PostgreSQL should not store 'half-sized' data

Websites and applications use a wide variety of sizes of text, from small ones such as usernames and email addresses to large ones such as blog bodies. In general, we do not use different databases depending on the text size, but software engineer Haki Benita explained the research results and the mechanism that storing 'half size' text data in PostgreSQL database leads to performance degradation. Explains.
The Surprising Impact of Medium-Size Texts on PostgreSQL Performance | Haki Benita
https://hakibenita.com/sql-medium-text-performance
For PostgreSQL, database indexes and tables are organized by 'pages'. The page size is uniform and data cannot be recorded across multiple pages. If you want to insert a small value into the table, there is no problem because the value will fit in the table as it is, but if you want to store a large value, you need to be creative.
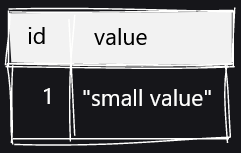
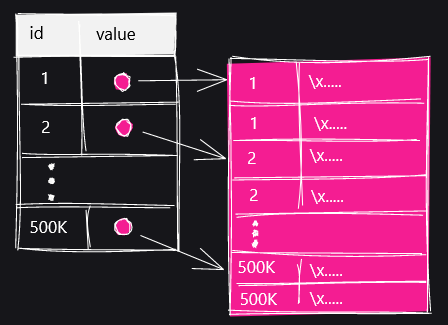
The device is a data division mechanism called 'TOAST'. When storing a large value in the column corresponding to TOAST, a new TOAST table drawn in pink will be created and the data will be divided into multiple rows and stored.
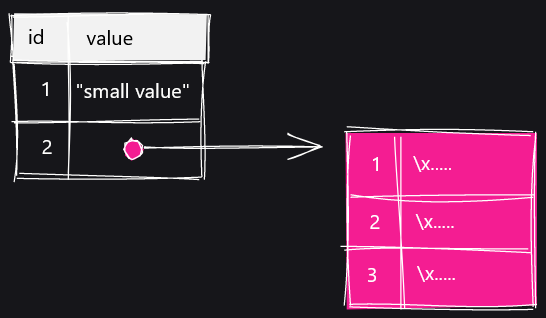
When the TOAST table is displayed with the SELECT statement, it looks like this. There are three columns, 'chunk_id', 'chund_seq' and 'chunk_data'.
Benita prepared the following three types of tables and measured the speed of reading a specific record from each table.
-Toast_test_small: A table that stores 500,000 lines of text that can be stored in the table as it is
-Toast_test_medium: A table that stores 500,000 rows of 'limit' size text that can be stored in the table as it is
-Toast_test_large: A table that stores 500,000 lines of text of a size that allows TOAST processing.
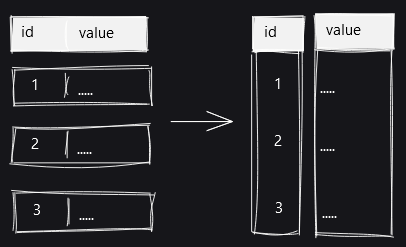
Visualizing each table with a diagram looks like this. In the toast_test_small table, the values are stored in the table as they are.
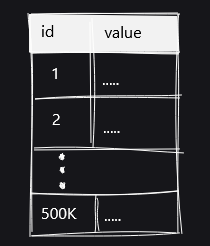
The toast_test_medium table is a state in which large text is stored in the original table without TOAST processing.

The toast_test_large table has a large text size and is toasted.
For these three tables, measure the execution speed of the following SQL statement that reads the record with a specific ID. It seems that the read speed of the toast_test_large table, which has the largest overall data size, is the slowest ...
[code] SELECT * FROM toast_test_medium WHERE id = 6000; [/ code]
As a result of the measurement, it was the toast_test_medium table that took the longest to read.
Below is a table summarizing each table size and TOAST table size. When PostgreSQL retrieves a particular record from a table, it scans the entire table. The toast_test_small and toast_test_large tables can be scanned in a short time due to the small size of the original table, but the toast_test_medium table has a large size of the original table, so it takes time to read the record. Benita explains that it will end up.

The previous SQL statement searched for the ID that exists in the original table, but if you execute the following SQL statement that needs to verify the values that exist in the TOAST table one by one ...
[code] SELECT * FROM toast_test_large WHERE value LIKE'foo%'; [/ code]
The reading speeds are arranged in order of text size.


If you often store 'halfway' size text, such as the toast_test_medium table, you can change the 'toast_tuple_target' parameter to lower the lower limit of the data size at which TOAST is performed, or split the table itself. You should do it. Also, in data warehouses that do not perform online transaction processing , it is said that storing data in columns instead of rows may improve the performance of scanning for specific columns.
Related Posts:





in Software, Posted by darkhorse_log