Facebook announces Presto, an open-source SQL-enabled distributed query engine, capable of petabyte-scale data processing

ByIntel Free Press
Presto is an open-source SQL-enabled distributed query engine that can interactively analyze data of any size from gigabytes to petabytes (1 million gigabytes) and find necessary data. It is designed to be able to process even a large amount of commercial data possessed by a company such as Facebook at high speed, and Presto's query (processing request for the database management system as a character string) It is also possible to combine. Facebook that developed this system stores about 300 petabytes of internal company dataData warehouseWe use Presto at, every day more than 1,000 Facebook employees run more than 30,000 queries per day, more than 1 petabyte of data are being scanned.
Presto | Distributed SQL Query Engine for Big Data
http://prestodb.io/
Presto: Interacting with petabytes of data at at
https://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/10151786197628920
History behind Facebook's development of Presto
Facebook is a company dealing with large amounts of data. In this monster social network service where there are more than 1 billion active users, data processing and analysis is the core part of the business. Facebook's data warehouse is one of the world's largest, where it stores more than 300 petabytes of data and the data stored there is traditionalBatch processingFromGraph analysis, Machine learning and real-time interactive analysis, and so on. For analysts, data scientists, engineers and others who process data and insight and contribute to improving Facebook's service, the details of the performance of this data warehouse are important information and more queries can be executed If you can get results faster, their productivity will also be improved.

ByIntel Free Press
The data of the Facebook data warehouse on FacebookHadoop/ It is stored in HDFS-based computer cluster, and it seems to be large scale and to make efficient use of system processing capacity efficientlyHadoop MapReduce(Data distributed processing technology)Hive(It is optimized for data aggregation, inquiry and analysis in data warehouse construction environment built on Hadoop). However, Facebook's data warehouse is a very large scale of petabyte size, and data seems to be gradually increasing. Therefore, I decided to build Presto, a new interactive query system that can operate quickly even on a petabyte scale.
◆ Presto
Presto is a SQL-enabled distributed query engine optimized for interactive ad hoc analysis and supports standard ANSI SQL. The figure below briefly shows Presto's system architecture, in which the client sends SQL (a query language for manipulating and defining data) to Presto's coordinator (coordinator). The coordinator deconstructs and analyzes, plans execution plans of queries, draws execution pipelines, assigns jobs to nodes close to data, and monitors the progress of data processing. Clients can also pull data at each stage from the output stage.
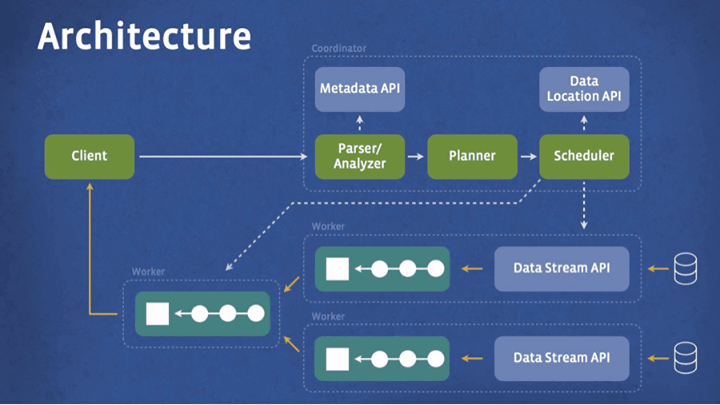
Presto's query engine does not use MapReduce, it supports custom queries and semantic search execution engines. The execution scheduling of queries has been improved, plus all data processing is done on memory and pipelines in the network, avoiding unnecessary I / O etc. Presto's system runs in Java because it's quick to develop, has a big ecosystem, and makes it easier to integrate with Facebook's other data infrastructure components. In addition, careful handling of memory and data structure, memory allocation often occurs in Java codeGarbage collectionThe problem is avoided.
Scalability is one of the important elements of Presto. Facebook engineers found that large datasets (chunks of data to be processed) were stored in many other systems in addition to HDFS in the early stages of the project. And the data storage location of Facebook data warehouse,HBaseIt was also stored in famous databases like those with custom made one. In this way Presto seems to be designed to be able to easily provide SQL queries to simple and different data sources.
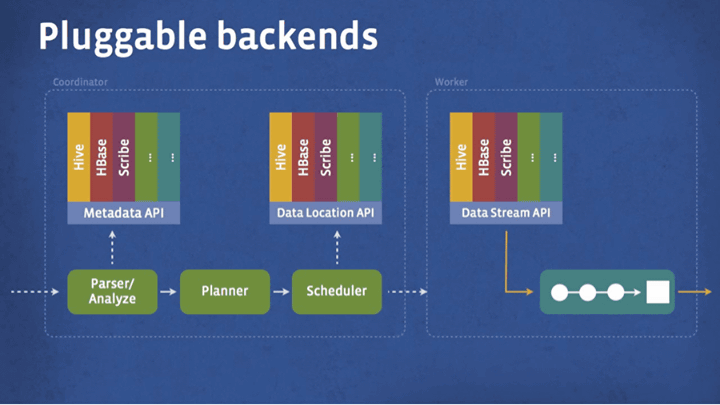
The development of Presto began in the fall of 2012, started the first operation around the beginning of 2013, and in the spring of 2013 it is now operated throughout the Facebook data warehouse. From the point of view of CPU efficiency and processing speed, Presto will give results 10 times better than operating Hive / MapReduce. What we currently support is a subset of ANSI SQL, such as table join, outer join of tables, subquery, common extraction, scalar function, approximate search etc. However, There is a limit on cardinality. Query results are sent to the client, but it is currently impossible to output data to each table.
Note that Presto is an open source query engine,GitHubYou can see the source code at.
Related Posts:






in Software, Web Service, Posted by logu_ii