




AIチップの性能を測定して毎日公開するオープンソースのベンチマーク「InferenceMAX」が登場、NVIDIAとAMD両対応で急速に進歩し続けるAIチップの現状を知れる
AIや半導体に関する情報分析企業のSemiAnalysisがAIチップの性能を測定できるベンチマークシステムの「InferenceMAX」を開発しました。InferenceMAXはAIチップの性能を測定を毎日継続的に実行することを特徴としており、NVIDIAやAMDなどのAIチップの性能を継続的に評価することができます。
InferenceMAX by SemiAnalysis
https://inferencemax.semianalysis.com/
InferenceMAX™: Open Source Inference Benchmarking
https://newsletter.semianalysis.com/p/inferencemax-open-source-inference
InferenceMAX Benchmarking Progress in Real Time
https://www.amd.com/en/developer/resources/technical-articles/2025/inferencemax-benchmarking-progress-in-real-time.html
NVIDIA Blackwell が新しい InferenceMAX ベンチマークの基準を引き上げ、比類のないパフォーマンスと効率を実現 - NVIDIA | Japan Blog
https://blogs.nvidia.co.jp/blog/blackwell-inferencemax-benchmark-results/
AIチップを用いたAI処理の性能は「AIチップそのもののハードウェア性能」だけで決まるわけではなく、「AIフレームワーク」や「AIチップ上で動作する処理エンジン(ソフトウェア)」といった周辺技術の改善によって全体的な処理性能も変化します。このため、AIチップの処理性能を正確に把握するには継続的な性能測定が必要です。InferenceMAXは継続的な性能測定を念頭に設計されており、公式ページでその日の最新情報を閲覧できます。
記事作成時点のInferenceMAXのテスト対象はNVIDIAの「GB200 NVL72」「B200」「H200」「H100」と、AMDの「MI355X」「MI325X」「MI300X」で、すでに世界中で展開されているAI処理能力の80%以上をカバーしています。さらに、近日中にGoogleのTPUとAmazonのTrainiumにも対応し、AI処理能力の99%以上をカバーできるようになるそうです。
Today we are launching InferenceMAX!
— Dylan Patel (@dylan522p) October 9, 2025
We have support from Nvidia, AMD, OpenAI, Microsoft, Pytorch, SGLang, vLLM, Oracle, CoreWeave, TogetherAI, Nebius, Crusoe, HPE, SuperMicro, Dell
It runs every day on the latest software (vLLM, SGLang, etc) across hundreds of GPUs, $10Ms of… https://t.co/3Bbsh3OANF
InferenceMAXではテスト用モデルとして「Llama 3.3 70B Instruct」「DeepSeek R1 0528」「gpt-oss 120B」の3種が使われており、それぞれのモデルで「入力1000トークン/出力1000トークン」「入力1000トークン/出力8000トークン」「入力8000トークン/出力1000トークン」という3種の条件でテストが実行されています。また、モデルの精度はFP8とFP4の2種類が用意されています。
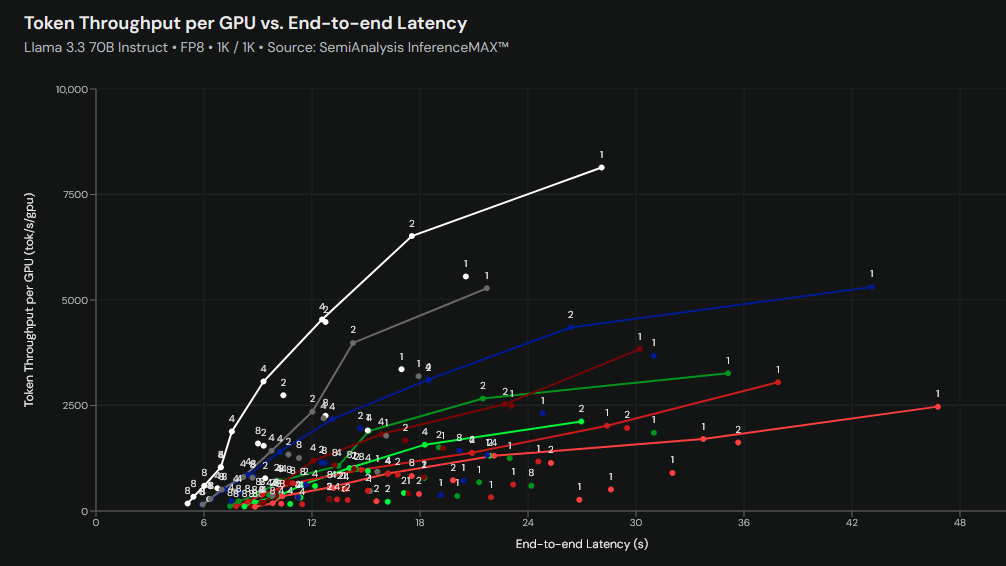
「Llama 3.3 70B Instruct」「入力1000トークン/出力1000トークン」「FP8」という条件で実行された2025年10月12日3時19分59秒時点のベンチマーク結果が以下。縦軸がAIチップ1個当たりの秒間処理トークン数、横軸が処理結果がユーザーに届くまでの時間を示しています。グラフを見ると、NVIDIAのB200が処理トークン数と処理時間の両面で優秀な成績を収めていることが分かります。

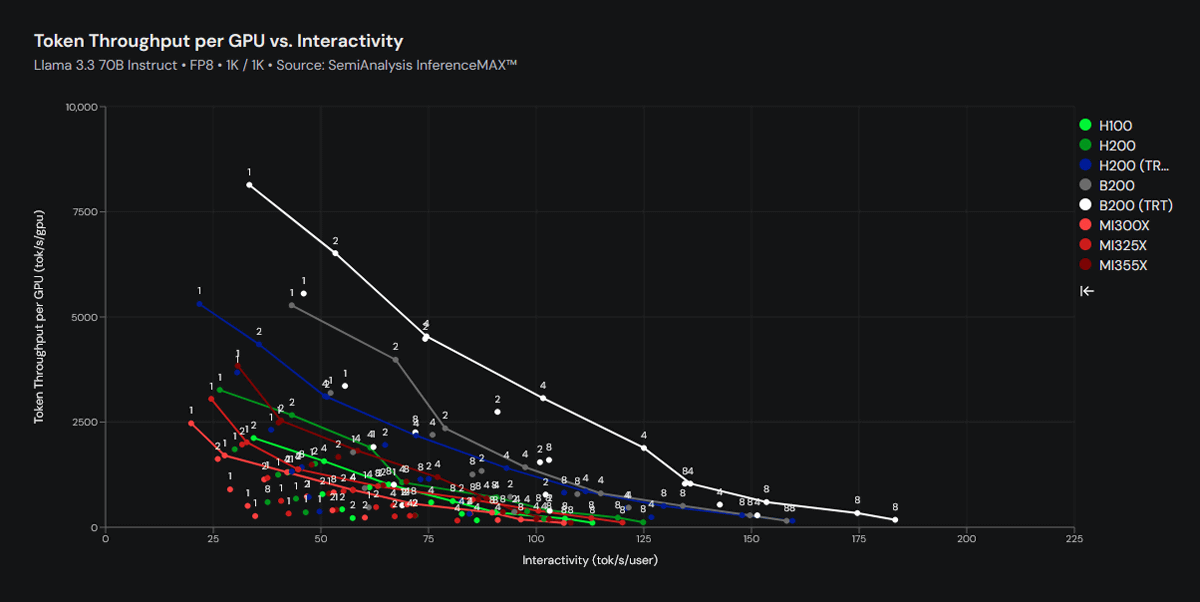
以下のグラフは縦軸がAIチップ1個当たりの秒間処理トークン数で、横軸がユーザー1人当たりの秒間処理トークン数です。このグラフでもB200がずば抜けた成績を記録しています。
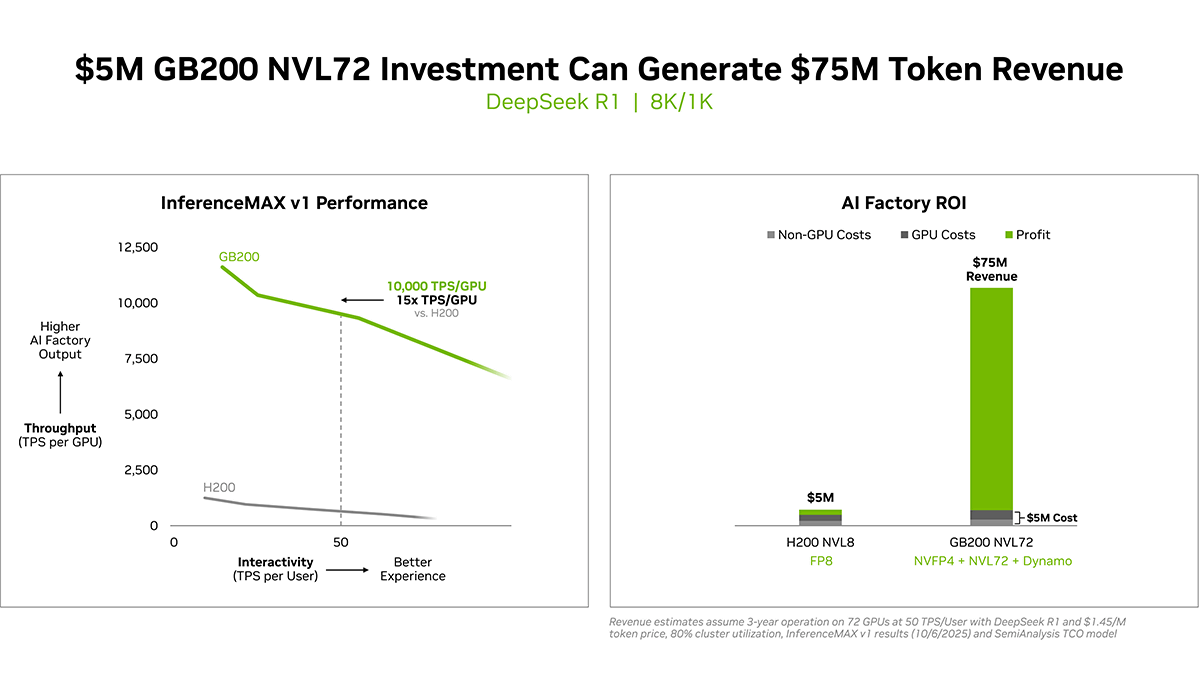
NVIDIAはInferenceMAXのリリースに合わせて公式ブログを更新し、GB200 NVL72がH200と比べて性能面とコストパフォーマンスの両面で優秀であることをアピールしています。
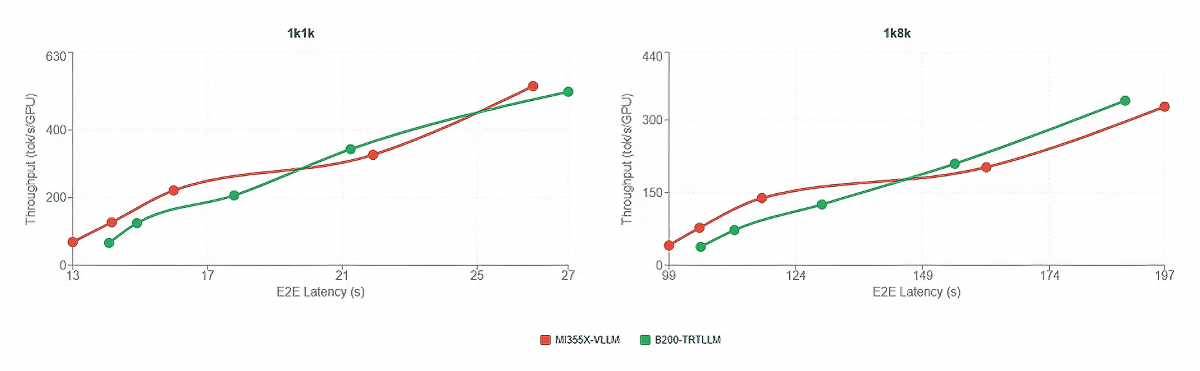
また、AMDも最適化に伴ってMI355X性能がB200に近づいていることをアピールし、「近い内に同等の性能を実現できる」と述べています。
InferenceMAXはオープンソースで開発されており、以下のリンク先でソースコードを確認できます。
GitHub - InferenceMAX/InferenceMAX
https://github.com/InferenceMAX/InferenceMAX
・関連記事
AIインフラのトレーニング性能を測定する「MLPerf Training v5.0」の結果が公開される、NVIDIAは前世代から2倍高速化&AMDは一部のテストでNVIDIAを上回る - GIGAZINE
AIインフラストラクチャの性能を測定するMLPerfのバージョン5.0が登場し「NVIDIA」「AMD」「Intel」などが結果を公開 - GIGAZINE
PCのAI性能を測定できるベンチマークアプリ「MLPerf Client」を世界的なAIベンチマーク機関「MLCommons」がリリース - GIGAZINE
スマホのAI処理性能を測定できるベンチマークアプリ「MLPerf Mobile」をMLCommonsがリリースしたので使ってみた - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1o_hf
You can read the machine translated English article The open-source benchmark 'InferenceMAX'….