




無料で自分のPCで動かせるローカルAIモデルがわかる「LLM Checker」
「LLM Checker」は自分のPCのハードウェアをスキャンしローカルで実行可能なLLMを推薦してくれるCLIツールであり、Ollamaと完全に統合されていることを特徴としています。
Pavelevich/llm-checker: Advanced CLI tool that scans your hardware and tells you exactly which LLM or sLLM models you can run locally, with full Ollama integration.
https://github.com/Pavelevich/llm-checker
◆特徴
公式GitHubによるとLLM Checkerの特徴は以下の通りです。
・同期済みのOllama SQLiteカタログが200以上同梱されており、必要に応じてOllamaから更新可能
・4Dスコアリングエンジンによりユースケースに応じて品質・スピード・適合性・コンテキストを適切に重みづけ可能
・ハードウェア検出:GPU(Apple Silicon・NVIDIA CUDA・AMD ROCm・Intel Arc)およびCPU・RAM・アクセラレーションバックエンド
・パラメータあたりのバイト数計算式を実際のOllamaサイズと比較してメモリ使用量を予測
・Node.js 16以降で動作可能なピュアJavaScript
・モデル出力とともにトークン/秒単位のAI実行速度をライブ表示
また、同様のツールにllmfitがありますが両者は方向性に違いがあります。
| ツール | 主なフォーカス | 典型的アウトプット |
|---|---|---|
| LLM Checker | ローカル推論のためのハードウェア対応モデル選択 | ランキング形式のおすすめ・互換性スコア・Ollama pull/runコマンド |
| llmfit | LLMのワークフロー支援とモデル適合評価 | 様々な最適化ワークフロー・選択ヒューリスティック |
公式GitHubの見解によると、「今このマシンで何を動かすべきか」をゴールとするのであればまずはLLM Checkerを使用するのがおすすめであり、より手広く実験したいのであれば両方のツールを使うことで相乗効果を期待できるとのこと。
◆導入
今回はWindows PCのWSL(Ubuntu)上でLLM Checkerを動かします。LLM CheckerはNode.jsに依存しているためあらかじめNode.js(v16以降)およびnpmがインストールされている必要があります。インストールされているNode.jsやnpmのバージョンを確認するにはターミナルで以下のコマンドを実行します。
# Node.jsのバージョンを確認する:
node -v
# npmのバージョンを確認する:
npm -v
上記コマンドでバージョンが表示されずエラーになる場合はインストールする必要があります。インストールにあたりcurlコマンドが必要となるので先にインストールします。
sudo apt update
sudo apt install -y curl
続いて以下のコマンドを実行すると記事作成時点で最新のNode.js・npmをインストールします。
# nvmをダウンロードしてインストールする
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.4/install.sh | bash
\. "$HOME/.nvm/nvm.sh"
# Node.jsをダウンロードしてインストールする
nvm install 24
LLM Checkerのインストール自体は以下のコマンドを実行します。
npm install -g llm-checker
◆使ってみる
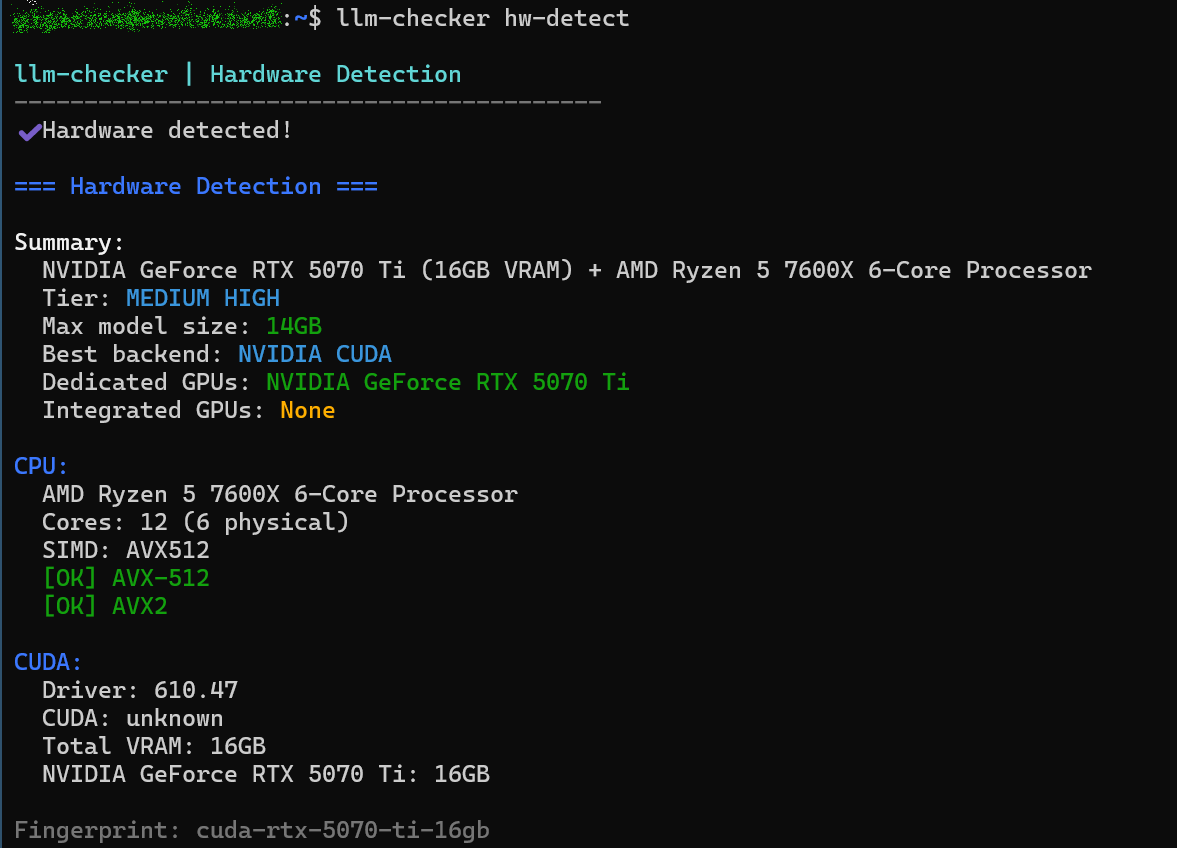
インストール後の初回実行時にはPCごとの調整を行う必要があります。まず、PCのハードウェア(CPU・GPU・RAM・アクセラレーションバックエンド)を検出するため以下のコマンドを実行します。
llm-checker hw-detect
実行結果は以下の通りとなりました。
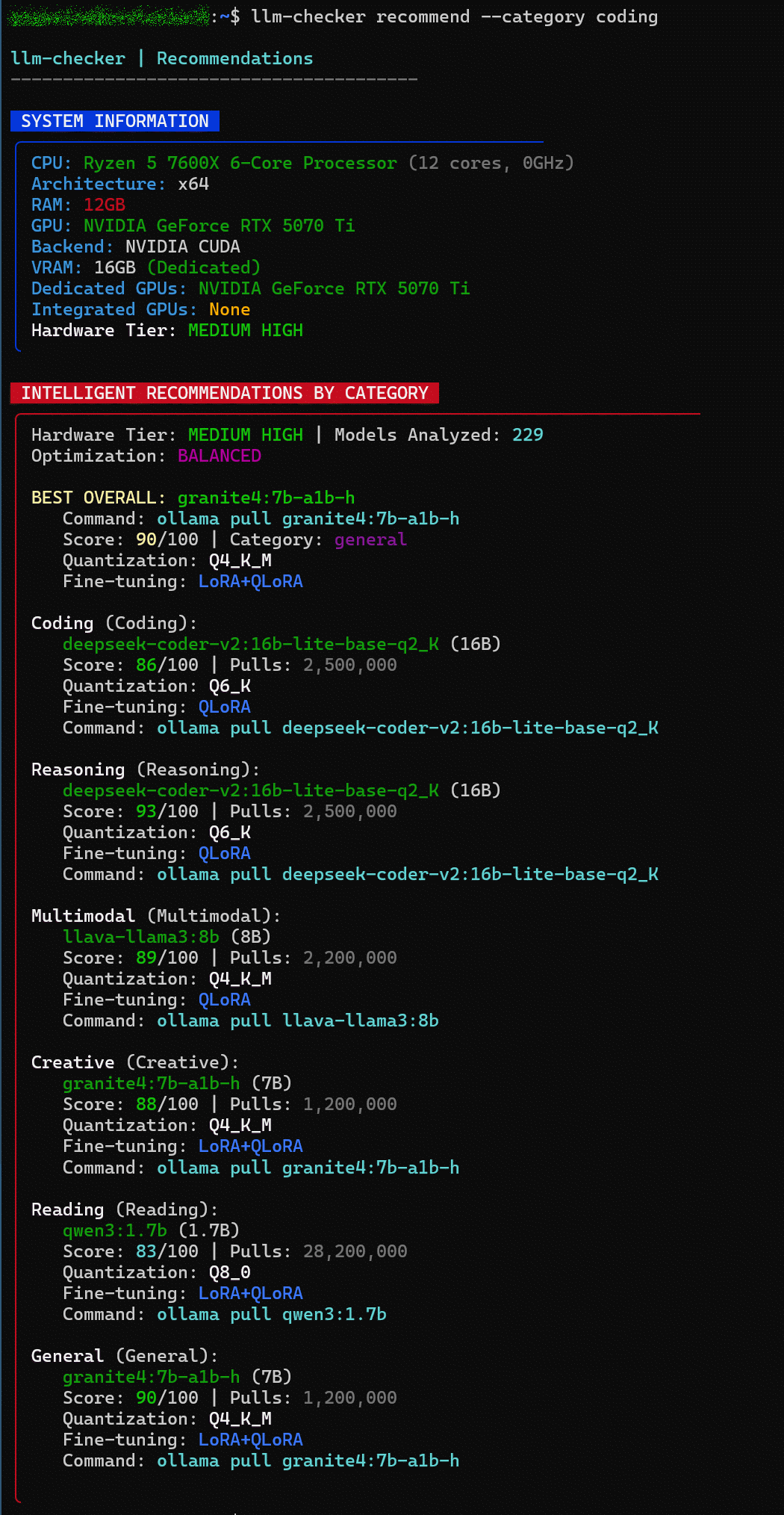
次に以下のコマンドを実行し、カテゴリー別(コーディング・推論・ マルチモーダルなど)のおすすめモデルを確認します。
llm-checker recommend --category coding
様々なおすすめモデルとインストールに必要なpullコマンドが列挙されています。
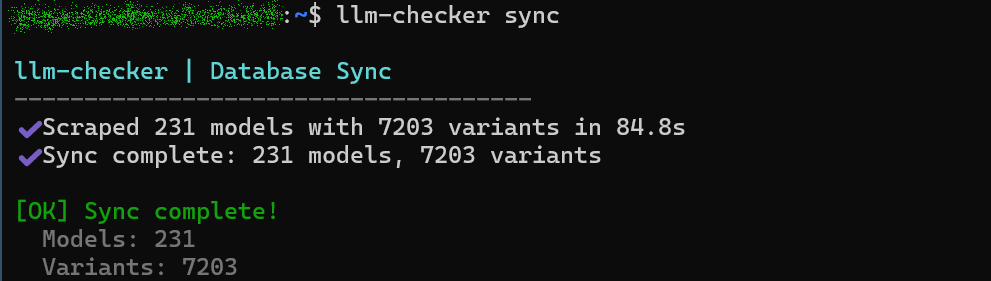
続いて以下のコマンドを実行し、ローカルのSQLiteモデルカタログを最新のOllamaリファレンスで更新します。
llm-checker sync
更新完了。
これで一通りの調整が完了したので、自動選択されたモデルとメトリクスを使用してAIへの指示を実行します。
llm-checker ai-run --category coding --prompt "Write a hello world in Python"
実行結果は以下の通りで、「ollamaがインストールされていない」と注意されてしまいました。
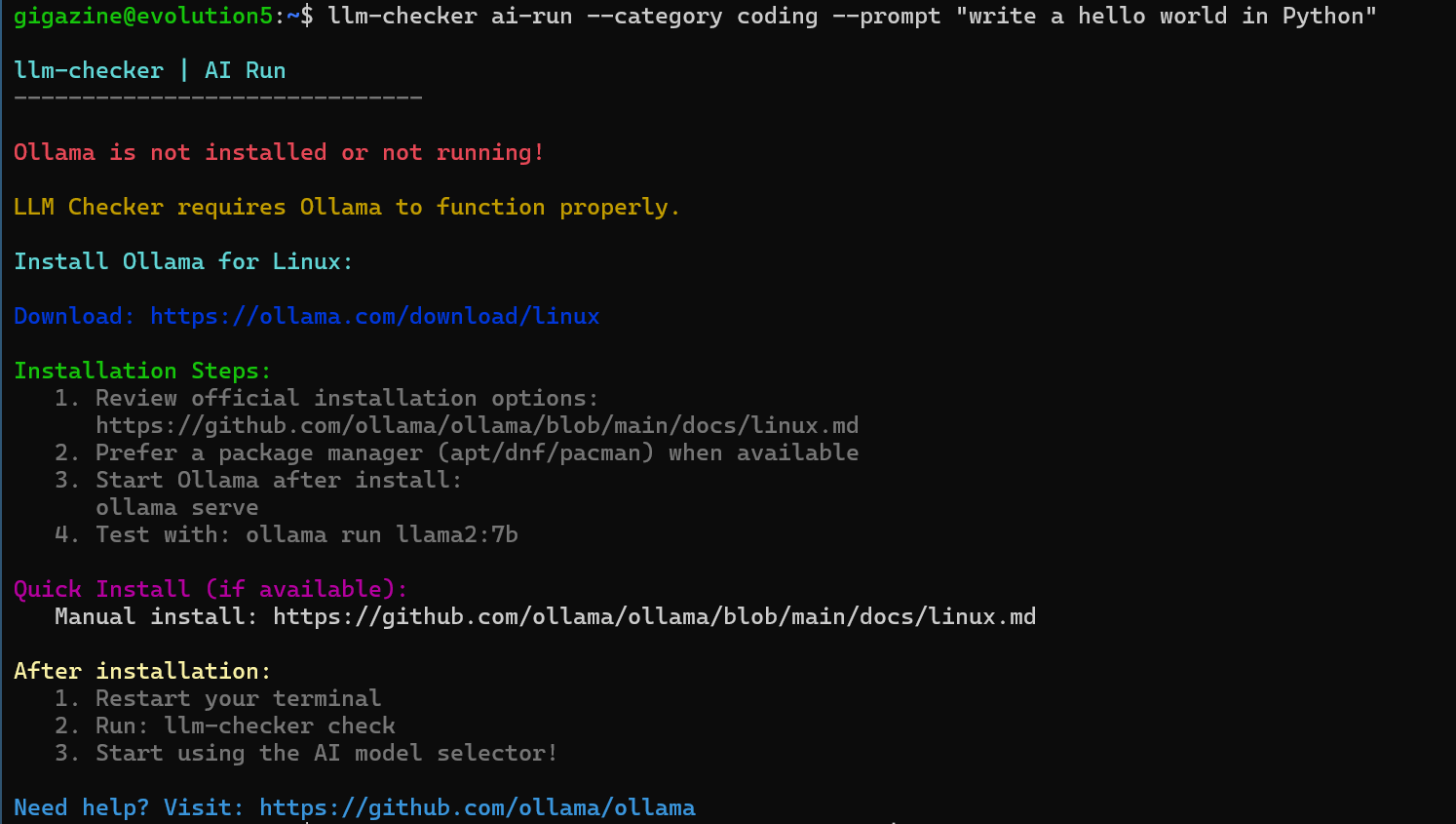
ollamaをインストールする際にzstdが必要になるので両者を合わせてインストールします。
sudo apt install -y zstd
curl -fsSL https://ollama.com/install.sh | sh
インストール後に再度AIへの指示を行ったところ、今度は「モデルが存在しない」と注意されました。

最初にインストールすべきモデルをいくつか指示されたうちから「llama2:7b」をpullコマンドでインストールします。
ollama pull llama2:7b
再度AIへの指示を行ったところ、なにやら奇妙な出力が行われてしまいました。出力内容を読んでみると「codellamaがインストールされていない」とあります。
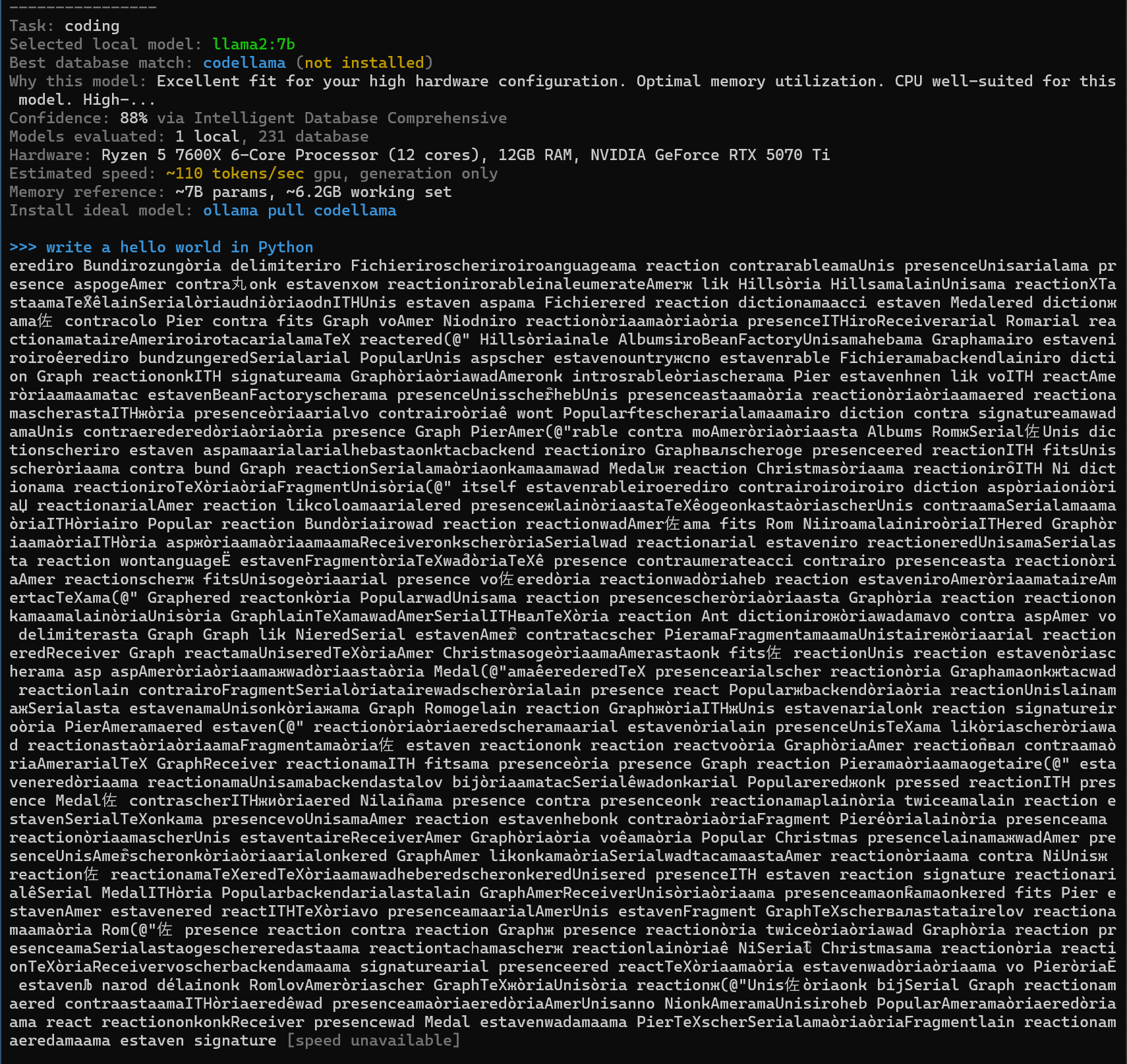
出力内容にある通りにpullコマンドを実行しcodellamaをインストールします。
ollama pull codellama
もう一度AIへの指示を行ったところ、ついに「hello world」という出力を行うPythonコードが出力されました。出力結果にある「Confidence(信頼性)」の値もllama2:7bでは88%でしたがcodellamaでは100%となっています。
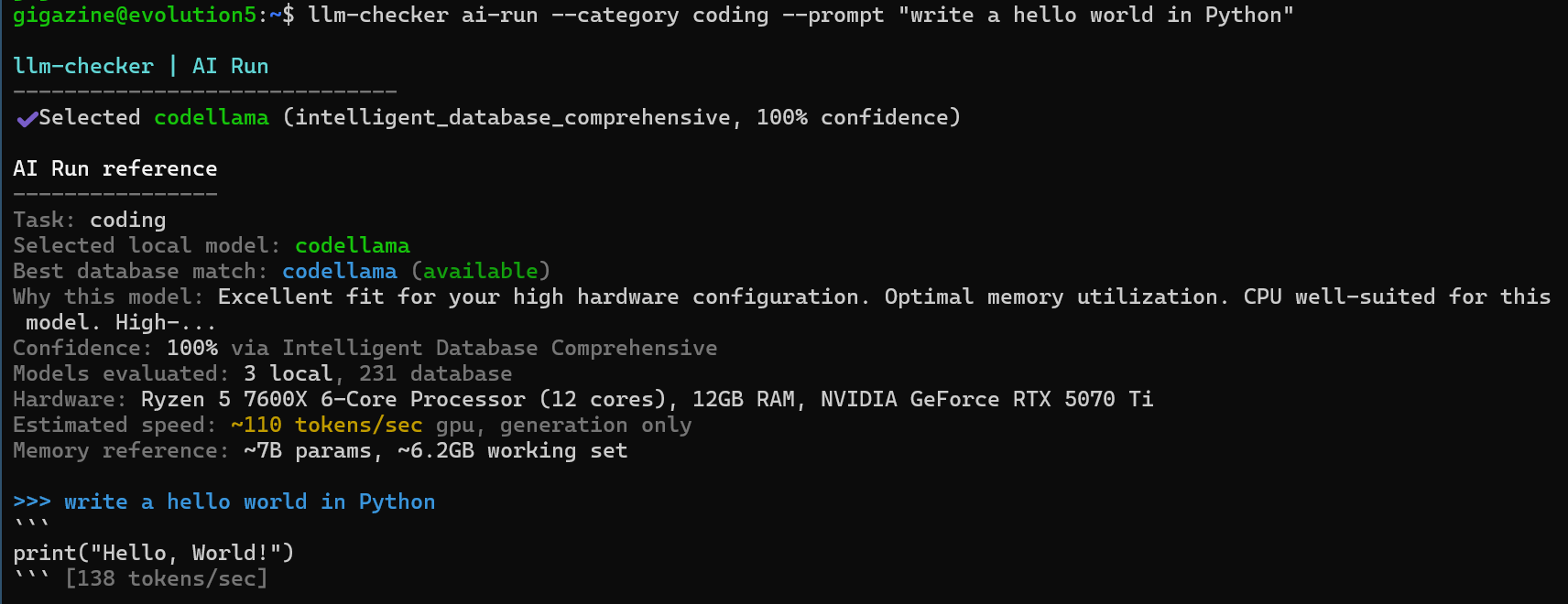
なお2回目以降に「ai-run」を実行する場合は既に調整済みであるため再度調整を行う必要はなく、オプションに「--calibrated」を追加するだけでOKです。
llm-checker ai-run --calibrated --category coding --prompt "Refactor this function"
◆まとめ
Ollamaを使用することを前提とするならば、状況に応じて適切なpullコマンドを指定してくれ、実際に動作を確認できるLLM Checkerは非常に心強いツールです。ローカルAIを自分のPCで動かすことに興味のある方は是非LLM Checkerを使ってみてください。
・関連記事
「ローカルAIがズルズルと動き続けて無駄にバッテリーやGPUリソースを消費してしまう問題」を解決する技術「AgentStop」がBraveによって開発される - GIGAZINE
無料で「ComfyUI」「Open WebUI」などからローカルAIモデルをGPUで動かすDocker環境を一発で構築し動かし続ける「Puget Systems Docker App Packs」 - GIGAZINE
無料でローカルAI環境を簡単に導入できる「Lemonade」、Windows・Linux・macOSにも対応したオープンソースで特にAMDのGPU・NPUで効果的 - GIGAZINE
複数のPCからリソースをかき集めて巨大なAIモデルをローカル実行できる「mesh-llm」 - GIGAZINE
システムのメモリ・CPU・GPUに合わせて適切なAIモデルを教えてくれるターミナルツール「llmfit」 - GIGAZINE
Windows・macOS・Linux・Android・iOSと連係しさまざまな操作ができセルフホスト可能なパーソナルAIアシスタント「OpenClaw」 - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, レビュー, Posted by log1c_sh
You can read the machine translated English article 'LLM Checker' is a free tool that helps ….