




人工知能に空間&時間の4次元認識能力を与えるためのAI「D4RT」をGoogleが発表、「人間と同じように世界を認識できるAI」の開発に役立つ

Google DeepMindが動画をもとに3次元空間を時系列に沿って認識できるAI「D4RT」を開発しました。D4RTは既存モデルと比べて高精度かつ高速な空間認識が可能で、人間と同じように世界を認識できるAIの開発に役立つとされています。
D4RT
https://d4rt-paper.github.io/
D4RT: Unified, Fast 4D Scene Reconstruction & Tracking - Google DeepMind
https://deepmind.google/blog/d4rt-teaching-ai-to-see-the-world-in-four-dimensions/
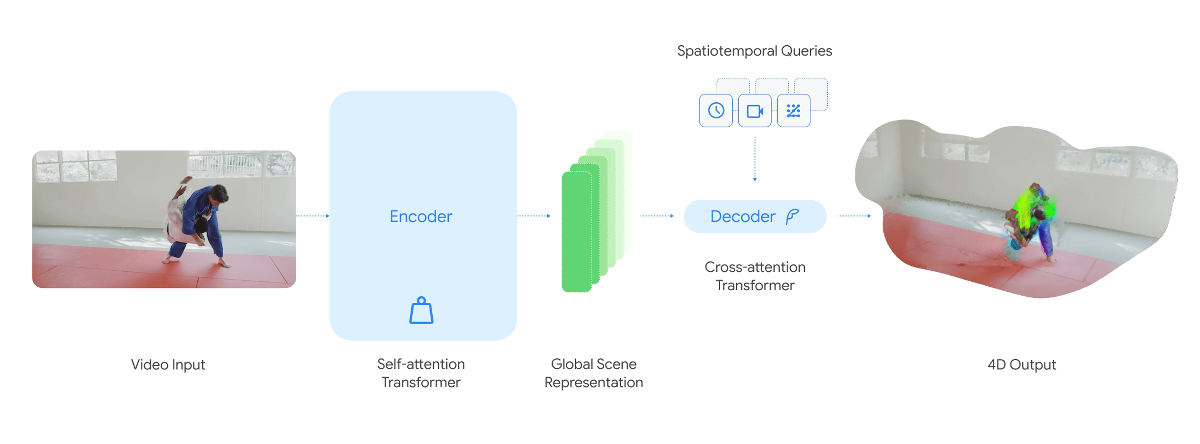
人間は視覚情報をもとに3次元空間を認識し、一瞬前と現在の状況をもとに未来の状況を推測することができます。このため、AIに人間と同様の世界認識能力を持たせるには「カメラで撮影した映像の認識能力」だけでなく、「カメラの映像をもとに立体的な3次元空間を構築し、時系列に沿って動きを理解する」という空間と時間を組み合わせた4次元認識能力も必要です。
D4RTはカメラで記録した映像をもとに3次元空間を構築し、すべてのオブジェクトのすべてのピクセルを時系列に沿って認識可能です。
To perceive a 2D scene captured on video, an AI must track every pixel of every object as it moves. 🔍️️
— Google DeepMind (@GoogleDeepMind) January 22, 2026
Capturing this level of geometry and motion requires computationally intensive processes leading to slow and fragmented reconstructions. But D4RT takes a different… pic.twitter.com/LraeC1bWUE
既存のAIモデルで同様の4次元認識システムを構築するには「深度認識AI」「動体認識AI」「カメラアングル認識AI」といった複数の専用AIモデルを組み合わせる必要があり、処理に時間がかかっていました。一方でD4RTはTransformerベースの単一モデルで必要な処理を実行可能であり、精度とスピードを両立することに成功しています。
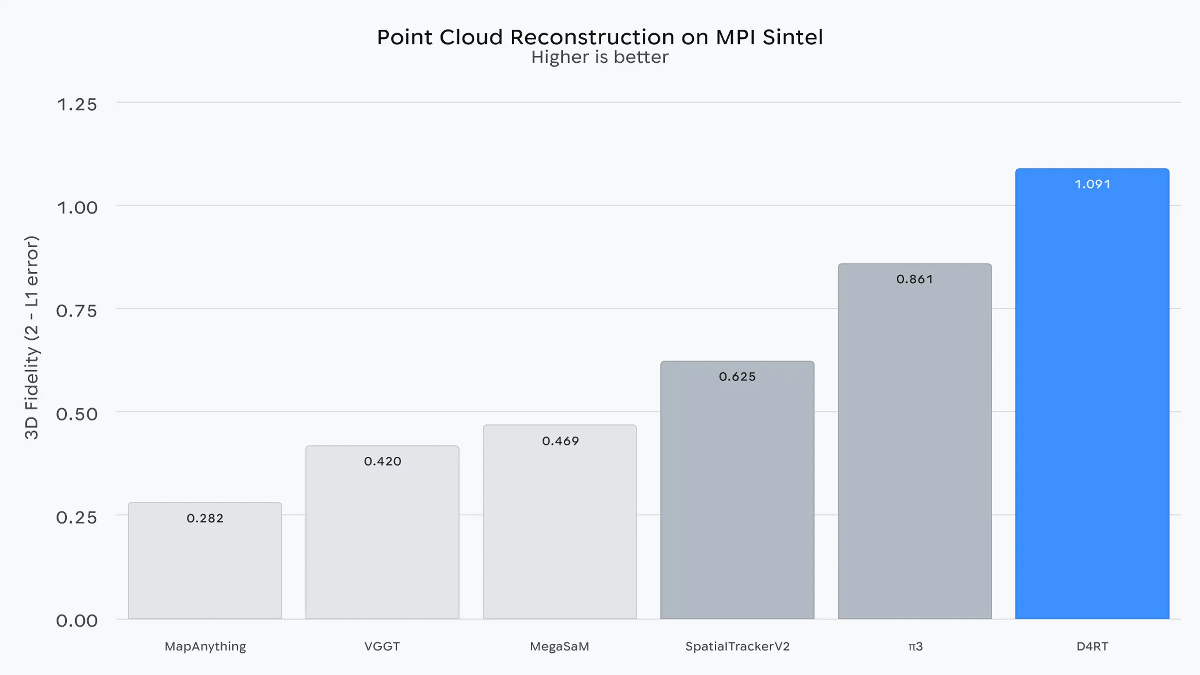
各種AIの4次元認識性能を比較したグラフが以下。D4RTは既存モデルと比べて高い認識性能を示しています。また、既存の技術では1分間の動画を処理するのに10分かかりましたが、D4RTでは約5秒で処理を完了できるとのこと。Google DeepMindは「D4RTは既存の技術と比べて120倍の高速化を実現した」とアピールしています。
D4RTの技術論文は以下のリンク先で公開されています。
[2512.08924] Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
https://arxiv.org/abs/2512.08924
・関連記事
Googleの画像生成AIはなぜ「Nano Banana」という名前なのか? - GIGAZINE
Googleがロボット用のAIモデル「Gemini Robotics 1.5」を発表、思考して行動を決定できる - GIGAZINE
翻訳特化のAIモデル「TranslateGemma」をGoogleが公開、日本語も対応 - GIGAZINE
Googleの動画生成AI「Veo 3.1」がアップデートされてキャラクターの一貫性が向上し4Kアップスケーリングにも対応 - GIGAZINE
GoogleがCT画像やMRIデータに対応した医療特化AIモデル「MedGemma 1.5 4B」と文字起こしモデル「MedASR」を公開 - GIGAZINE
Google初のAIスマートグラスは2026年に登場予定 - GIGAZINE
・関連コンテンツ






in AI, 動画, ソフトウェア, Posted by log1o_hf
You can read the machine translated English article Google announces 'D4RT,' an AI that give….