An insider explains how AWS block storage has evolved
Mark Olson, who has been involved in the development of AWS' Elastic Block Store (EBS) for over 10 years, posted a blog post looking back on how EBS evolved from a simple block storage service that relied on shared drives to a massive networked storage system that performs over 140 trillion operations every day.
Continuous reinvention: A brief history of block storage at AWS | All Things Distributed

EBS launched in 2008, two years after EC2 became available in beta. It started with a simple idea to provide network-attached block storage to EC2 instances, and was staffed by just one or two storage experts and a handful of distributed systems people.
Before joining Amazon, Olson worked in the fields of networking and security, and began working on storage when he joined Amazon in 2011. Olson began developing the EBS client, which converts instance IO requests into EBS storage operations, and has worked on almost every component of EBS as it has evolved.
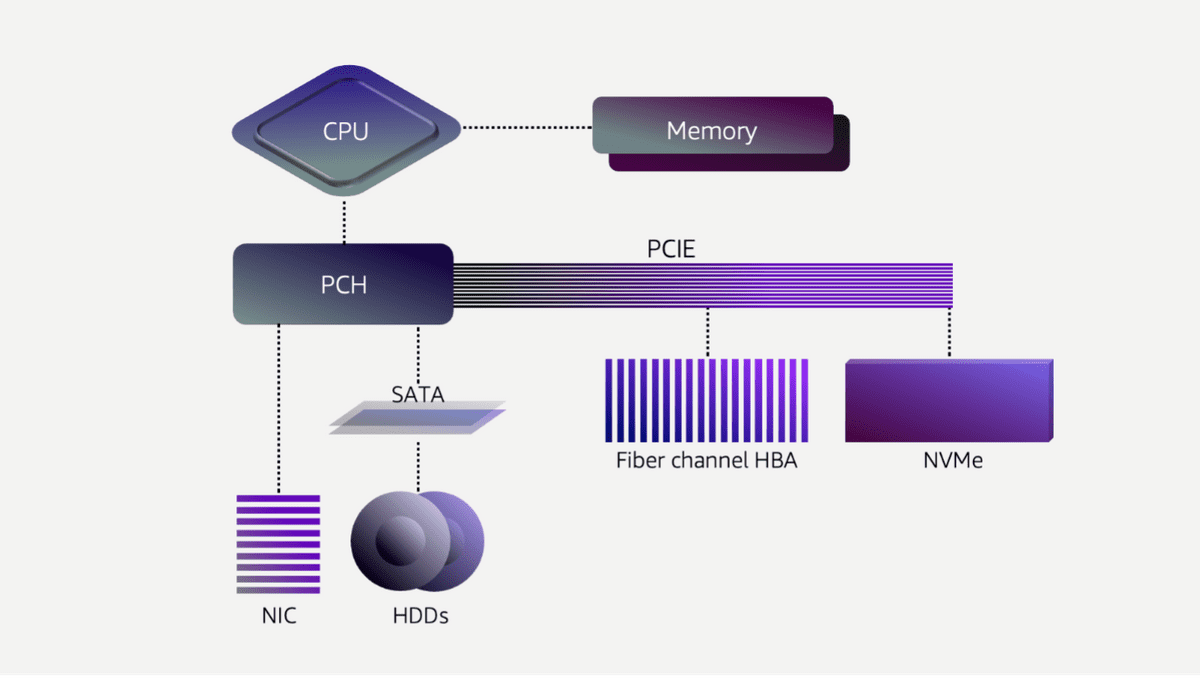
The basics of how a computer interacts with storage haven't changed at all: both the storage device and the CPU are connected to a bus, and when the CPU sends a request to the device, the device either stores the data in memory on durable media like a HDD or SSD, or reads the data from the media and places it in memory.
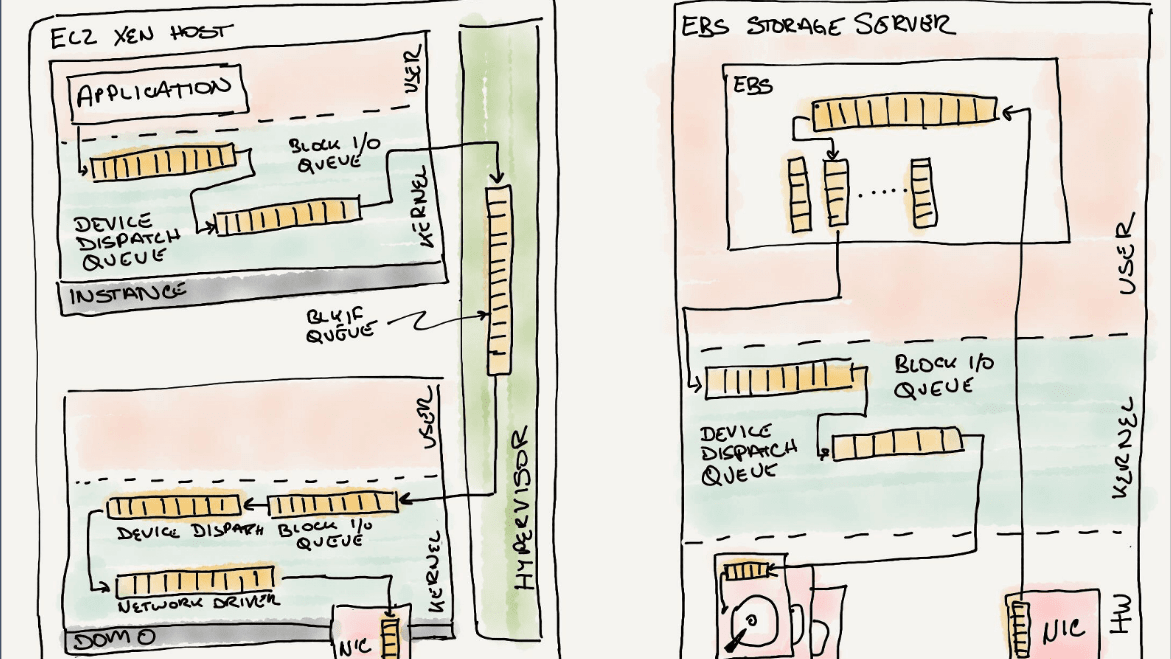
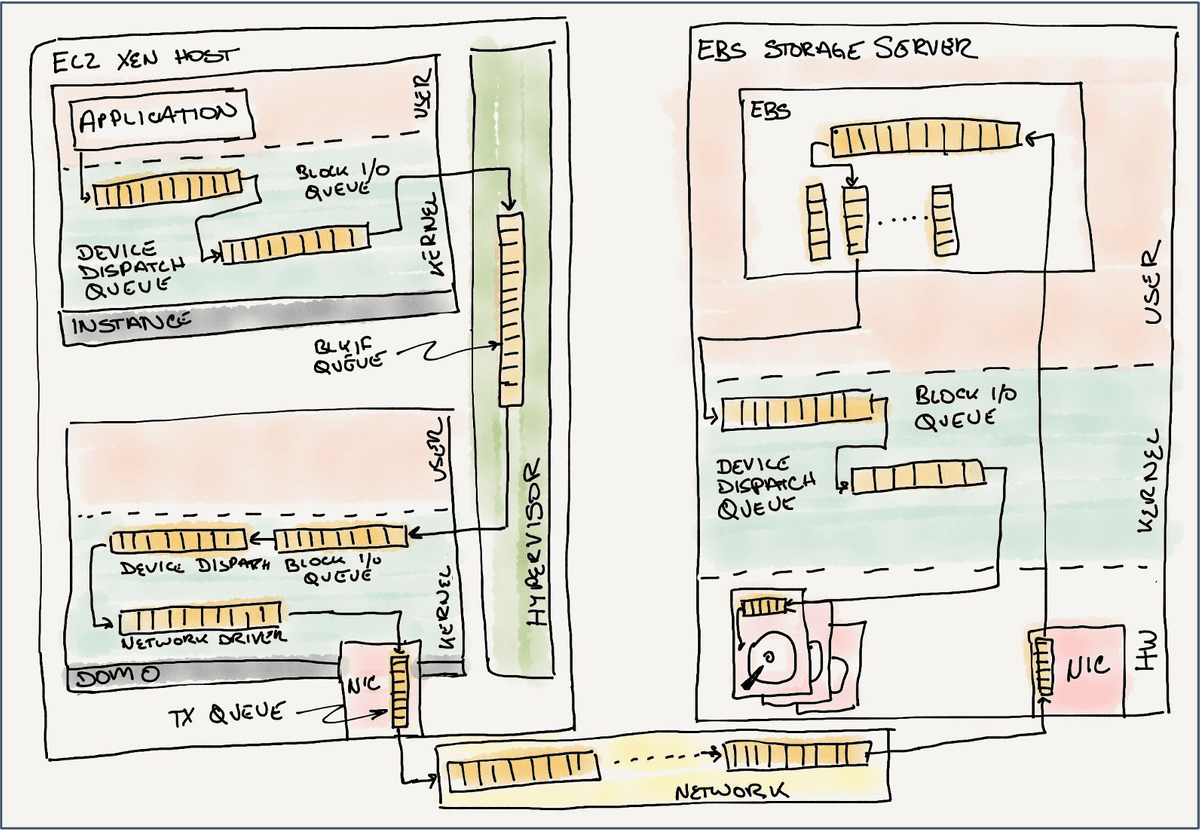
When multiple requests arrive at the same time, the storage queues the requests and processes them in order. In network storage systems, queues are provided at various layers, such as between the OS kernel and the storage adapter, between the host storage adapter and the storage fabric, and between the target storage adapter and the storage media.
When EBS started in 2008, most of the storage was HDD, and the latency of the entire service was mostly determined by the latency of the HDD. Although manufacturers have made various efforts to increase speed, HDDs always have an average latency of 6 to 8 milliseconds due to the physical constraint of having to move the arm to the appropriate position on the rotating platter. In addition, if data is stored in a fragmented and distributed manner, it takes time to read, and sometimes latency of several hundred milliseconds can occur.
Therefore, early EBS latencies were measured in tens of milliseconds, and even adding tens of microseconds of network latency had little impact. The EBS development team named a workload that affects another workload a 'noisy neighbor' and worked to reduce the impact of this neighbor. Although they made improvements such as changing the drive scheduling algorithm and balancing user workloads across spindles, user workloads were unpredictable and they could not achieve the necessary consistency.
Because SSDs are not constrained by physical arms and can perform random access very quickly compared to HDDs, the EBS development team thought that simply replacing HDDs with SSDs would solve almost all of the problems. In 2012, SSDs were introduced and the latency of the media portion was greatly improved, but the system as a whole did not improve as much as the EBS development team had hoped, and it became necessary to pay attention to the network and software portions.
By measuring various indicators to improve system performance, the EBS development team investigated 'which parts should be improved'. They simultaneously worked on short-term improvement efforts and long-term architecture change efforts. In addition, they divided the development team and divided the areas they were responsible for so that they could continuously improve the same areas.
The EBS development team improved processing speed by utilizing virtualization and developing dedicated hardware called Nitro to handle packet processing. At the same time, they reduced network overhead by developing a protocol called 'Scalable Relatable Diagram (SRD)' to replace TCP. Olson said, 'It's important to always question assumptions and focus on the most important points by measuring and analyzing.'
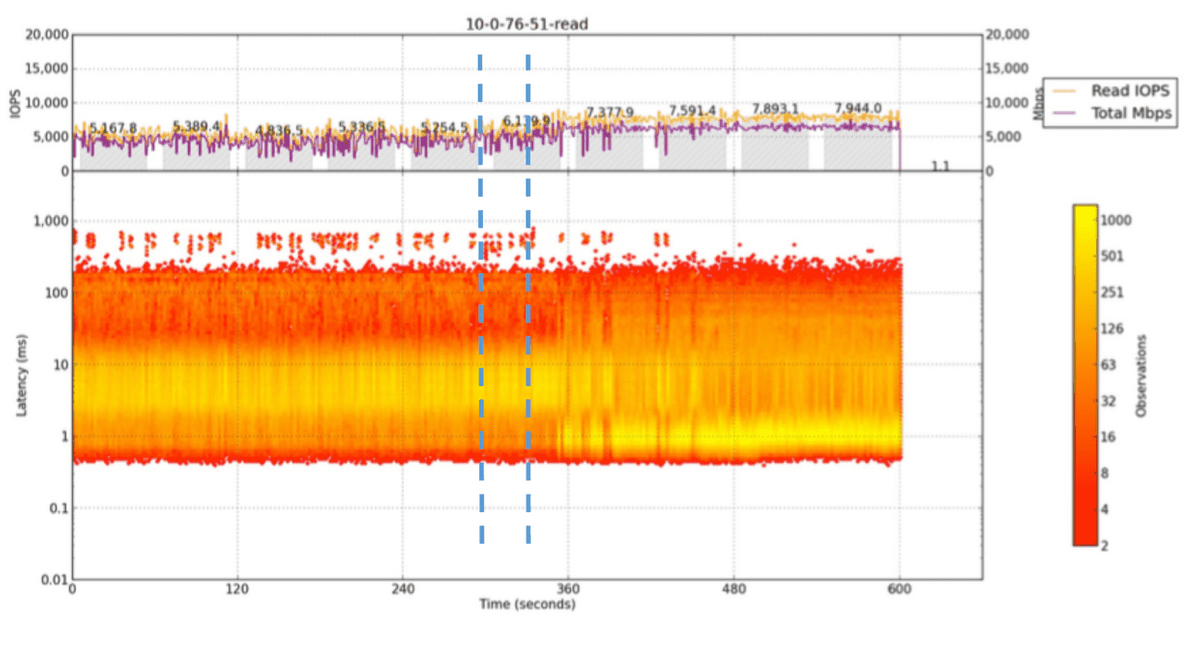
As a result of these development team's efforts, the average latency of EBS, which was over 10 milliseconds at the start of the service, was improved to less than 1 millisecond as of 2024. As EBS is used as a system disk for EC2 instances, it has a somewhat unique constraint as a storage system that requires emphasis on performance as well as durability, and in order to develop it into a large-scale network storage system that performs more than 140 trillion operations every day, it was necessary to understand a large-scale distributed system spanning many layers, from the guest OS at the top to the custom SSD design at the bottom.
Olson concludes the blog post by writing, 'Our customers are always looking to improve, and it's that challenge that drives us to keep innovating and iterating.'
Related Posts:






in Hardware, Software, Web Service, Posted by log1d_ts