How to make object storage lookups cheaper and faster

Simon Holp Eskildsen, developer of the fast search engine service for object storage 'turbopuffer,' posted a blog about how he made it possible to search object storage cheaply and quickly.
Turbopuffer: fast search on object storage

Eskildsen summarized the five databases commonly used in modern infrastructure stacks in the table below. Because using an appropriate dedicated database for each workload is a heavy operational burden, it is better to use a relational database such as Postgres or MySQL until a specific workload starts causing frequent problems.
| category | Technology | Read Latency | Write Latency | storage | Use Case |
|---|---|---|---|---|---|
| cache | Redis, Memcached | <500µs | <500µs | memory | Performance-driven |
| RDB | MySQL, Postgres | <1ms | <1ms | Memory + SSD | SOT /Transaction/ CRUD |
| search | ElasticSearch, Vector DBs | <100ms | <1s | Memory + SSD | Recommendations, Search, Feeds, RAG |
| keep | BigQuery, Snowflake | >1s | >1s | Object Storage | Reports and Data Analysis |
| Streaming | Kafka, Warpstream | <100ms | <100ms | HDD/Object Storage | Logs, data movement between systems, and real-time analysis |
While helping develop a reader app called Readwise Reader in 2022, Eskildsen had the experience of forgoing the implementation of article recommendations and semantic search because the infrastructure costs were too high to migrate from an RDB to an in-memory database. At the time, the enterprise-grade vector database used in-memory storage and cost $2 (about 323 yen) per GB.
With the spread of object storage and the evolution of technology such as NVMe SSDs becoming cheaper and faster, it is now possible to significantly reduce costs by using a mixture of disk media and in-memory storage instead of storing all data in memory.
If data is stored in triplicate on three SSDs and the average storage utilization is 50%, the cost drops to $0.60 (approximately 97 yen) per GB. In addition, by using object storage such as AWS S3 or GCS, which can be used for approximately $0.02 (approximately 3 yen) per GB for data that is accessed infrequently, or by using SSD cache, which can be used for approximately $0.10 (approximately 1.6 yen) per GB, data can be stored at up to 1/100th the cost of memory.
In light of this, Eskildsen developed 'turbopuffer' as a new approach to search that combines cost-effectiveness with high performance.
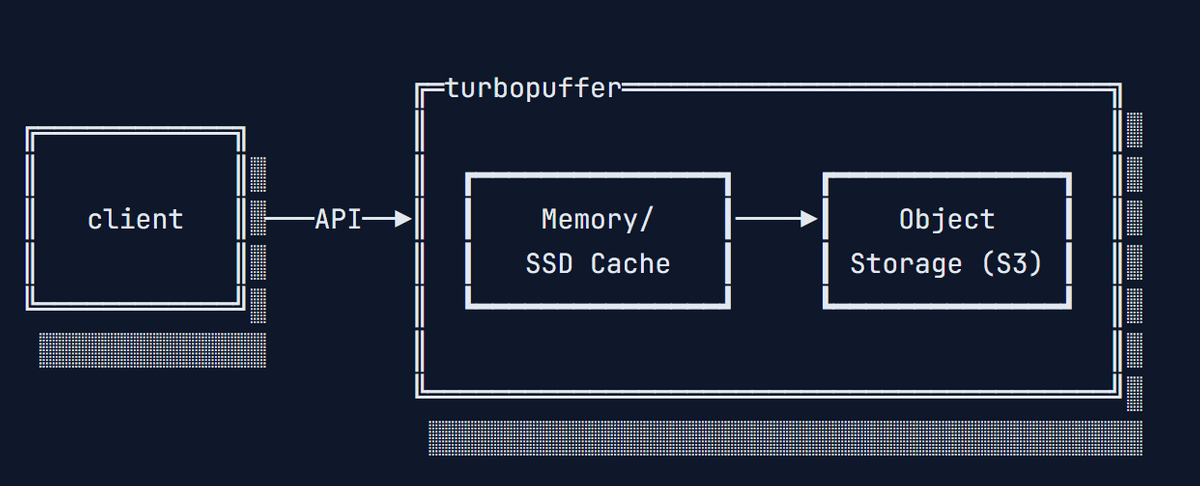
Traditional search engines are built using the replicated disk architecture of RDBs, which provides low latency and very high concurrency for updates and transactions. However, search engines have features that require low write latency or no transactions, and by using RDBs, you are paying for unnecessary functionality, Eskildsen points out.
By storing frequently accessed data in an SSD cache and infrequently used data in inexpensive object storage, it is possible to significantly reduce costs while maintaining the same response time for most search queries. Although there is a drawback in that some queries experience long delays of hundreds of milliseconds, the cost savings are more valuable than the impact of the delay.
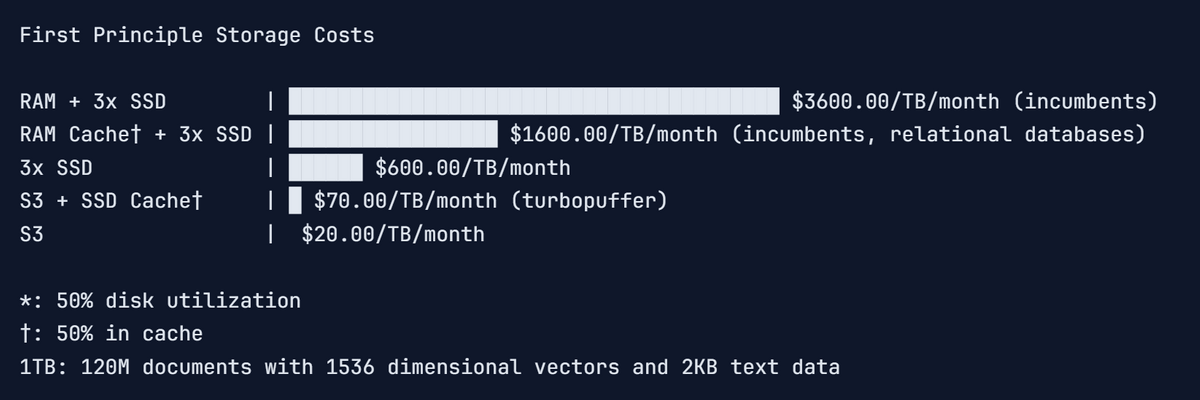
Here's an idea of the query processing time: Even for cold queries that require reading data from object storage, the number of round trips is dynamically adjusted to ensure the fastest possible processing.

Although turbopuffer is still in the development stage, it has already been adopted by the AI code editor Cursor , and customers are encouraged to contact them if they would like to use it as an early customer.
Related Posts:







in Free Member, Software, Posted by log1d_ts