




大規模言語モデルがどのように言葉をトークンに分解して処理するのかを視覚化する「Meaning Machine」

ChatGPTやClaude、Grokなどの大規模言語モデルを用いた生成AIは、まるで人間のようにユーザーの言葉に対して適切な返答をします。しかし、大規模言語モデルが言語を処理する方法と、人間が言語を処理する方法には大きな違いがあるとのこと。「Meaning Machine」というウェブサイトは、大規模言語モデルがどのように言語を処理しているのかについて、視覚的にわかりやすく示してくれるものとなっています。
Meaning Machine · Streamlit
https://meaning-machine.streamlit.app/
How Language Models See You - by Joshua Hathcock
https://theperformanceage.com/p/how-language-models-see-you
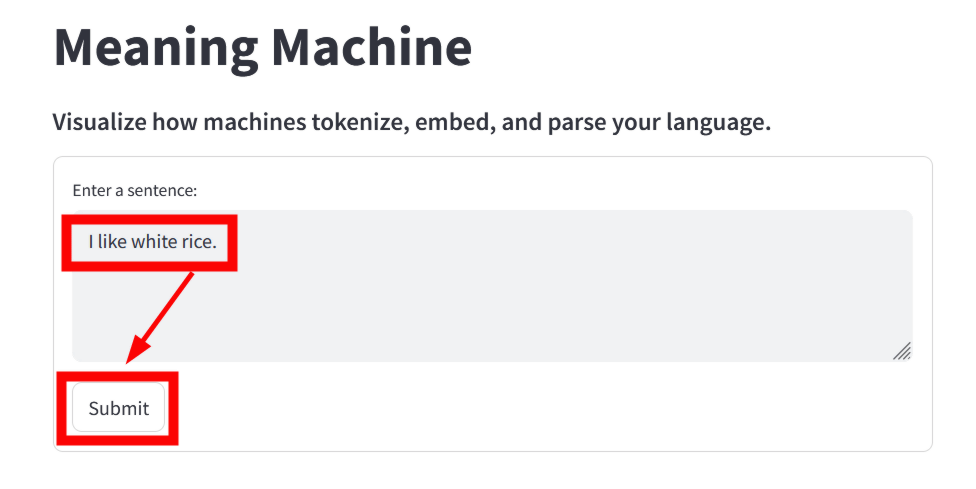
Meaning Machineにアクセスすると、画面上部に文章の入力フォームが表示されます。デフォルトでは「The young student didn't submit the final report on time.(その若い生徒は最終レポートを期日までに提出しなかった)」という文章が表示されています。
その下には、入力された文章を単語ごとに分割し、各単語を「トークン」として表した際の数値IDが表示されています。以下の例では、「the」のトークンは「1996」、「young」のトークンは「2402」、「student」のトークンは「3076」となっており、すでに人間の言語理解とは異なる仕方で文章を捉えていることがわかります。
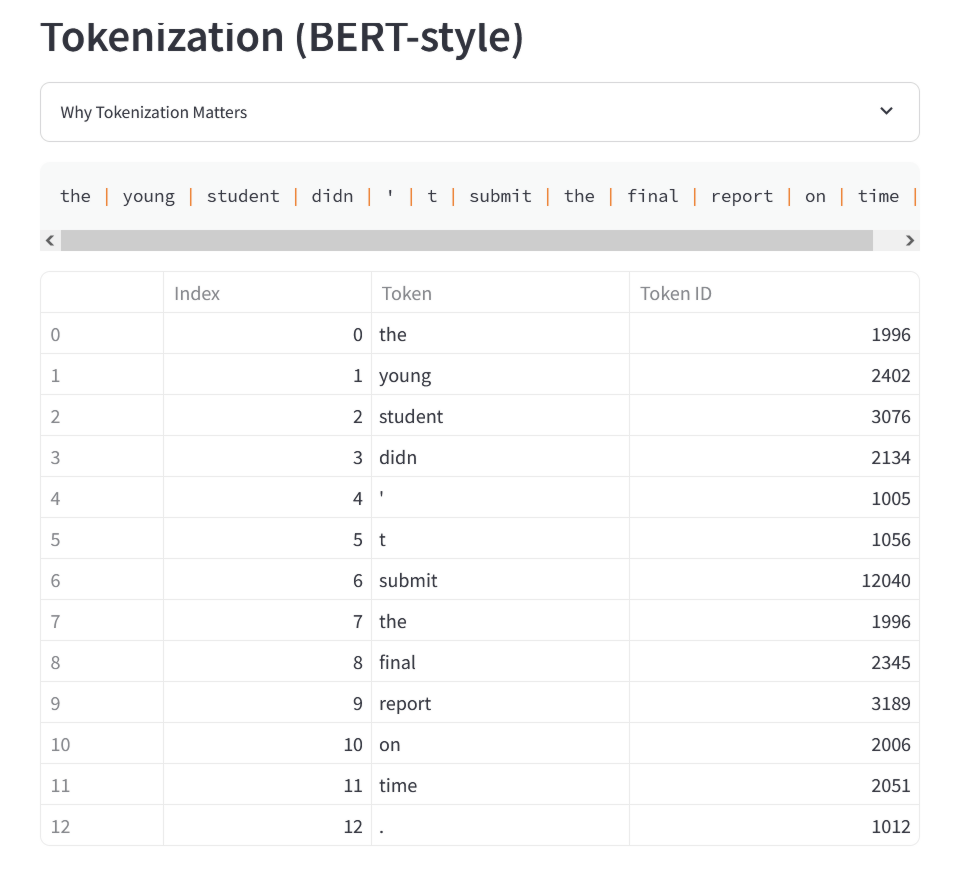
Meaning Machineを開発したジョシュア・ハスコック氏は、大規模言語モデルは文全体をまとめて処理するのではなく、単語や文字セットをトークンという数値IDに分割し、抽象的に処理していると説明しています。たとえばChatGPTのベースになっているGPTモデルの場合、「The」「young」「student」「didn」「t」「submit」などの一般的な単語は単一のトークンで表されることが多いものの、珍しい単語はサブワードの組み合わせからなる複数個のトークンに分割されるそうです。
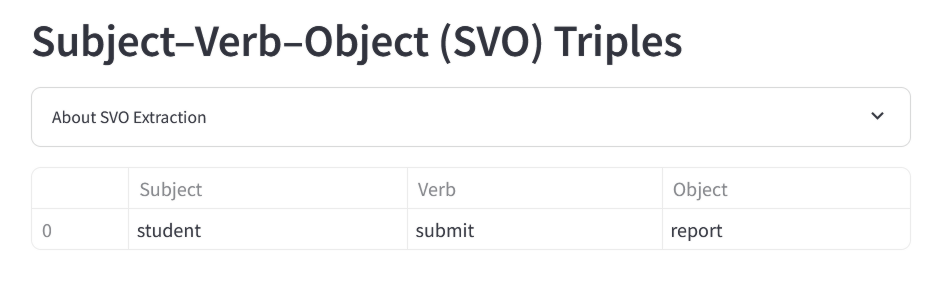
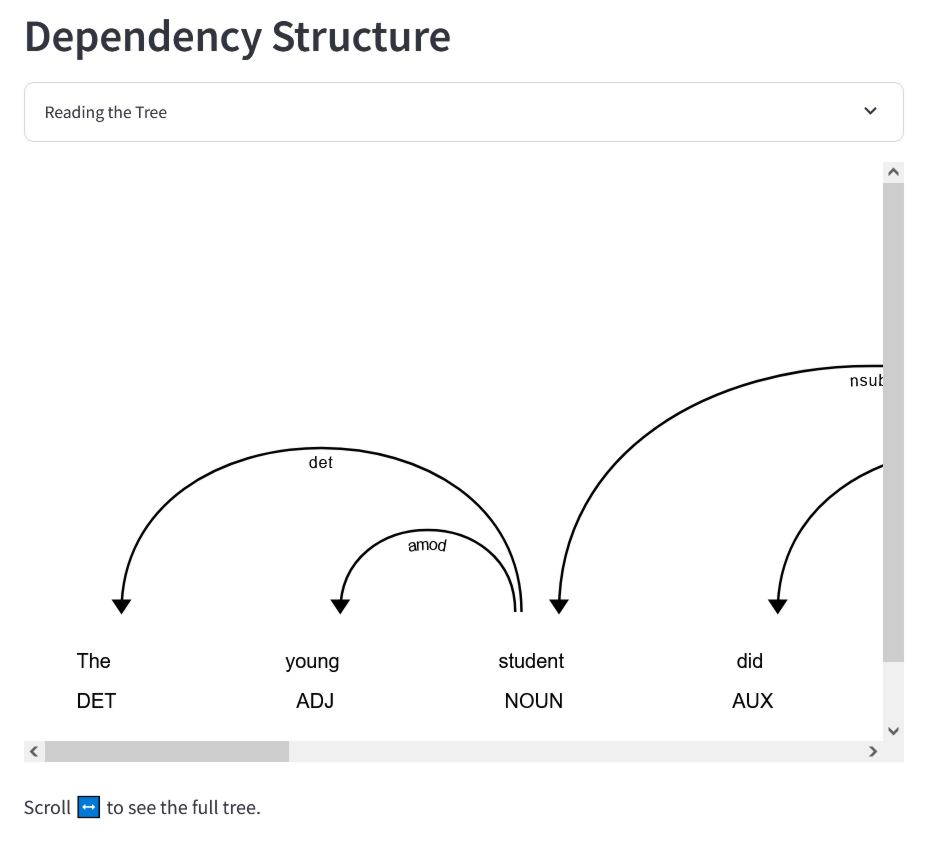
その後、大規模言語モデルは各トークンの文法的な役割を特定し、文章の主語や動詞、目的語などを推定します。例となった文章の場合、主語は「student」、動詞は「submit」、目的語は「report」となります。
大規模言語モデルは各トークンのPOS(品詞)をタグ付けし、文章におけるDependancy(依存関係)をマッピングし、文章を構造化して表現するとのこと。
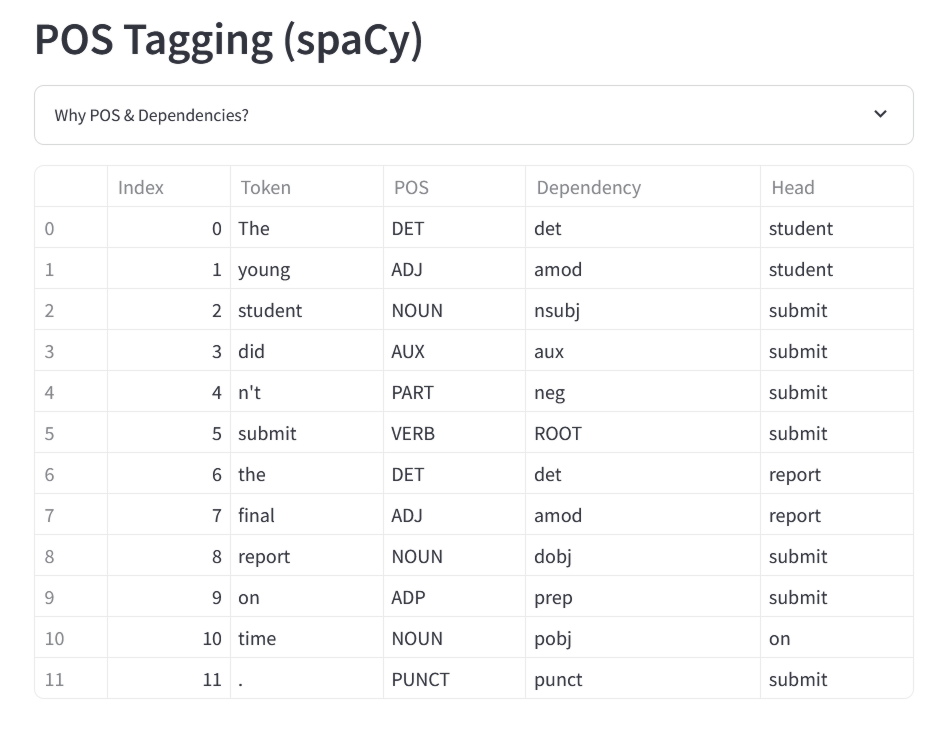
なお、依存関係を示す文字列がどのような意味を持っているのかは、Meaning Machineのページ下部にある表で説明されています。
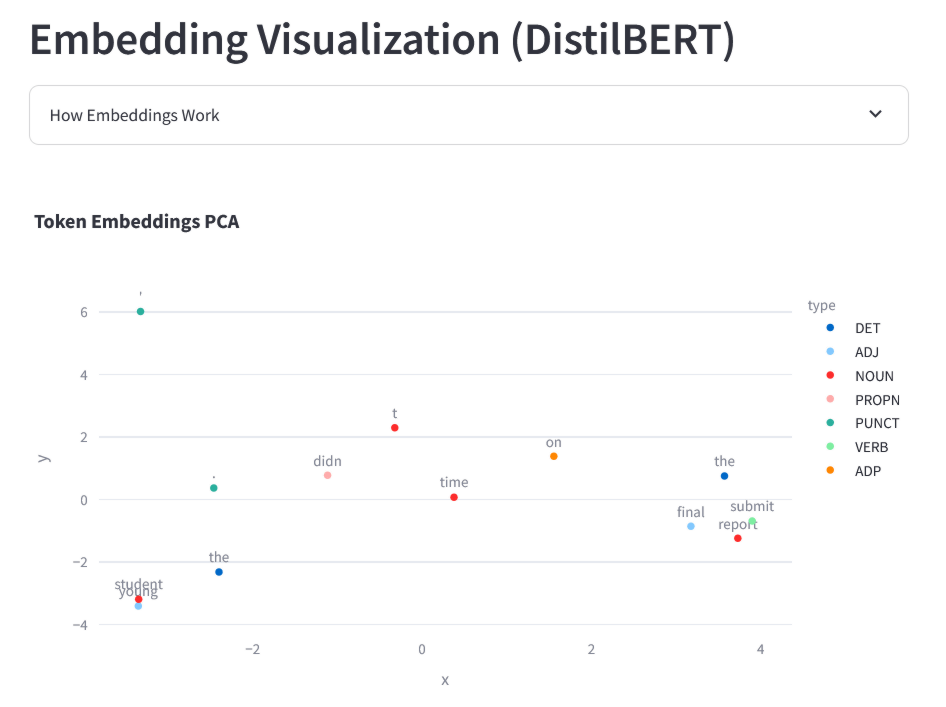
そして各トークンは、意味と文脈を捉えた数百もの数字からなるリスト(ベクトル)に変換されます。以下の図は例文の各トークンを、Googleが開発した自然言語モデル・BERTの768次元埋め込みを使用し、主成分分析(PCA)を通じて二次元で視覚化したもの。この図では似たような意味、文脈、または機能を持つ言葉は近い数学的空間に集まるとのことで、例文では「student」と「young」、「submit」と「report」などが近くに位置しているのがわかります。
その下に表示されているのが、各トークンの依存関係を示したツリーです。このツリーでは、どのトークンがどのトークンとどのような依存関係にあり、これらが全体でどのような意味をなしているのかを示しているとのこと。
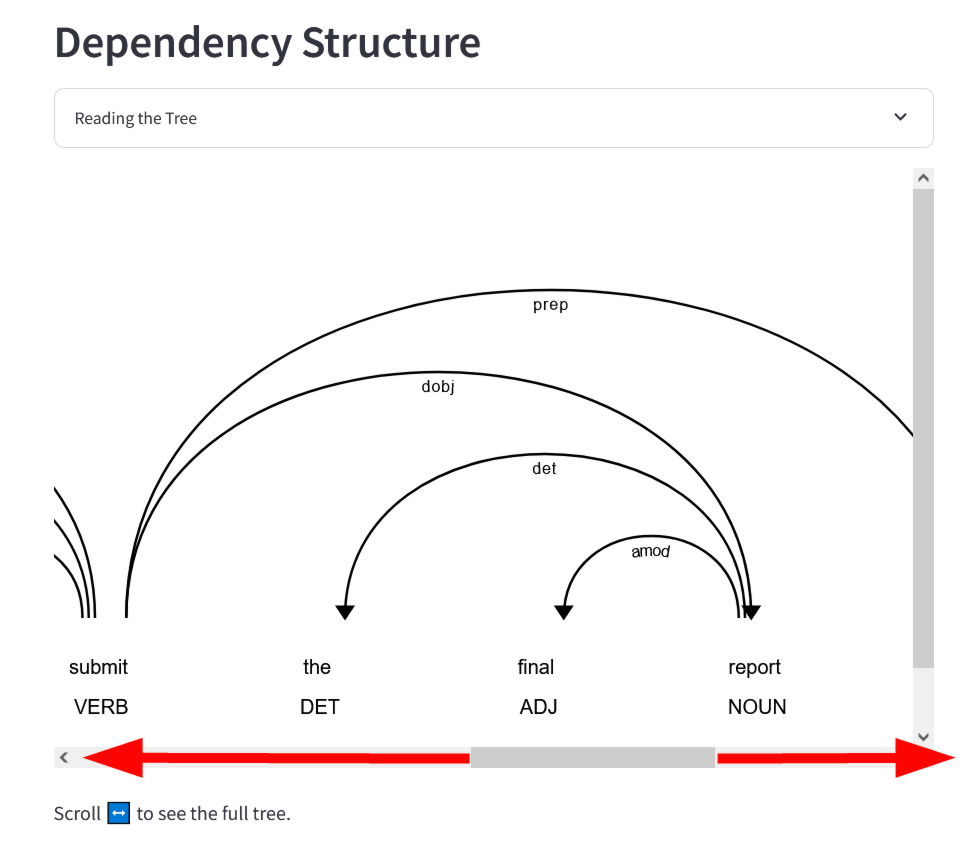
図の下部にあるバーを左右に動かすことで、依存関係全体を見回すことができます。
Meaning Machineでは、ページ上部にある入力フォームに好きな文章を入力することで、大規模言語モデルが各単語をどのようなトークンに変換しているのかや、どのように文全体の依存関係を捉えているのかを見ることが可能です。
ハスコック氏は、「これらの技術的なステップは、言語モデルが人間のように言語を理解していないという、より深いことを明らかにしています。彼らは言語を説得力を持ってシミュレートしますが、根本的に人間のそれとは異なります。あなたや私が『dog(犬)』と言う時、私たちは毛皮の感触やほえる声、さらに感情的な反応を思い出すかもしれません。しかし大規模言語モデルが『dog』という単語を見ると、『bark(ほえる)』『tail(尻尾)』『vet(獣医)』などの単語の近くに『dog』が出現する頻度によって形成される数字のベクトルが表示されます。これは間違ったことではなく、統計的な意味があります。しかし、これには実体がなく、根拠もなく、知っているわけでもないのです」と述べています。
つまり、大規模言語モデルと人間では言語の処理方法が根本的に異なっており、いくら人間のような受け答えをするとしても、そこには信念や目標といったものが存在していないというわけです。それにもかかわらず、すでに大規模言語モデルは社会に広く浸透しており、人々の履歴書を作成したりコンテンツをフィルタリングしたり、時には「何に価値があるのか」といったものまで決定しています。すでにAIは社会的なインフラストラクチャーとなりつつあるため、大規模言語モデルのパフォーマンスと理解の違いを知ることは重要だとハスコック氏は主張しました。
・関連記事
Metaの大規模言語モデル「LLaMa」に入力した文章がどのようなトークンとして認識しているかを確認できる「LLaMA-Tokenizer」 - GIGAZINE
GPT-4oはどのように画像をエンコードしてトークンに分解しているのか? - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
大規模言語モデルの仕組みが目で見てわかる「Transformer Explainer」 - GIGAZINE
処理するトークンが増えすぎるとAI言語モデルが動作困難になる理由、計算コストは入力サイズの2乗に比例 - GIGAZINE
GPT-4やClaudeなどの大規模言語モデルが抱える「ストロベリー問題」とは? - GIGAZINE
OpenAIがGPT-4の思考を1600万個の解釈可能なパターンに分解できたと発表 - GIGAZINE
・関連コンテンツ



in ソフトウェア, ネットサービス, Posted by log1h_ik
You can read the machine translated English article 'Meaning Machine' visualizes how large-s….