




フェイクニュースと戦うインターネットアーカイブの取り組みと問題

By aqrstudio
さまざまなデジタル情報をアーカイブするインターネットアーカイブで行われる「過去の情報をアーカイブする上でフェイクニュースに対抗するための取り組み」や「急速に増えるインターネットコンテンツに対する問題」について、インターネットアーカイブの創設者であるブリュースター・ケール氏が語っています。
How the Internet Archive is waging war on misinformation | Financial Times
https://www.ft.com/content/5be1f2ee-d60b-11e9-a0bd-ab8ec6435630
1996年に設立されたインターネットアーカイブは、ウェイバックマシンと呼ばれる、特定のURLの変更・削除に関係なく、ユーザーがアーカイブされた時点でのURLの内容を確認できるウェブページの無料リポジトリを使用し、ウェブページ、ソフトウェアや映画・録音データなどの情報を収集してデジタル化した資料を無償で提供する非営利団体です。
2016年のアメリカの選挙以来、フェイクニュースに対する懸念が強まっているため、インターネットアーカイブはフェイクニュースへの対策を強化しています。偽の超党派的なコンテンツが拡散されるなど、絶えずソーシャルメディアが更新される時代に、誰がいつ何を言ったかを変更不可能なデータとして保存しておくことが重要視されています。
以下の画像は、ウェイバックマシンによりインターネットアーカイブから取得した、リーマン・ショックの始まりとなるリーマンブラザーズが破産を申請した2008年9月15日のFT.comのスクリーンショットです。
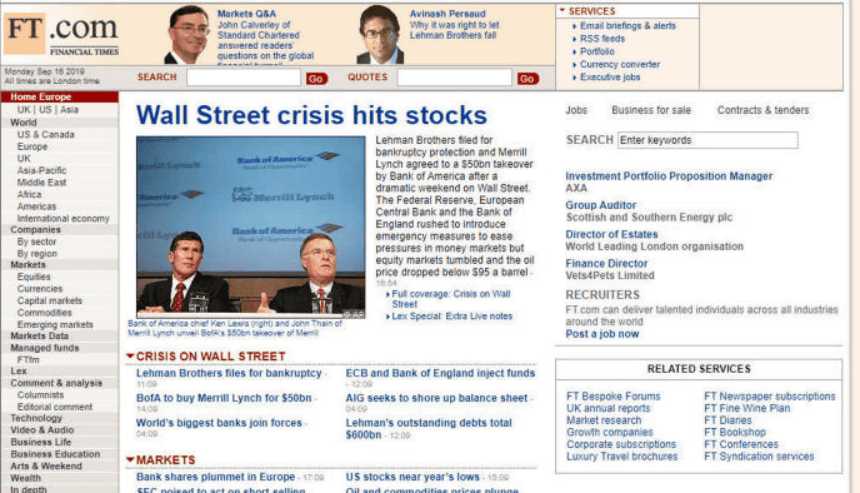
ケール氏はインターネットアーカイブで現在100人以上のスタッフを雇用しています。1年に約1800万ドルの費用がかかっており、寄付・助成金・特定のデジタル化サービスを要求する第三者からの資金提供により成り立っています。
これまでインターネットアーカイブは330億のウェブページ、2000万本の書籍とテキスト、850万のオーディオと映像の記録、300万の画像、20万のソフトウェアプログラムをアーカイブしています。一部の情報は無料でアクセスでき、著作権法が適用される場合は貸し出し、研究者のみが利用できるコンテンツもあります。
ケール氏はフェイクニュースによる影響で、一般の人々が信頼できる情報を得ることがどれほど難しくなったかを嘆いており「PCを介してアクセスできる情報なしで、PCを扱える世代を育てたい」とケール氏は語っています。
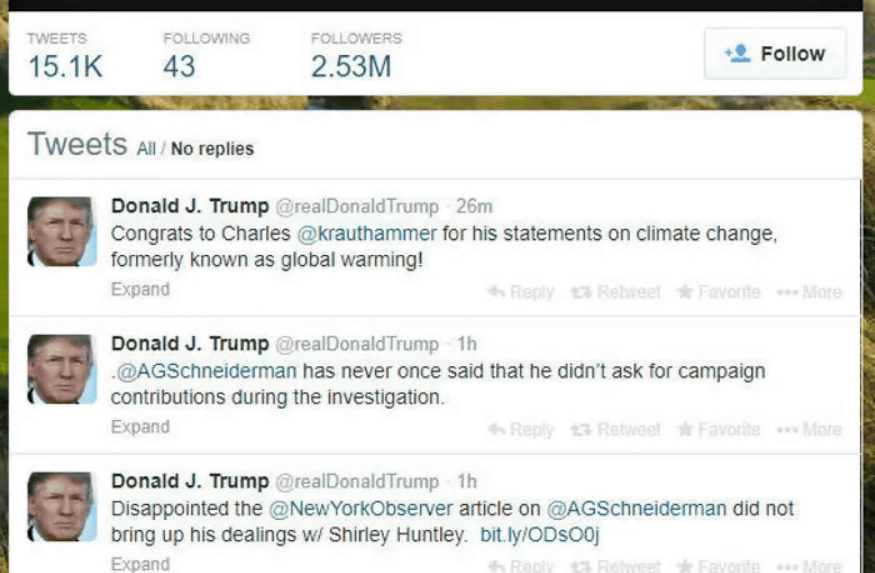
ドナルド・トランプが大統領に就任した選挙の後、有権者を動揺させようとする偽情報の存在が浮き彫りになったため、インターネットアーカイブは新しいプロジェクトを開始しました。そのうちの1つが「トランプアーカイブ」でした。トランプアーカイブとは、トランプ大統領就任前を含め、約6000を超える大統領のテレビ出演などの映像を集めたものです。さらに大統領のしばしば矛盾する声明を文書化する一環として、Twitterでのトランプ氏の投稿も収集しています。
以下はウェイバックマシンでキャプチャされたトランプ氏によるツイート。
ウェイバックマシンのディレクターであるマーク・グラハム氏は、ソーシャルメディアは「非常に重要なコミュニケーションプラットフォームです」と述べており、Facebookなどのニュースフィードやチャットアプリは、多くの人が情報を得る「最も有力な方法」であると言います。
インターネットアーカイブは、誤った情報を識別し、疑わしいコンテンツの事実確認に役立てられることを望んでいます。映像のライブラリは、専門家やアルゴリズムによって改ざんされたり、文脈から外れた映像を発見するのに役立ちます。しかしフェイクニュースにどう対処すべきかを決定することは難しく、インターネットアーカイブに対処の義務はありません。特定の研究者や政治家にとっては、誤った情報から調査できることもあるため、グラハム氏は「単に誤った情報や不快なコンテンツを削除することは必ずしも正解とは言えない」と主張しています。
過去20年間のインターネットの爆発的な成長を考えると、インターネットをアーカイブする作業はますます困難になっています。ケール氏は、少なくとも人気のあるウェブサイトをアーカイブすることで、インターネットアーカイブが役立つことを望んでいますが、グラハム氏は、ケール氏を「楽観主義者」であると述べており、アーカイブは期待されるほど情報を保存できていないと述べました。YouTubeを例にとると、毎週公開されるビデオの「ほんの一部」のみがアーカイブされている現状です。
インターネットアーカイブは約3000の異なる「クローラー」と呼ばれるアルゴリズムを使用しており、ウェイバックマシンに保存されているウェブページの定期的なスナップショットを取得しています。取得されたスナップショットは、ローカルな政治的ウェブサイトなど、広い範囲を網羅しています。
アーカイブは、もともと教会の身廊であった場所に置かれたサーバーに保存されています。また、別の場所に完全なバックアップコピーが設けられ、データ消失の予防策としてカナダ、オランダ、エジプトのアレクサンドリアには部分的なコピーが置かれています。
サンフランシスコを拠点としているインターネットアーカイブは、同じくサンフランシスコに位置するシリコンバレーの企業との共通点はひとつもないとケール氏は語ります。シリコンバレーには数10億人に利用されるプラットフォームを運営する少数の経営陣が存在する一方で大きな貧富の格差が問題となっており、ケール氏は、シリコンバレーにある企業のように少数の人間が利益を得るのではなく「インターネットアーカイブによるすべてのテクノロジーの遺産」で多くの人が利益を得ることを望んでいます。
・関連記事
Myspaceの喪失データのうち約50万件の音楽ファイルが学術グループにより復活 - GIGAZINE
Google+が終了する前に投稿をインターネットアーカイブに保存しようという試み - GIGAZINE
インターネット上のあらゆる情報を記録・保存する「インターネット・アーカイブ」はどのように運営されているのか? - GIGAZINE
Wikipediaの客観性は数百万ものリンク切れURLを修復するインターネット・アーカイブによって確保されている - GIGAZINE
億万長者からの圧力でニュース記事や文書を葬られないよう保存する「Archive-It」とは? - GIGAZINE
・関連コンテンツ








in ネットサービス, Posted by darkhorse_log
You can read the machine translated English article Internet archive efforts and problems fi….