




IntelがIce Lake世代のCPUに施した「目立たないパワーアップ」とは?

IntelとAMDのCPUを比較して「AMDが買い」と結論づける報告も上がるほど、IntelのCPU市場における存在感は弱くなっていますが、IntelもCPUの改善を地道に行っているようです。エンジニアのTravis Downs氏が、Intelの最新世代「Ice Lake」のCPUには、キャッシュの処理において改善が施されていると自身のブログで報告しています。
Ice Lake Store Elimination | Performance Matters
https://travisdowns.github.io/blog/2020/05/18/icelake-zero-opt.html
Hardware Store Elimination | Performance Matters
https://travisdowns.github.io/blog/2020/05/13/intel-zero-opt.html#hardware-survey
今回Downs氏が注目したのは、CPUの命令セットのひとつである「Intel AVX」の実行速度。Intel AVXはSandy Bridge世代から搭載されている命令セットで、AVX、AVX2、AVX-512の3世代が存在します。主に画像処理や動画のエンコードに利用されており、ニューラルネットワークに採用される命令セットも支えている技術です。
AVXの性能をテストするため、Downs氏が用意したC++のコードがこれ。メモリを特定の値であるvalで埋めるコードです。
std::fill(buf, buf + size, val);
このC++のコードをコンパイルして出力されたアセンブリ言語の一部を抜粋したものが以下。なお、コンパイラにはGCC 9.2.1を使用しているとのこと。
.L4: vmovdqu YMMWORD PTR [rax + 0], ymm1 vmovdqu YMMWORD PTR [rax + 32], ymm1 vmovdqu YMMWORD PTR [rax + 64], ymm1 vmovdqu YMMWORD PTR [rax + 96], ymm1 vmovdqu YMMWORD PTR [rax + 128], ymm1 vmovdqu YMMWORD PTR [rax + 160], ymm1 vmovdqu YMMWORD PTR [rax + 192], ymm1 vmovdqu YMMWORD PTR [rax + 224], ymm1 add rax, 256 cmp rax, r9 jne .L4
AVX2におけるロードおよびストアを行う命令である「vmovdqu」が利用されており、32バイトを1単位として、「ymm1」レジスタの値をメモリに書き込んでいます。このとき、メモリのアドレスは汎用レジスタ「rax」の値を用いて表現されています。
vmovdqu YMMWORD PTR [rax + 0], ymm1
このようにメモリのアドレスを32バイトずつずらしながら、処理を実行しているというわけ。
vmovdqu YMMWORD PTR [rax + 0], ymm1 vmovdqu YMMWORD PTR [rax + 32], ymm1 vmovdqu YMMWORD PTR [rax + 64], ymm1
メモリの256バイト分の領域を値で埋めることができたら、汎用レジスタの値に256を追加し、次のループに備えています。
vmovdqu YMMWORD PTR [rax + 224], ymm1 add rax, 256
Sky Lake世代のCore i7 6700HQを用いて先ほどのプログラムを実行し、メモリを埋める値を「0」にした場合と「1」にした場合の書き込み速度をグラフに表すとこんな感じ。L1キャッシュに収まるサイズのデータを入力した場合は高速ですが、データのサイズが大きくなり、L2キャッシュ、L3キャッシュ、RAMへとあふれるにつれ、書き込み速度も低下していることがわかります。
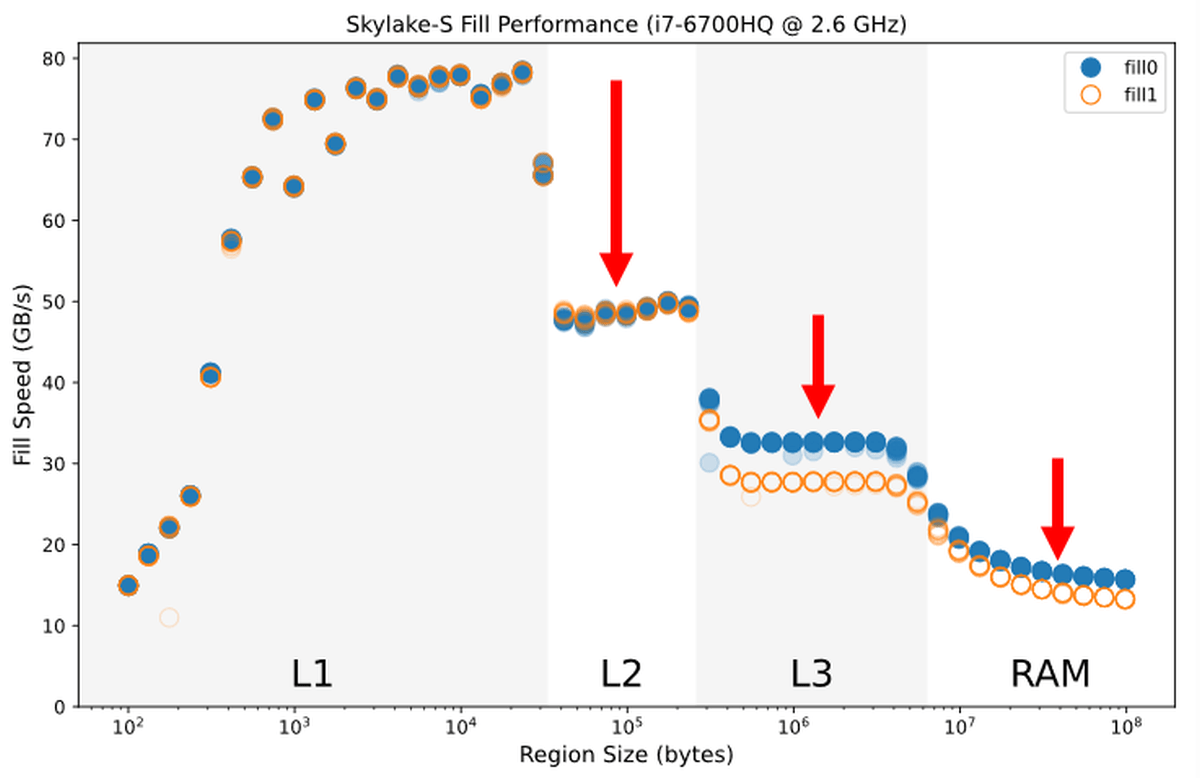
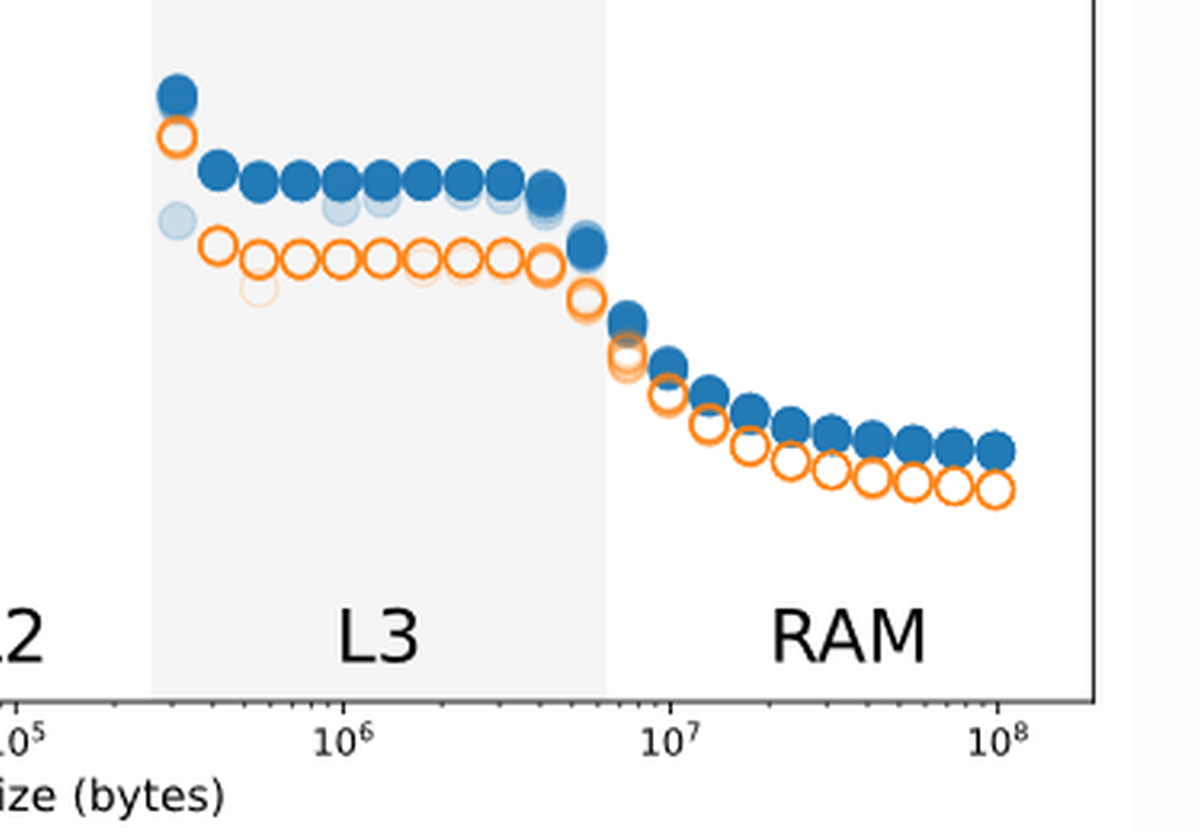
また、L3キャッシュとRAMを使用するサイズのデータにおいては、0を書き込んだ場合と1を書き込んだ場合とで速度に差が表れています。これについてDowns氏は「0を書き込む場合、L2キャッシュからあふれたデータをL3キャッシュに書き込んだり、L3キャッシュからRAMにデータを書き込んだりする操作において、パフォーマンス最適化が行われているため、書込み速度がやや上がる」と説明しています。
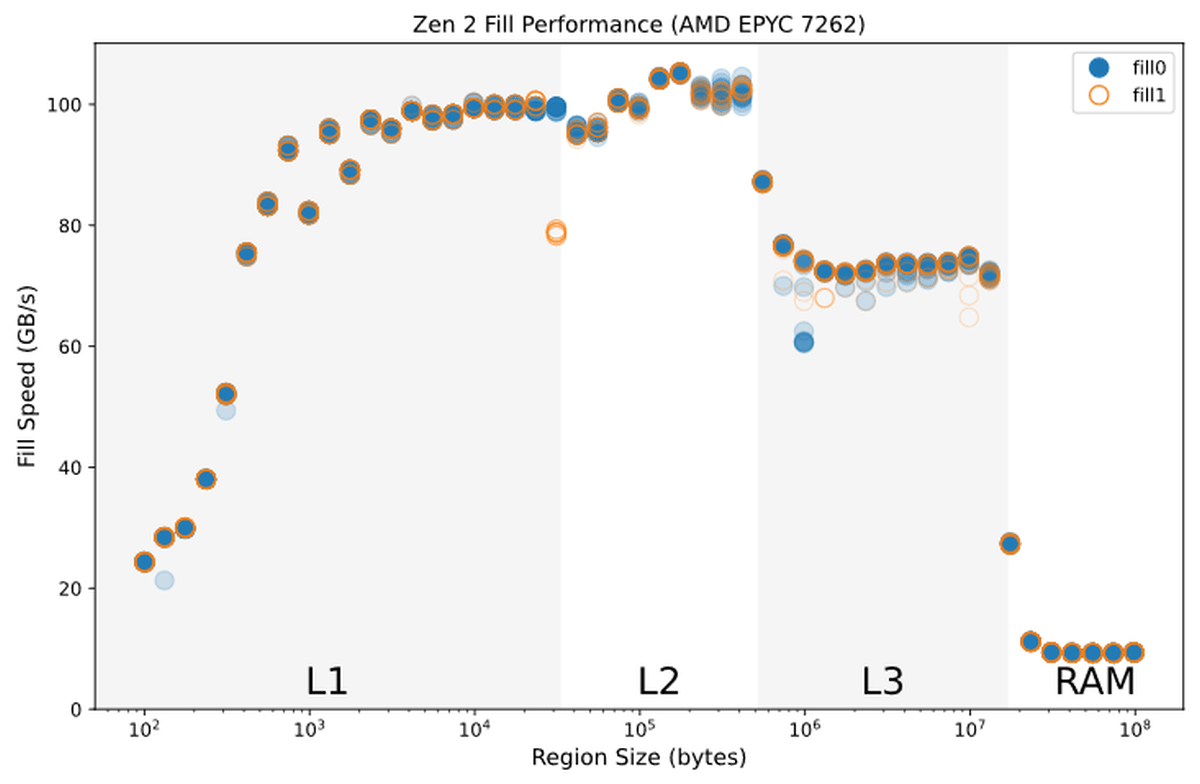
こうしたパフォーマンスの最適化は、AMDのZen 2アーキテクチャを採用したEPYCなど、他のCPUでは確認できません。
以下のグラフが、L3キャッシュやRAMから読み込んだデータがL2キャッシュからあふれ、L3キャッシュやRAMに書き込まれることなく廃棄される「Silent」状態となったキャッシュと、L2キャッシュからあふれてL3キャッシュやRAMへ再度書き込まれる「Non Silent」状態となったキャッシュの割合を折れ線グラフで示し、先ほどの書き込み速度グラフに重ねたもの。
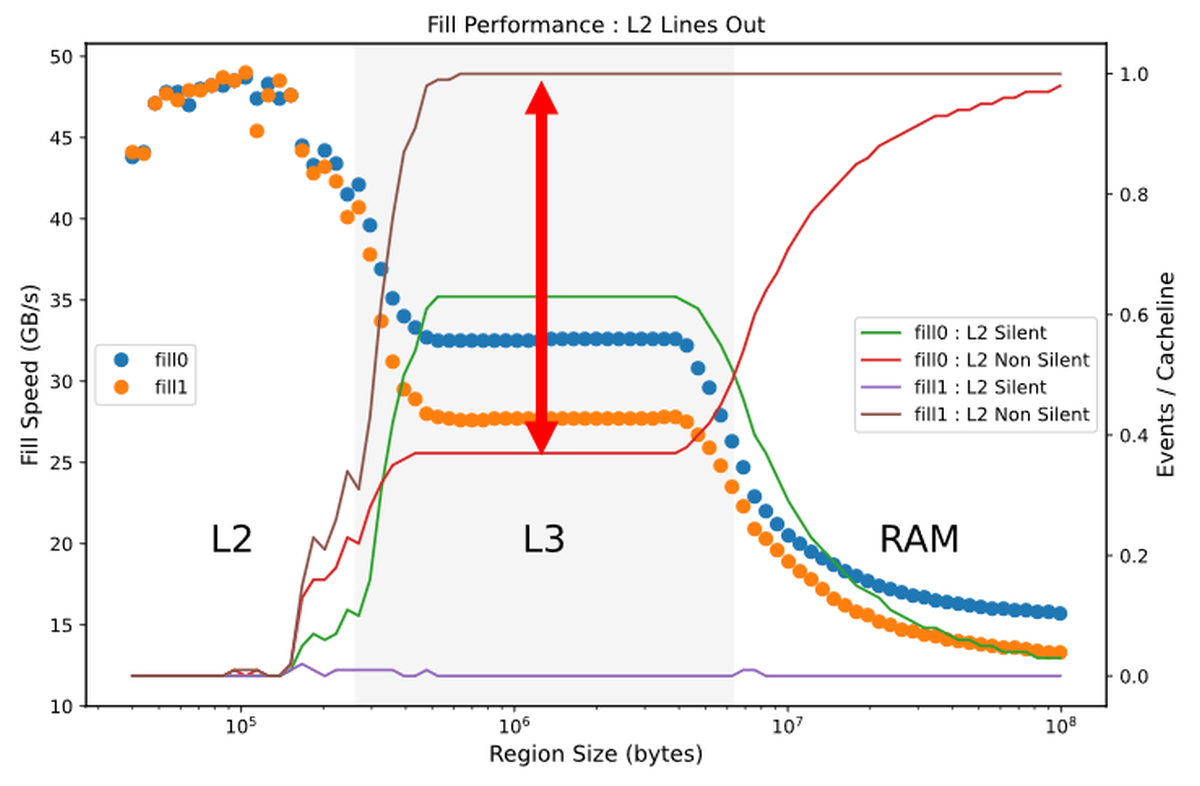
L3キャッシュに収まるデータを書き込んだ場合に注目すると、0を書き込む場合は、緑の「Silent」状態のキャッシュが64%、赤の「Non Silent」状態のキャッシュが36%であるのに対し、1を書き込む場合は茶色の「Non Silent」状態のキャッシュがほぼ100%を占めています。つまり、1を書き込む場合は「無駄な書き込み直し」が多数発生しているのに対し、0を書き込む場合は矢印の分だけ、そうした無駄が排除されています。これがDowns氏が説明する「パフォーマンスの最適化」とのこと。
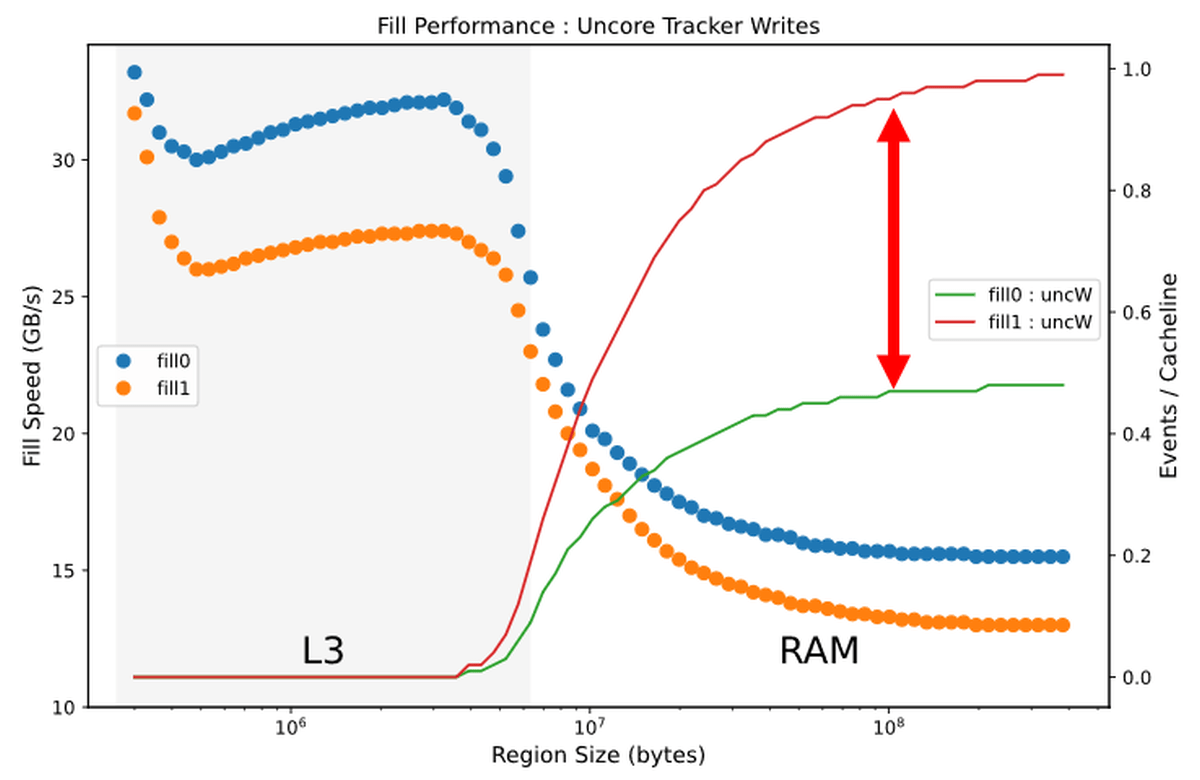
こうした最適化はL3キャッシュからRAMへデータを書き込む際にも行われているとのこと。RAMからL3キャッシュへ読み込んだ際に、L3キャッシュからあふれてしまったデータを再度RAMへ書き込む「UnCore」なキャッシュの割合を折れ線グラフで表現し、書き込み速度に重ねるとこんな感じ。0で書き込む場合の割合は緑色の線で表されており、赤色の1で書き込む場合の割合と比較して、およそ半分しか無駄な書き込みが発生していないことがわかります。こうした最適化が0においてのみ行われている理由について、Downs氏は「0を0で上書きするのは、冗長な操作の中でも最も発生頻度が高いものであり、書き込み先が0かどうかの判別も容易だからではないか」と説明しています。
Downs氏によると、こうしたCPUの最適化はIce Lakeにおいてさらに進んでいるとのこと。Ice Lake世代のCore i5 1035G4でのベンチマーク結果を見てみると、L2キャッシュからL3キャッシュにデータを書き込む際の「Non Silent」状態のキャッシュの割合は10%を切っています。
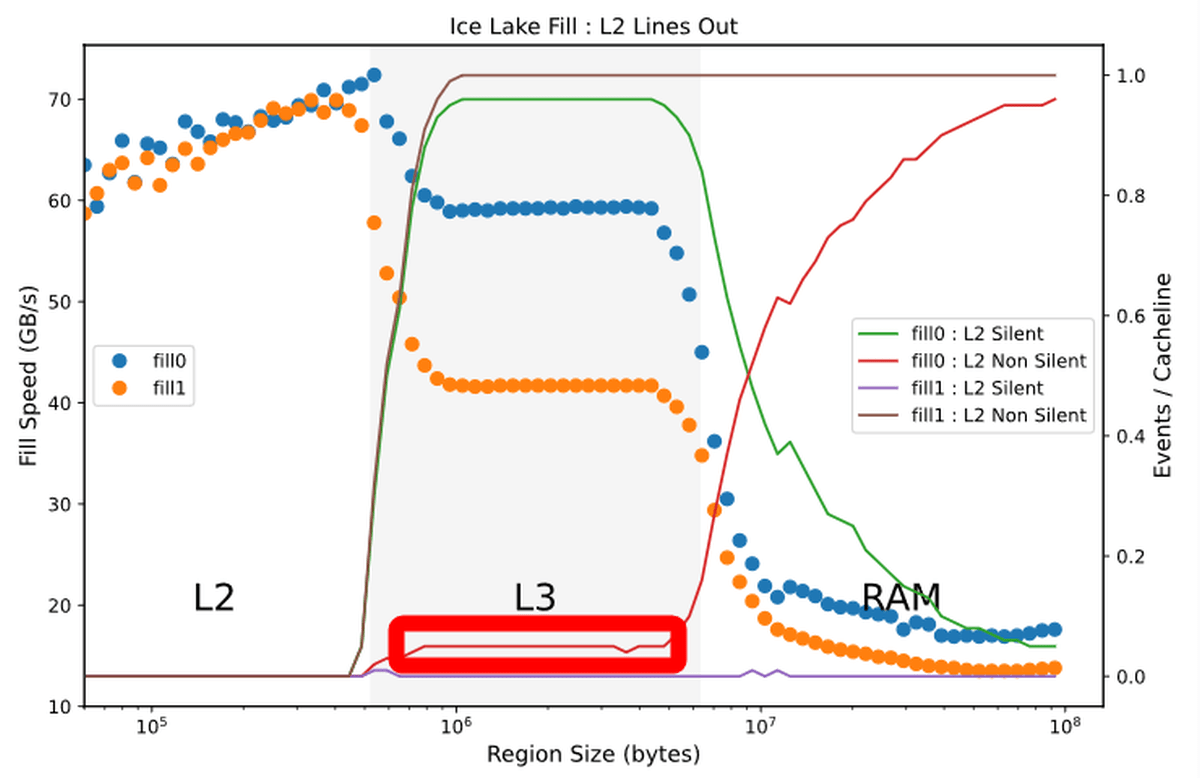
Sky Lake世代の結果を再掲すると、「Non Silent」状態のキャッシュは36%を占めており、Ice Lake世代では0による書き込み速度が向上していることがわかります。
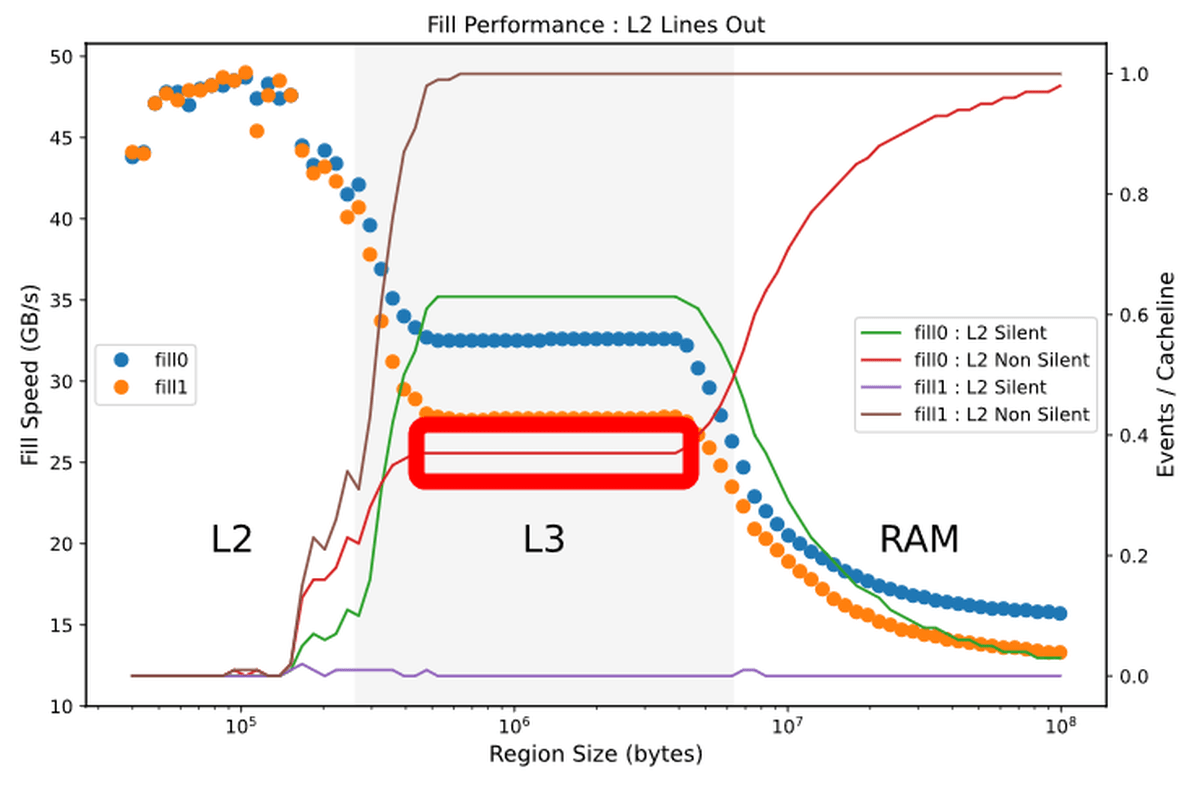
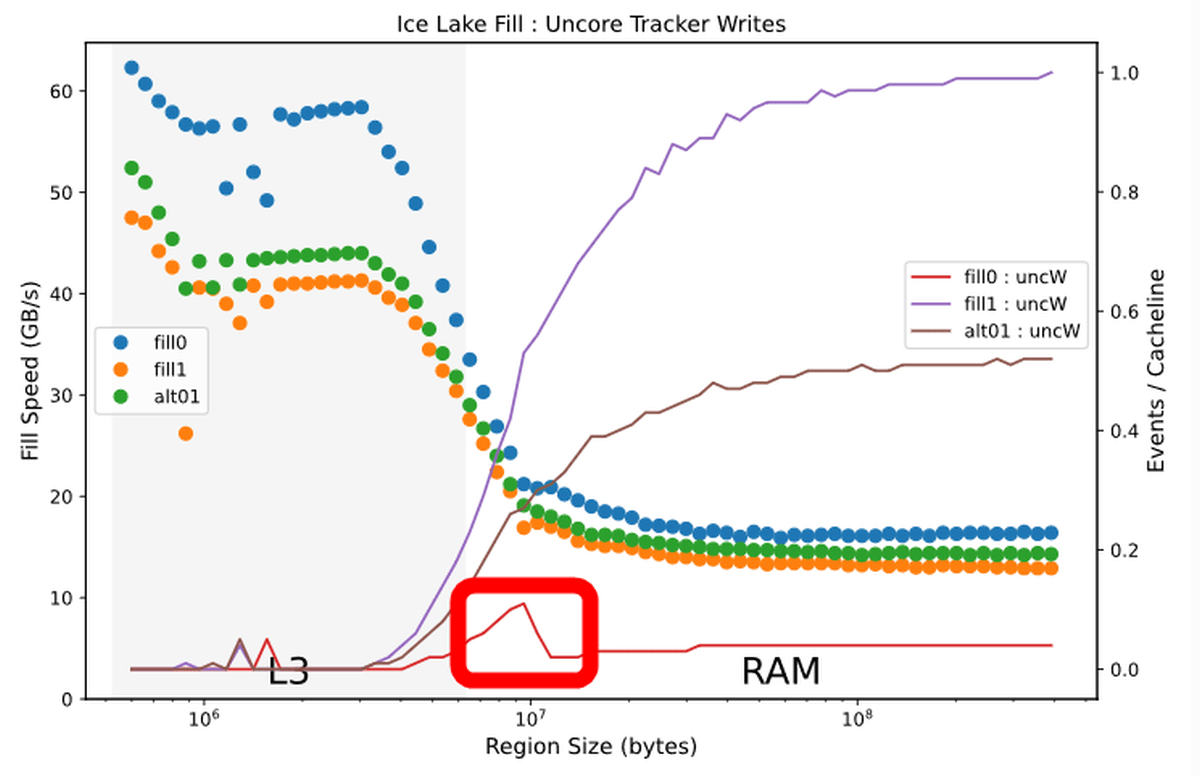
L3キャッシュからRAMへデータを再書き込みする「UnCore」なキャッシュの割合についても、0での書き込みの場合は再書き込みの割合がかなり減っていることがわかります。
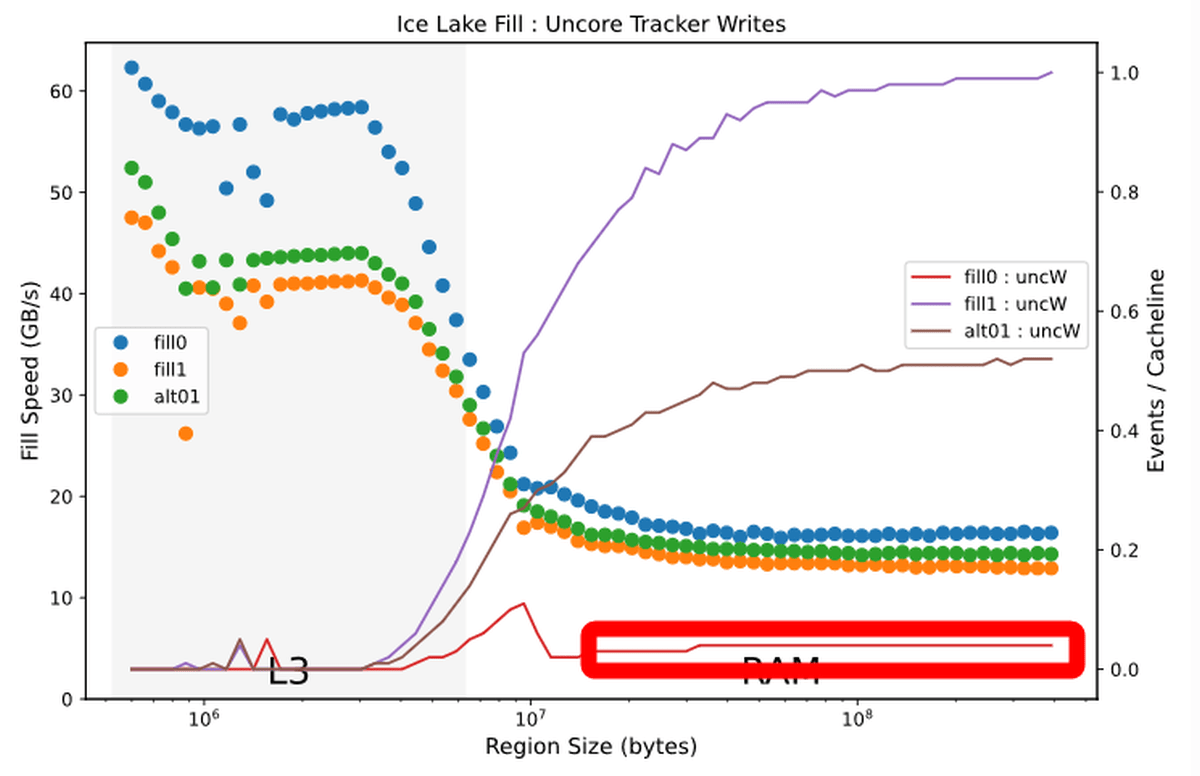
Sky Lake世代の「UnCore」なキャッシュの割合を示したグラフと比較すると、その差がよくわかります。
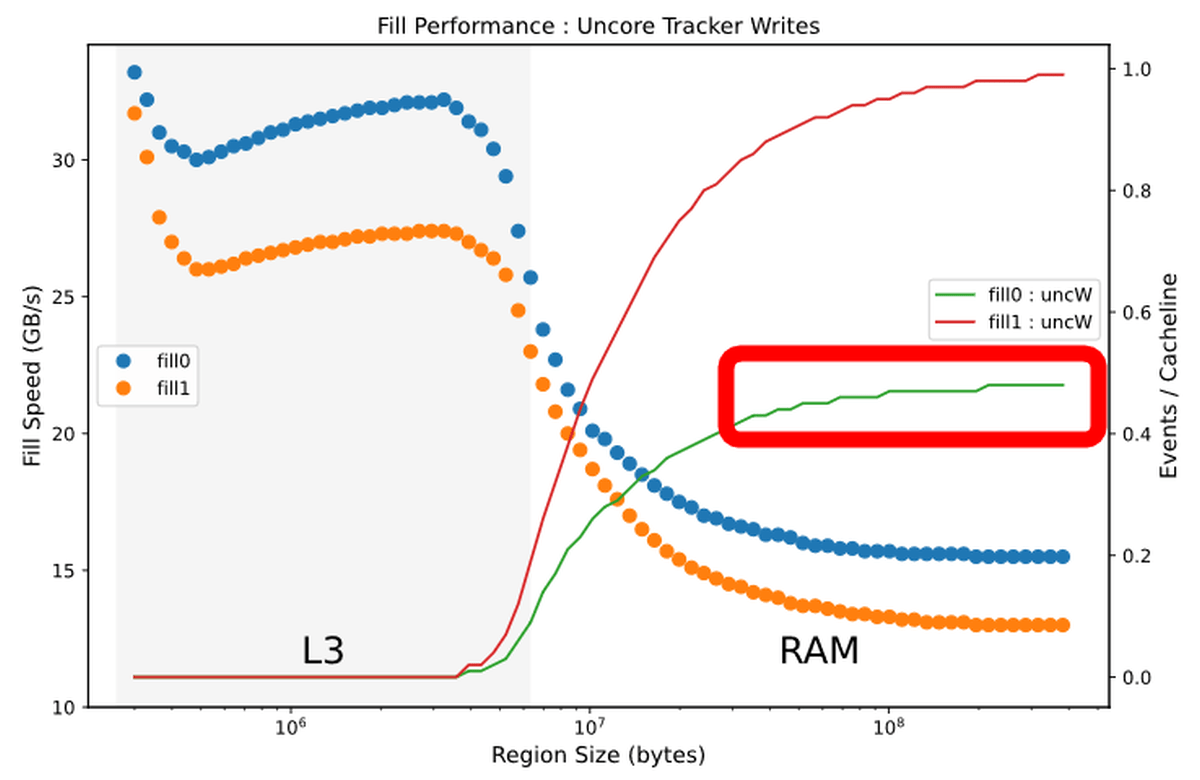
また、書き込むデータ容量がL3キャッシュからRAMにあふれる境界付近で、0による書き込み回数に小さな山がある点について「ここで何か最適化の仕組みが作用しているのだろう」とDowns氏はコメント。
また、Downs氏はIce Lake世代のCPUでAVX2とAVX-512の性能の比較も行っています。先ほどのプログラムをコンパイルする際にアーキテクチャとして「-march=icelake-client」を指定すると、AVX2命令セットが使用されます。
.L4: vmovdqu32 [rax], ymm0 vmovdqu32 [rax+32], ymm0 vmovdqu32 [rax+64], ymm0 vmovdqu32 [rax+96], ymm0 vmovdqu32 [rax+128], ymm0 vmovdqu32 [rax+160], ymm0 vmovdqu32 [rax+192], ymm0 vmovdqu32 [rax+224], ymm0 add rax, 256 cmp rax, r9 jne .L4
対して、アーキテクチャとして「-march=native」を指定しコンパイルすると、zmmレジスタを用いたAVX-512命令セットが使用されるとのこと。AVX-512のプログラムでは、1回のループで512バイトの書き込みを行っています。
.L4: vmovdqu32 [rax], zmm0 add rax, 512 vmovdqu32 [rax-448], zmm0 vmovdqu32 [rax-384], zmm0 vmovdqu32 [rax-320], zmm0 vmovdqu32 [rax-256], zmm0 vmovdqu32 [rax-192], zmm0 vmovdqu32 [rax-128], zmm0 vmovdqu32 [rax-64], zmm0 cmp rax, r9 jne .L4
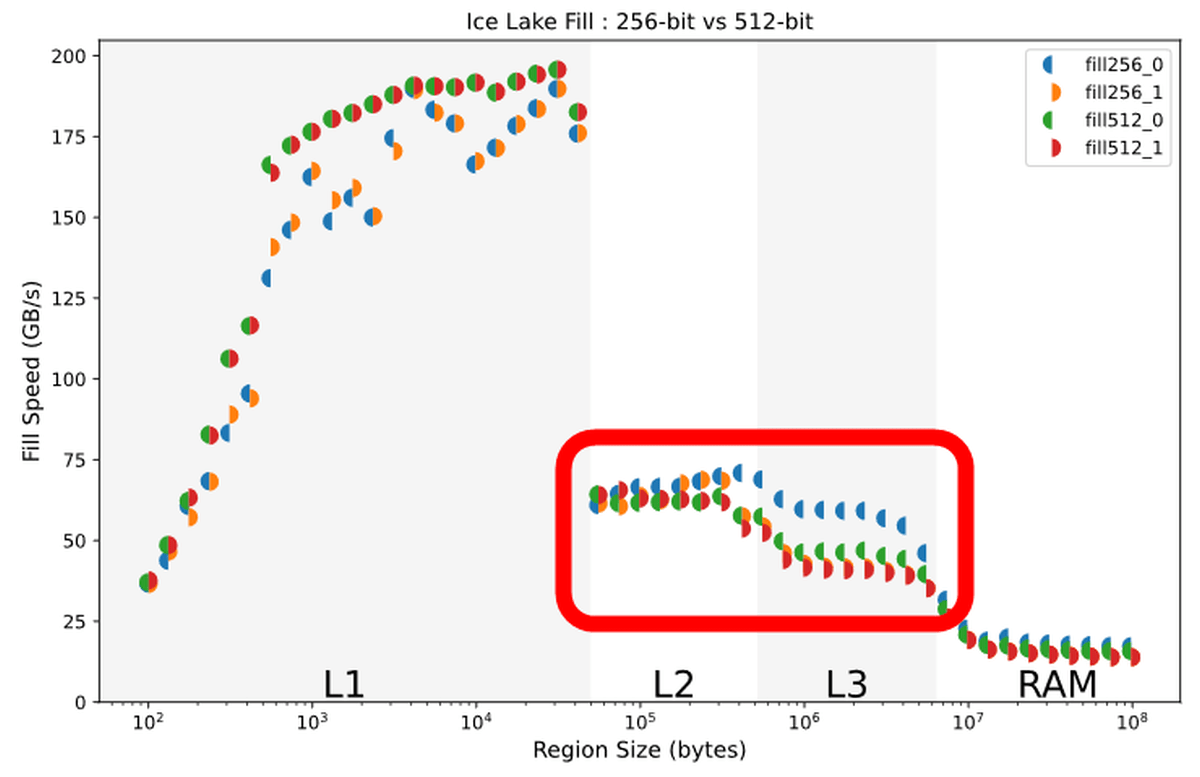
AVX2とAVX-512の命令セットによる書き込み速度を、0を書き込む場合と1を書き込む場合でそれぞれ比較すると、L1キャッシュに収まるデータの場合は、AVX-512命令セットが0による書き込み、1による書き込みのどちらにおいても優勢です。

しかし、L2キャッシュ以降の記憶装置を使用する大きさのデータを書き込んだ場合は、青い半円で表されるAVX2の0による書き込み速度が頭ひとつ抜けていることがわかります。
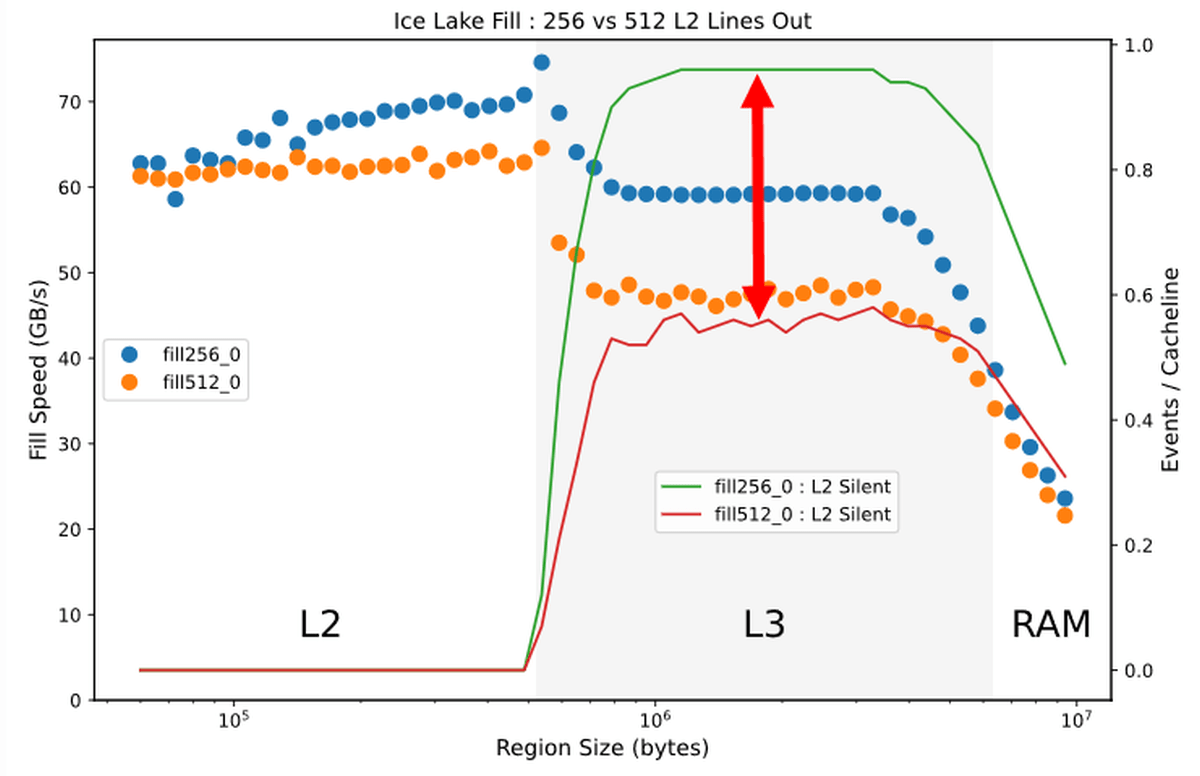
L2、L3キャッシュにおける0による書き込みのみに注目してみると、「Silent」状態のキャッシュの割合はAVX2(緑線)の方が高く、キャッシュが効率的に破棄されて最適化がより進んでいることが見て取れます。この理由についてDowns氏は「複雑でわからない」とコメント。
Downs氏は結論として、Sky Lake世代において確認できた0による書き込みの最適化は、Ice Lake世代でも健在であり、そのパフォーマンスはおよそ2倍になっていると説明。また、Ice Lake世代においては、L1キャッシュのサイズ以上の0による書き込みが発生した場合は、AVX2のほうがAVX-512よりも優れていると語っています。
・関連記事
Microsoftが秘密裏に独自命令セットのCPU「E2」を開発、Windows 10とLinuxの動作をテスト中 - GIGAZINE
RISC-Vによる新しいプロセッサの開発が難しいのはなぜなのか? - GIGAZINE
IBMが自社製CPU「PowerPC」のアーキテクチャをオープンソース化した背景とは? - GIGAZINE
ついにIntelが10nmプロセス製品「Ice Lake」&「Lakefield」の量産に目途をつける - GIGAZINE
Zen2採用の第3世代Ryzen発表、Intel最上位モデルを性能で上回りワットパフォーマンスでは圧倒 - GIGAZINE
・関連コンテンツ








in ハードウェア, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What is 'conspicuous power-up' that Inte….