




ディープラーニングの手法「CNN」の画像識別処理がアニメーションで理解できる「CNN Explainer」
「AI」や「機械学習」といった言葉を耳にすることが増えていますが、その仕組みを理解するのは難しいと感じる人もいるはず。ジョージア工科大学のAIに関する研究チームであるPolo Clubが、機械学習の代表的なモデルである畳み込みニューラルネットワーク(CNN)を視覚的に理解できるウェブアプリ「CNN Explainer」を公開しています。
CNN Explainer
https://poloclub.github.io/cnn-explainer/
実際にCNN Explainerを操作しているムービーは以下。
Demo Video "CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization" - YouTube

CNNは機械学習における分類器のひとつで、ニューラルネットワークを用いて画像や動画などのデータのパターンを識別するために使用されるアルゴリズムです。CNNを理解するための基本的な構成要素は以下とのこと。
・テンソル:多次元配列のこと。CCNにおいては出力層以外では3次元の値です。
・ニューロン:複数の入力を取り込み、単一の出力を得ることができる機能のこと。
・層:同じハイパーパラメータを持ち、同じ動作をするニューロンの集合。ハイパーパラメータとは、あらかじめ人間が決めておくアルゴリズム内のパラメータのこと。
・カーネルの重みとバイアス:分類器モデルが提供された問題とデータセットに適応できるように、モデルの訓練段階で調整された、各ニューロンに固有の値。
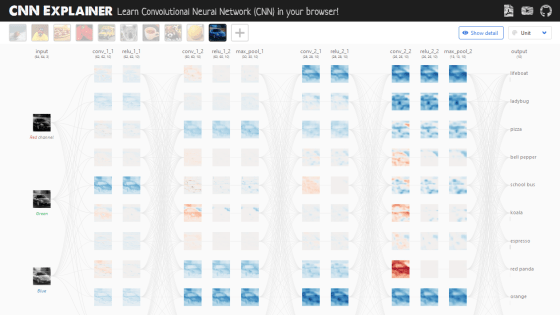
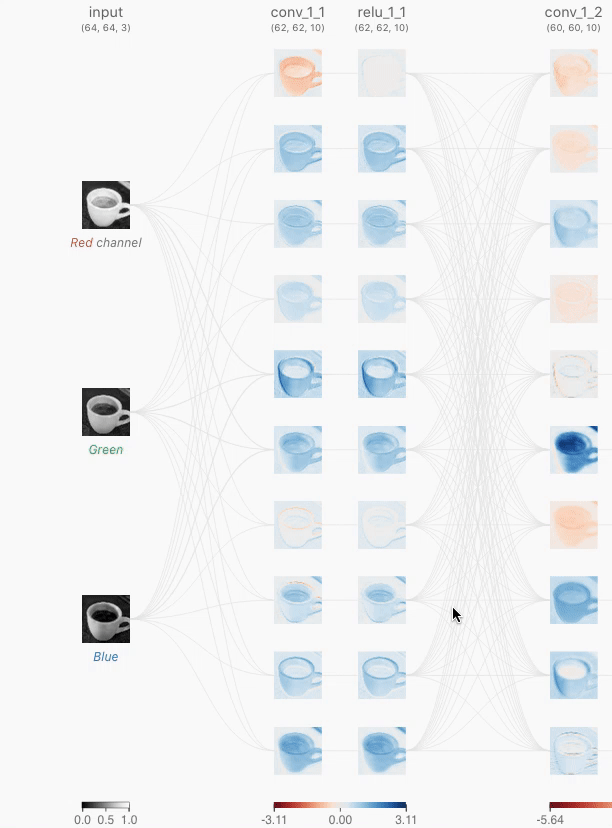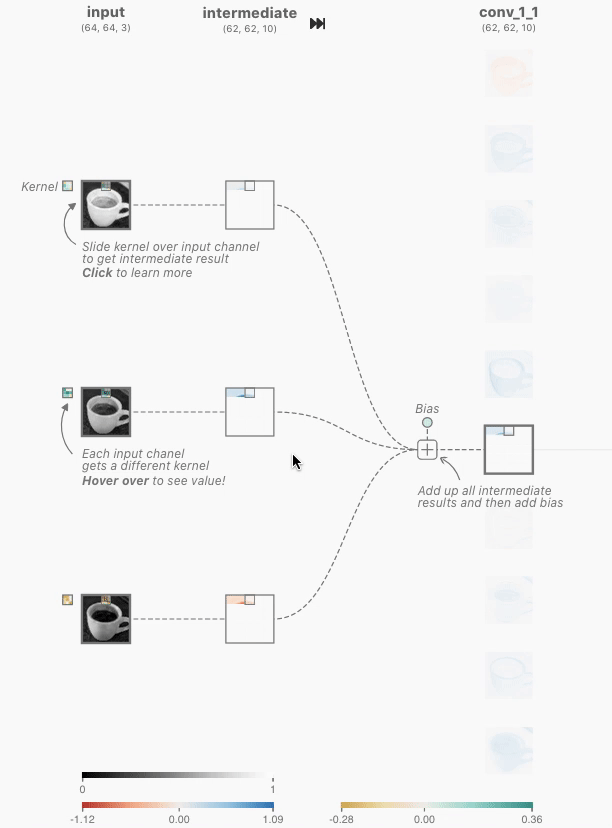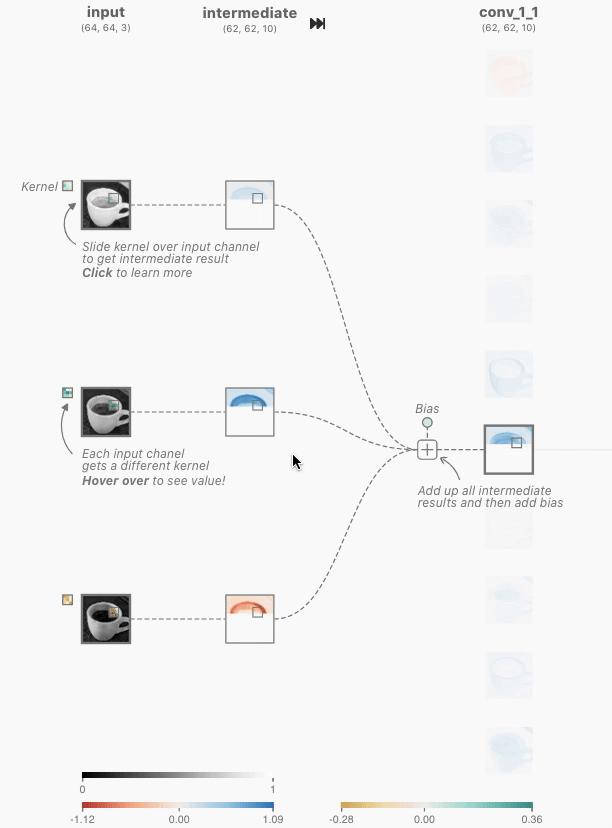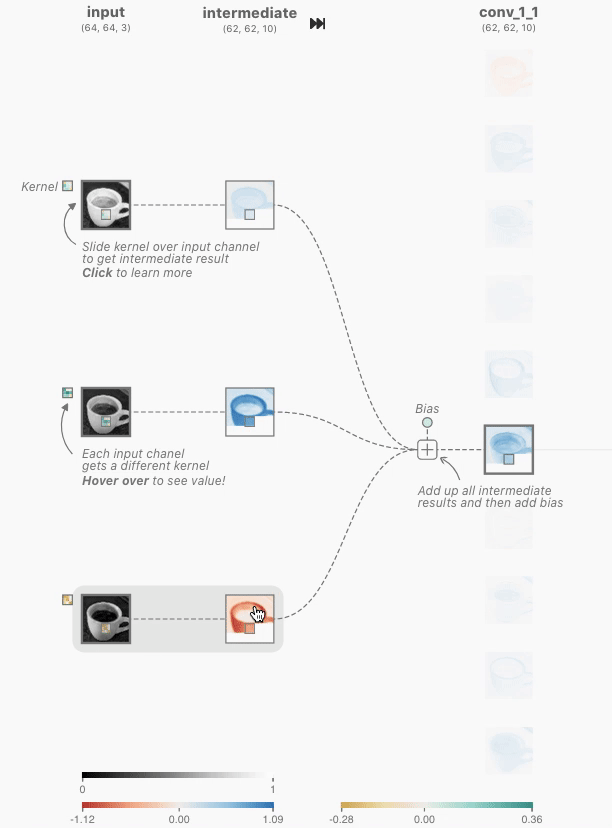
CNN Explainerのウェブサイトにアクセスすると、サンプル画像がCNNによって処理される様子を表した画面が表示されます。この画面を操作しながらCNNの動きを理解していくというわけです。
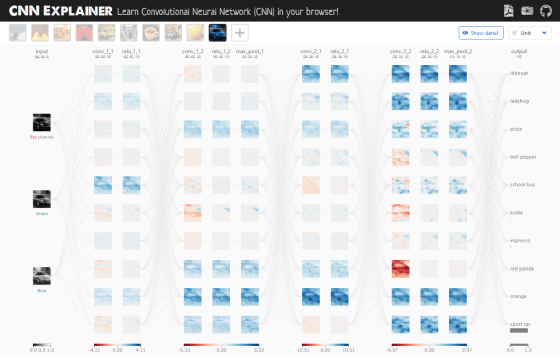
CNN Explainerでは、左から右へとCNNの処理が移っていくので、左端の処理がCNNにおける最初の処理ということになります。左端の入力層では、赤、緑、青の3つのチャネルに分類されたRGB画像が入力されています。

「conv_1_1」で表される層の画像のひとつをクリックすると……
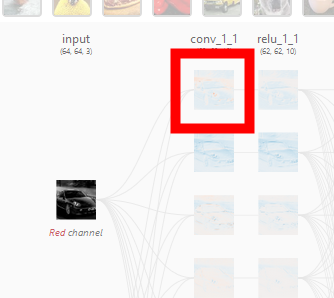
CNNにおける「畳み込み層」の処理がアニメーションとともに画面上に展開されました。さらに詳細を確認するため、赤枠部分をクリック。
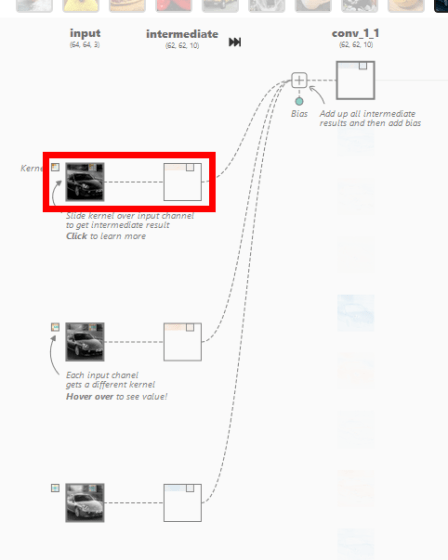
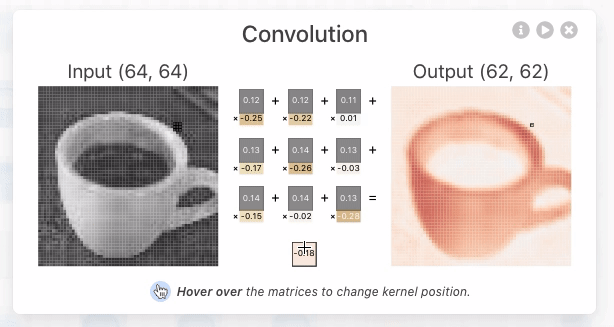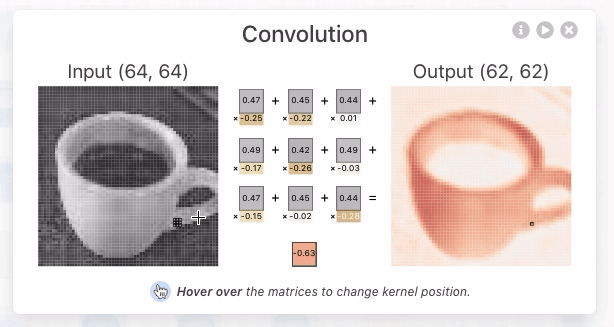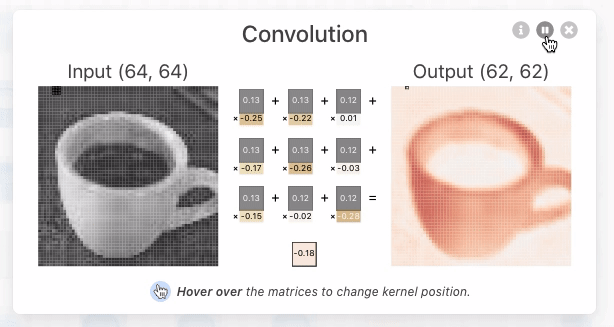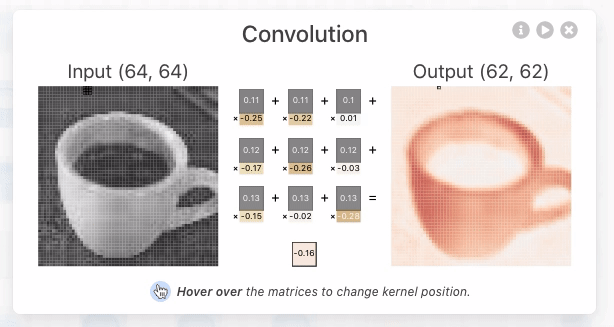
クリックすると、入力に対する出力と、その計算過程を示す画面が表示されました。CNNの畳み込み層では、カーネルと呼ばれるニューロン固有の値である多次元配列と、画像の一部分を表すカーネルと同じ大きさの多次元配列(ウィンドウ)について、各要素の積の和であるドット積を計算することで、そのウィンドウの特徴を抽出した数値を出力するとのこと。下の画像では、[-0.3, -0.21, 0.07;-0.19, 0.1, -0.01;-0.04, -0.02, 0.08]という3次元のカーネルと、[0.18, 0.17, 0.18; 0.7, 0.17, 0.16;0.16, 0.16, 0.16]で表される3次元のウィンドウとのドット積である「-0.09」というウィンドウの特徴を抽出した値を導いています。

さらに、カーネルは1ピクセルずつ移動し、対応するウィンドウの要素とのドット積を計算し続けていきます。この移動はストライドと呼ばれます。カーネルのストライドを経て、64×64ピクセルの画像データから62×62ピクセルの画像データが抽出されています。
上記の処理が赤、青、緑の入力に対してそれぞれ行われ、その中間結果がバイアスとともに合算されて2次元のテンソルが畳み込み層で出力されています。この出力は特徴マップと呼ばれ、同様の処理が畳み込み層の他のニューロンにおいても行われます。CNN Explainerでは、赤、青、緑に対応する3つの入力から10の特徴マップを出力しているので、カーネルは3×10=30種存在することになると説明されています。
カーネルの大きさやストライドするピクセル数は人間が設定を行うハイパーパラメータです。CNNのハイパーパラメータは主に3つあり、それぞれに説明が加えられています。
・パディング:カーネルが特徴マップを超えて移動できる空間のことで、精度向上につながるパラメータとのこと。対象の空間にゼロを設定するゼロパディングが一般的に用いられていると説明されています。

・カーネルの大きさ:カーネルの一辺の長さのこと。CNNの画像分類処理に大きな影響を与えるパラメータで、画像の種類やデータセットによって適切な値は異なるものの、一般的には小さい方がいいとのこと。

・ストライド:カーネルが一度に移動するピクセル数。ストライドが小さいと,より多くのデータが抽出されるので、より多くの特徴が学習され、出力のサイズも大きくなるとのこと。逆に、ストライドが大きくなると、特徴の抽出が制限され、出力のサイズ小さくなると説明されています。

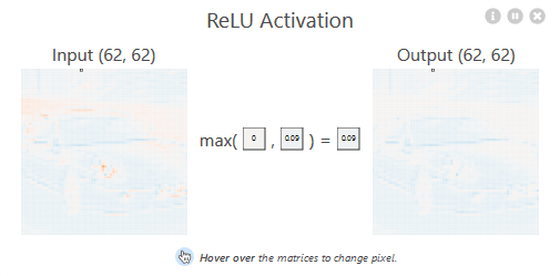
畳み込み層が出力した特徴マップは正規化線形関数(ReLU)を用いた「ReLU層」によって処理されます。

ReLUはCNNの精度を支える非線形活性化関数で、ReLUがなければCNNの性能は低下してしまうとのこと。ReLUは以下の数式およびグラフで表されます。つまり、入力値と0を比較し、大きい方の値を出力する関数です。

ReLU層の処理を詳しく確認するため、CNN Explainerの赤枠部分をクリック。

ReLU層の処理がポップアップで表示されました。畳み込み層で出力された特徴マップを入力として、それぞれの要素に対してReLU関数による計算が行われています。
CNN Explainerのモデルでは、それぞれ2つの畳み込み層とReLU層を通過した後、プーリング層による処理が行われています。プーリング層はネットワークの空間的な広がりを徐々に小さくし、ネットワークのパラメータや計算量を減らすという目的があるとのこと。

CNN Explainerにおけるプーリング層の詳細を確認するには赤枠部分をクリックします。

CNN ExplainerのプーリングタイプはMax-Poolingで、入力値におけるカーネル内の数値の最大値を計算し、カーネルをストライドして最大値の計算を繰り返していく処理が行われます。CNN Explainerでは、60×60のデータが30×30にまで小さくなっています。

CNN Explainerでは、上記の畳み込み層→ReLU層→プーリング層の処理をもう1セット行っています。

選択した画像の判別結果は右端の列で確認することができます。青いスポーツカーの画像を選択した場合は「sport car」の下にグレーのバーが表示されました。これは画像がスポーツカーである確率が高いと識別されていることを意味します。詳細を確認するには赤枠部分をクリックします。

これまで抽出してきた3次元の特徴マップを1次元の値に変換する「平滑化層」が表示されました。平滑化層は、CNNの最後の処理であるsoftmax関数で特徴マップを扱えるように変換する層です。

softmax関数の処理を表示するには「softmax」をクリックします。

softmax関数による計算を行う前は、各分類の確率を合計した値は1になっていません。softmax関数による計算は、CNNが出力した確率の和を1にするための処理です。

具体的な計算式は以下の通り。ある分類の確率をすべての分類の確率の和で除算した値です。

入力した画像が選択した分類に該当する確率は、分類をクリックするとその分類名の上に表示されています。

CNN ExplainerはGitHubでソースコードが公開されており、npmからインストールすることも可能。自分でCNN Explainerをホストした場合は、好きな画像をアップロードして分類することができます。
poloclub/cnn-explainer: Learning Convolutional Neural Networks with Interactive Visualization.
https://github.com/poloclub/cnn-explainer
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
「あまりにも危険過ぎる」と危険視された文章生成ツール「GPT-2」の技術で画像を自動で生成することに成功 - GIGAZINE
モザイク画像の解像度を64倍にして限りなく高品質の画像を生み出す技術が開発される - GIGAZINE
人工知能(AI)は意識を持つようになるのか?を神経科学者が解説 - GIGAZINE
・関連コンテンツ






in ソフトウェア, レビュー, ウェブアプリ, Posted by darkhorse_log
You can read the machine translated English article 'CNN Explainer' that can understand the ….