related Posts:






in Software, Posted by log1d_ts