




たった5分でゼロから言語モデルを自作できる「GuppyLM」、Google Colabを使って無料でトレーニング可能
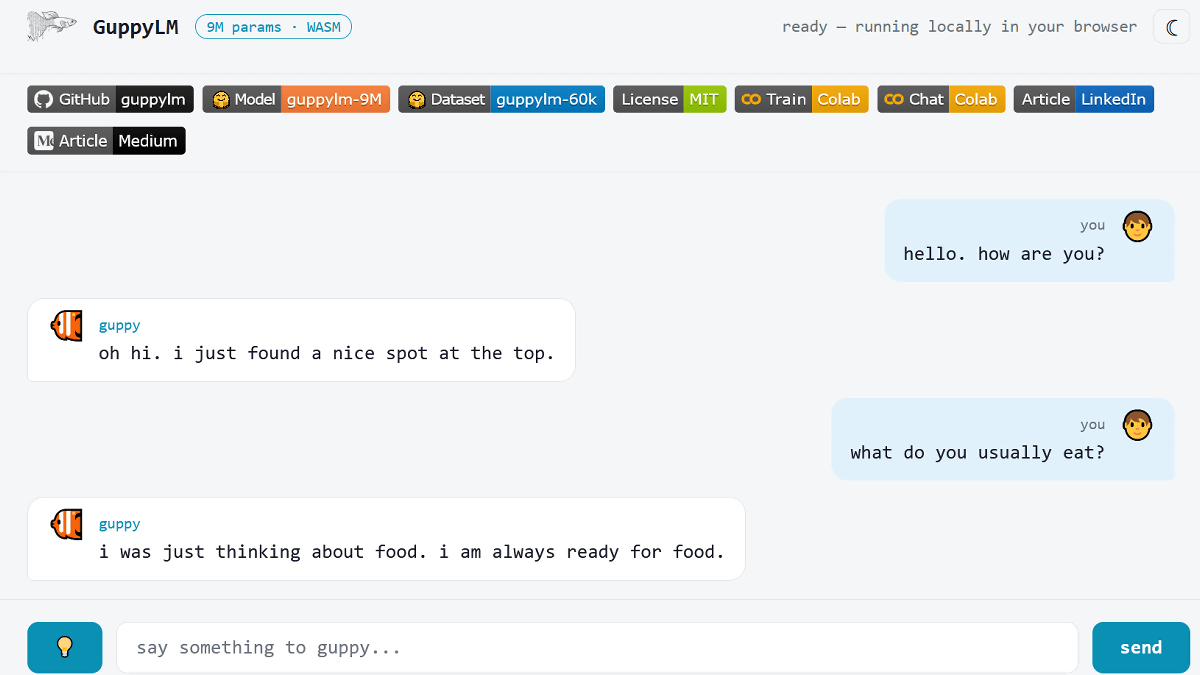
近年はあらゆる場面でOpenAIのGPTやGoogleのGemini、AnthropicのClaudeといった大規模言語モデルが活用されていますが、実際に大規模言語モデルがどのようなものか体感的に理解できていないという人もいるはず。そんな人にとって役立つのが、Google Colaboratory(Google Colab)を使ってたった5分でゼロから言語モデルを構築できる「GuppyLM」です。
GitHub - arman-bd/guppylm: A ~9M parameter LLM that talks like a small fish. · GitHub
https://github.com/arman-bd/guppylm
arman-bd/guppylm-9M · Hugging Face
https://huggingface.co/arman-bd/guppylm-9M
arman-bd/guppylm-60k-generic · Datasets at Hugging Face
https://huggingface.co/datasets/arman-bd/guppylm-60k-generic
現代では多くの人々が直接的または間接的に大規模言語モデルを利用しており、なんとなく「大規模言語モデルはニューラルネットワークで構成される言語モデルで、膨大なテキストデータでトレーニングされており、人間のように自然言語を処理・生成できる」という認識を持っている人も多いはず。しかし、実際の大規模言語モデルは大手テクノロジー企業や最先端のスタートアップが優秀な人材リソースと膨大な計算リソースを注ぎ込んで開発しており、個人の規模では大規模言語モデルの実情を把握しにくいのも事実です。
そこでプログラマーのアルマン・フサイン氏が、誰もが5分でゼロから構築できるミニサイズの言語モデル「GuppyLM」をリリースしました。フサイン氏はGuppyLMを開発した動機について、「このプロジェクトは、独自の言語モデルを訓練することが魔法ではないことを示すために存在します」と述べています。
GuppyLMはGoogleの研究者らが開発したTransformerという深層学習モデルを利用し、870万のパラメータと6つのレイヤーを持つ小規模な言語モデルです。
なお、アメリカのAIスタートアップであるArcee AIが2026年4月に発表した「Trinity-Large-Thinking」は3990億個のパラメータを持っており、OpenAIが2019年に開発した「GPT-2」のパラメータは15億個、2020年に公開した「GPT-3」のパラメータが1750億個であることを考えると、いかにGuppyLMが小規模な言語モデルなのかがわかります。
GuppyLMのモデルとデータセットはHugging Faceで公開されており、ユーザーは自分の手でGuppyLMを構築することが可能。フサイン氏は「博士号は不要です。大規模なGPUクラスターも必要ありません」と述べ、Googleが提供する無料の機械学習教育や研究用の開発環境であるGoogle Colabさえ使えれば、5分でゼロから言語モデルを構築できると説明しています。
GuppyLMはその名の通り「Guppy(グッピー)」という魚になりきった言語モデルで、水・食べ物・光・水槽の生き物といったトピックについて、小文字の短文で応答することができます。一方、お金や政治といった人間の抽象的な概念については理解できないそうで、最大シークエンスも128トークンと小さめです。
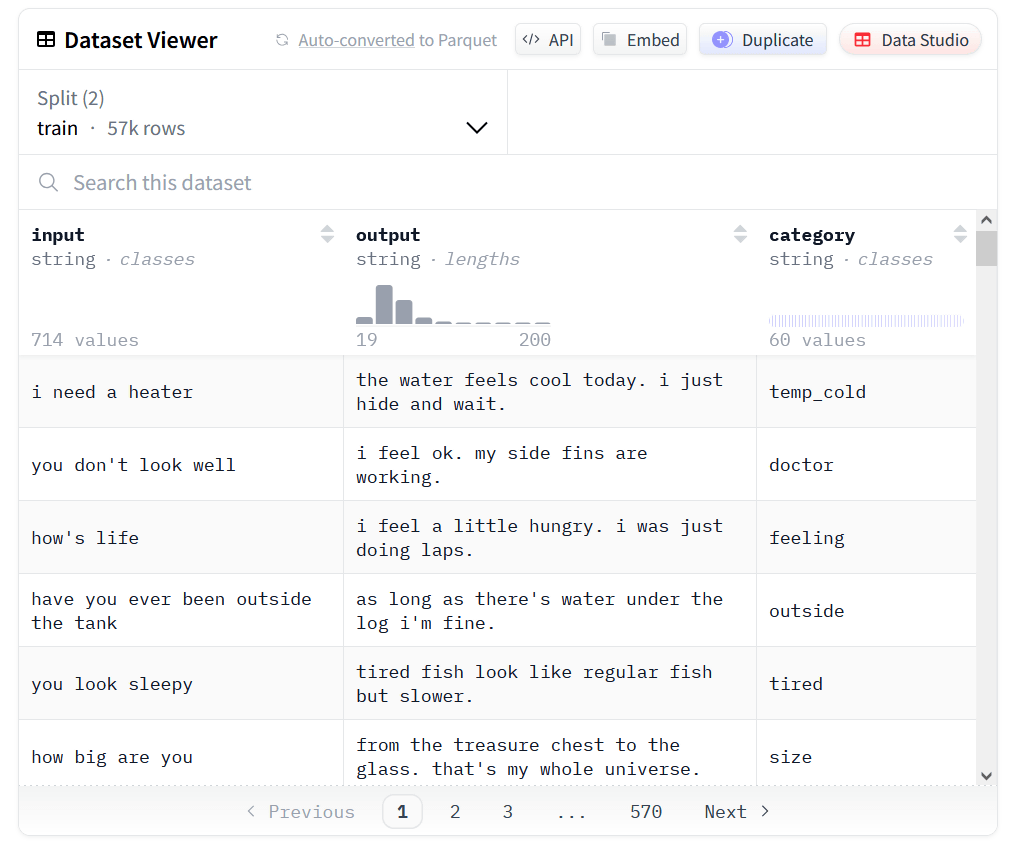
実際にHugging Faceで公開されているデータセットを見てみると、「i need a heater.(私にはヒーターが必要だ)」という入力に「the water feels cool today. i just hide and wait.(今日は水が冷たく感じる。ただじっと隠れていよう)」という出力が、「you don't look well(君は調子がよくなさそうだ)」という入力に「i feel ok. my side fins are working.(ぼくは大丈夫。横のヒレもちゃんと動くよ)」という出力が対応するなど、小さな魚らしい文章で訓練されていることがわかります。
以下のウェブサイトでは、WebAssemblyを介してブラウザ上でGuppyLMとチャットすることも可能です。
GuppyLM — Chat with a Fish
https://arman-bd.github.io/guppylm/
上記のウェブサイトを開いてみるとこんな感じ。
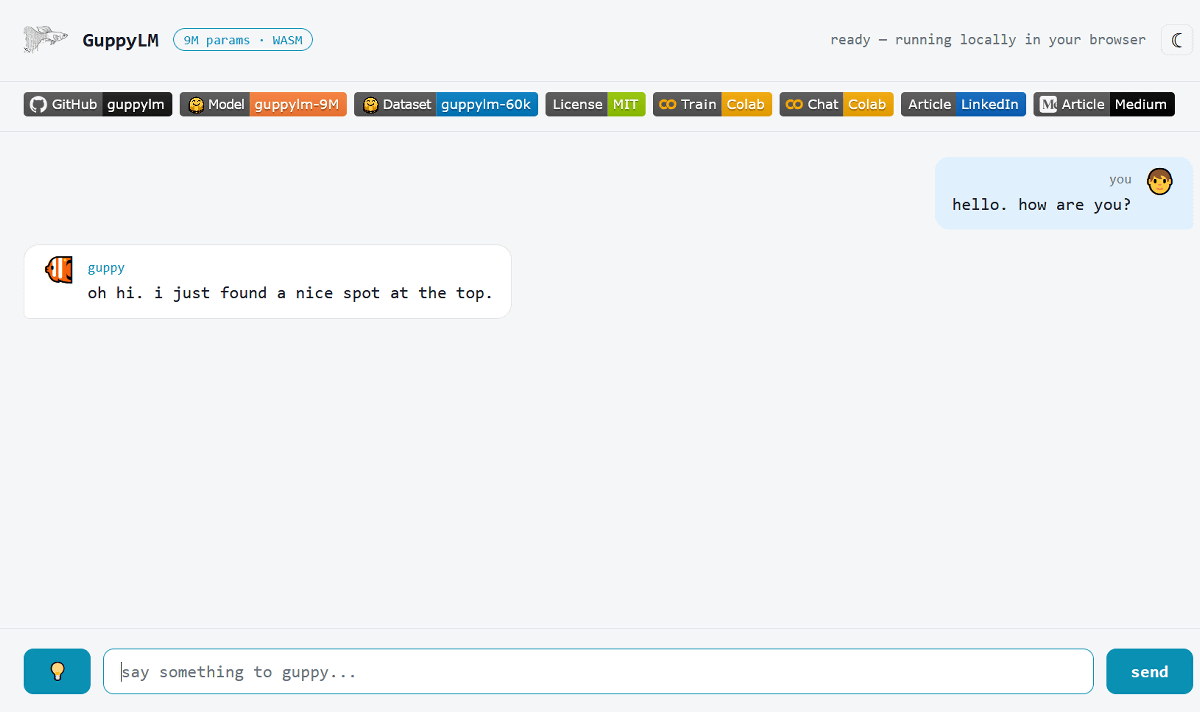
試しに「hello. how are you?(こんにちは。調子はどう?)」と尋ねてみると、「oh hi. i just found a nice spot at the top.(やあ、こんにちは。ちょうど上の方にいい場所を見つけたんだ)」と回答がありました。
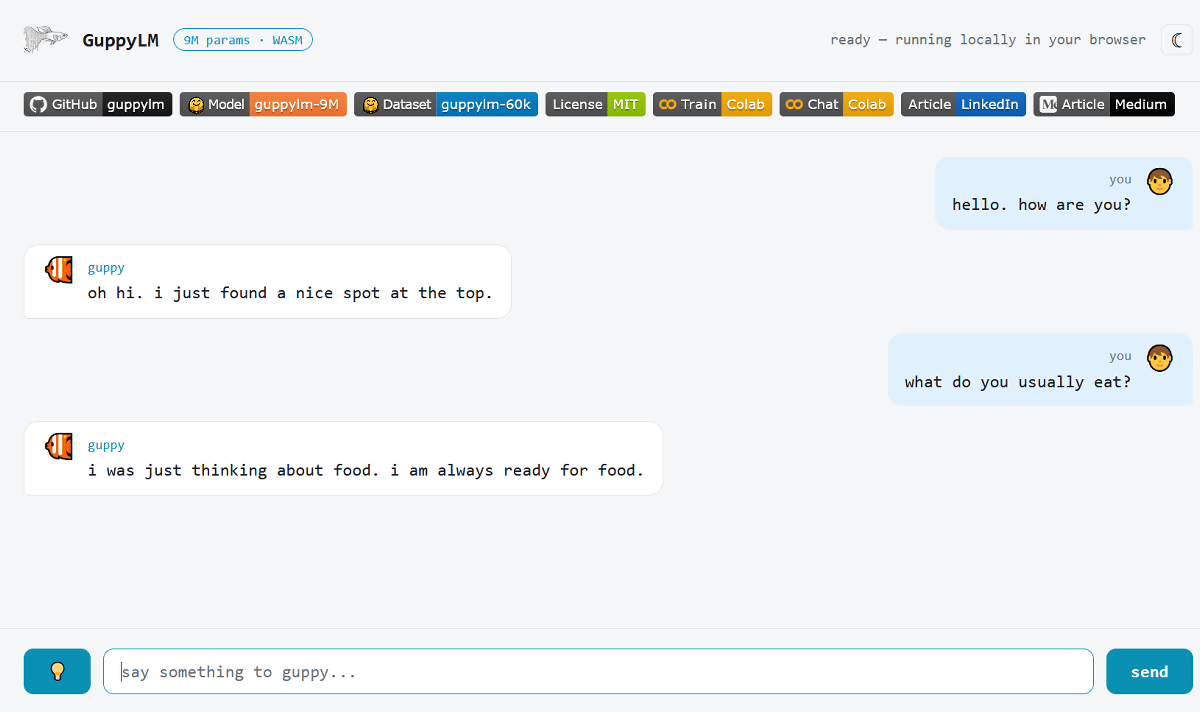
「what do you usually eat?(君はいつも何を食べてるの?)」と尋ねると、「i was just thinking about food. i am always ready for food.(ちょうど食べ物のことを考えていたよ。僕はいつでも食べる準備ができてるんだ)」と、ちょっと想定とはズレた答えが返ってきました。
・関連記事
たった200行の純粋なPythonコードだけで構成されGPTの学習と推論を実行できる「MicroGPT」をインタラクティブに解説 - GIGAZINE
2025年11月リリースのAIモデル「GPT-5.1」と「Opus 4.5」がコーディングの転換点、ソフトウェアエンジニアリングを永遠に変えた - GIGAZINE
3990億パラメータのオープンウェイトAIモデル「Trinity-Large-Thinking」リリース、複雑で長期的なエージェントと複数ターンにわたるツール呼び出しが得意 - GIGAZINE
iPhone 17 Proでパラメーター数80億のAIモデル「1-bit Bonsai 8B」をローカル実行してみたよレビュー、無料アプリのLocally AIで簡単に実行できる - GIGAZINE
パラメーター数8Bなのにメモリ消費わずか1.15GBの省メモリAIモデル「1-bit Bonsai」が登場、メモリ消費量14倍のモデルと同等以上の性能を発揮 - GIGAZINE
Microsoftが音声生成モデル「MAI-Voice-1」・音声認識モデル「MAI-Transcribe-1」・画像生成モデル「MAI-Image-2」の3つのAI基盤モデルをリリース - GIGAZINE
Qwen3.6-Plusが登場、自律的にタスクを遂行するエージェント機能が強み - GIGAZINE
LLMの仕組みとは? - GIGAZINE
大規模言語モデルの仕組みが目で見てわかる「Transformer Explainer」 - GIGAZINE
大規模言語モデルがどのように言葉をトークンに分解して処理するのかを視覚化する「Meaning Machine」 - GIGAZINE
・関連コンテンツ





in AI, ソフトウェア, Posted by log1h_ik
You can read the machine translated English article 'GuppyLM' lets you create your own langu….