The open-source benchmark 'InferenceMAX' has been released, measuring the performance of AI chips and publishing it daily, revealing the current state of AI chips that continue to rapidly advance with both NVIDIA and AMD support
InferenceMAX by SemiAnalysis
https://inferencemax.semianalysis.com/
InferenceMAX™: Open Source Inference Benchmarking
https://newsletter.semianalysis.com/p/inferencemax-open-source-inference
InferenceMAX Benchmarking Progress in Real Time
https://www.amd.com/en/developer/resources/technical-articles/2025/inferencemax-benchmarking-progress-in-real-time.html
NVIDIA Blackwell Raises the Bar in New InferenceMAX Benchmarks, Delivers Unparalleled Performance and Efficiency - NVIDIA | Blog
https://blogs.nvidia.co.jp/blog/blackwell-inferencemax-benchmark-results/
The performance of AI processing using an AI chip is not determined solely by the hardware performance of the AI chip itself; overall processing performance also changes with improvements in peripheral technologies such as AI frameworks and the processing engine (software) running on the AI chip. Therefore, continuous performance measurement is necessary to accurately grasp the processing performance of an AI chip. InferenceMAX is designed with continuous performance measurement in mind, and the latest daily updates can be viewed on the official website .
At the time of writing, InferenceMAX was tested on NVIDIA's GB200 NVL72, B200, H200, and H100 processors, as well as AMD's MI355X, MI325X, and MI300X processors, covering over 80% of the AI processing power already deployed worldwide. In addition, support for Google's TPU and Amazon's Trainium processors will be available soon, expanding the scope to over 99% of AI processing power.
Today we are launching InferenceMAX!
— Dylan Patel (@dylan522p) October 9, 2025
We have support from Nvidia, AMD, OpenAI, Microsoft, Pytorch, SGLang, vLLM, Oracle, CoreWeave, TogetherAI, Nebius, Crusoe, HPE, SuperMicro, Dell
It runs every day on the latest software (vLLM, SGLang, etc) across hundreds of GPUs, $10Ms of… https://t.co/3Bbsh3OANF
InferenceMAX uses three test models: 'Llama 3.3 70B Instruct', 'DeepSeek R1 0528', and 'gpt-oss 120B'. Each model is tested under three conditions: 'input 1000 tokens / output 1000 tokens', 'input 1000 tokens / output 8000 tokens', and 'input 8000 tokens / output 1000 tokens'. Two types of model accuracy are available: FP8 and FP4.
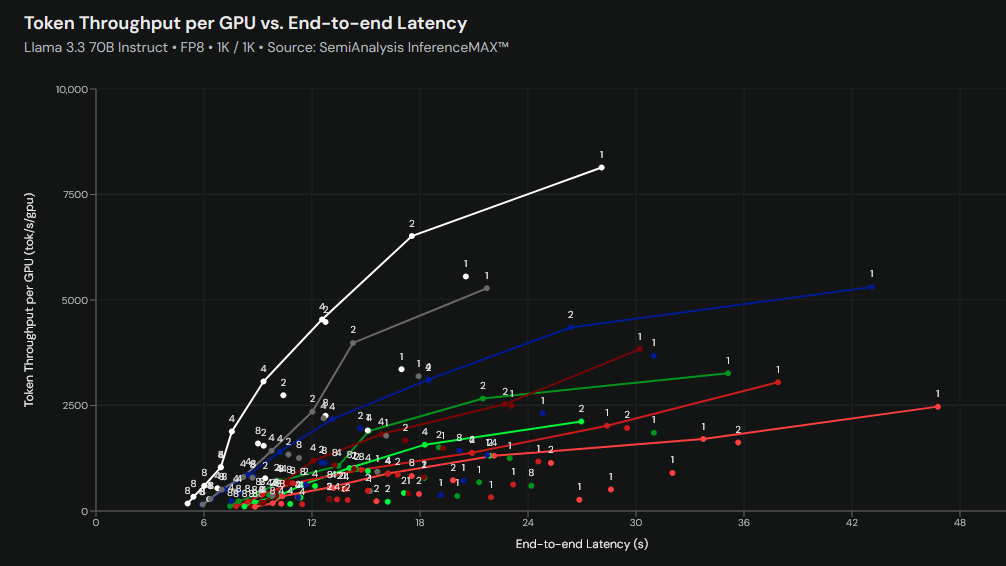
Below are the benchmark results as of 3:19:59 on October 12, 2025, for the Llama 3.3 70B Instruct, 1,000 tokens input, 1,000 tokens output, and FP8 configuration. The vertical axis shows the number of tokens processed per second per AI chip, and the horizontal axis shows the time it takes for the processing results to reach the user. Looking at the graph, we can see that NVIDIA's B200 performed well in both the number of tokens processed and the processing time.

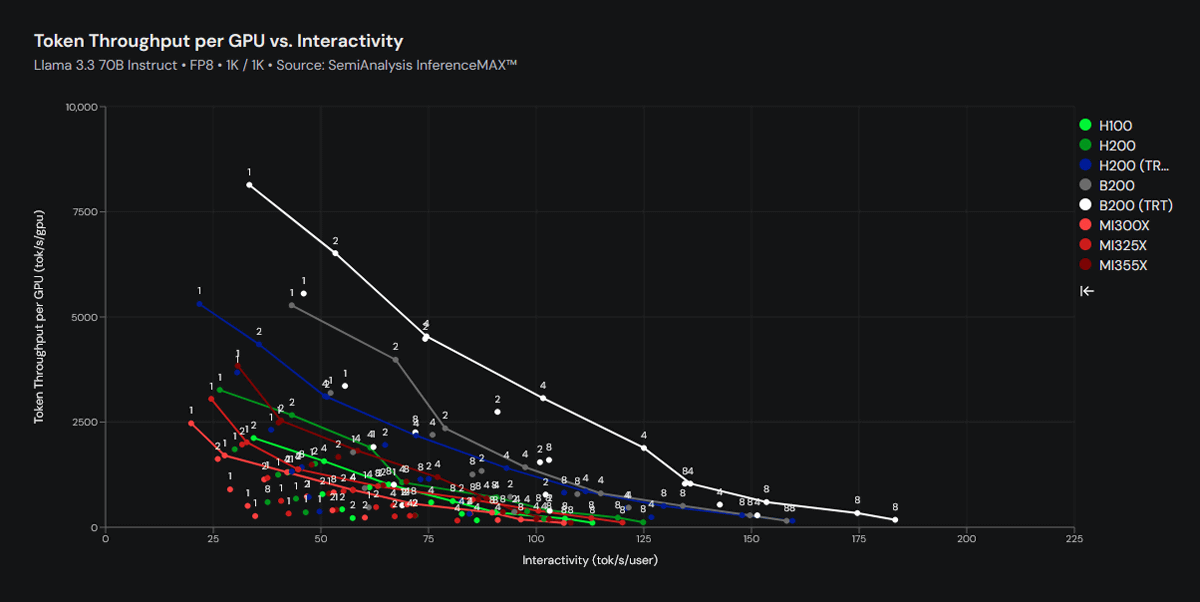
In the graph below, the vertical axis is the number of tokens processed per second per AI chip, and the horizontal axis is the number of tokens processed per second per user. In this graph, the B200 also records outstanding results.
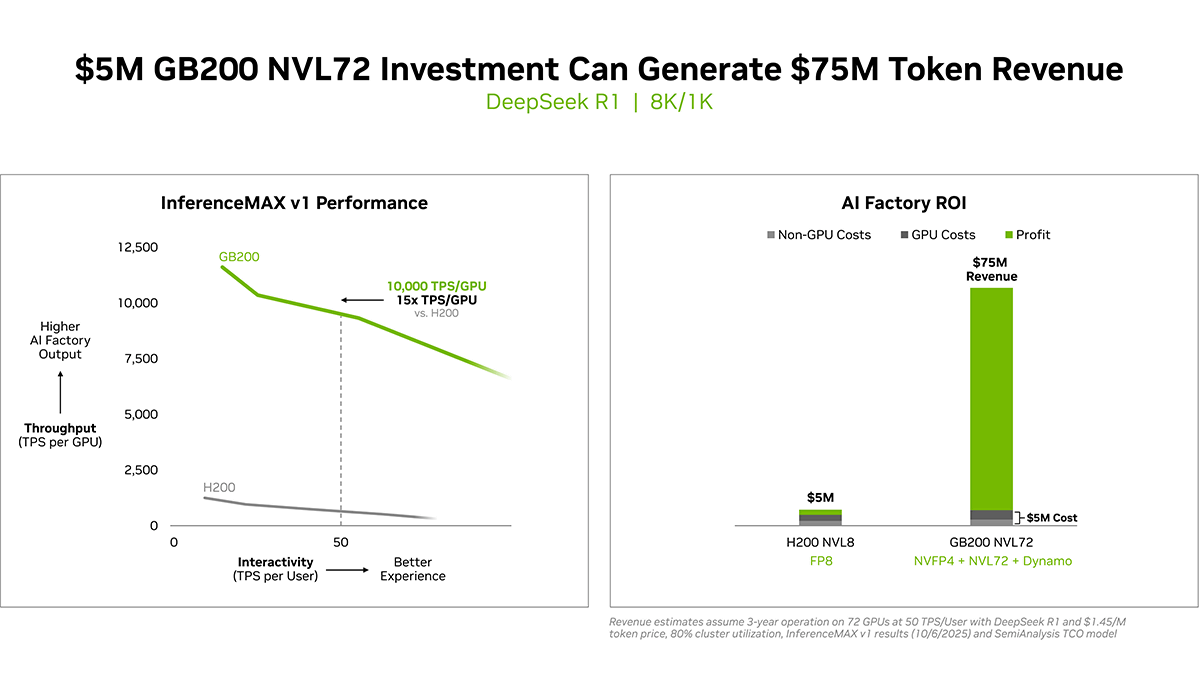
NVIDIA updated its official blog to coincide with the release of InferenceMAX, highlighting the superiority of the GB200 NVL72 over the H200 in both performance and cost performance.
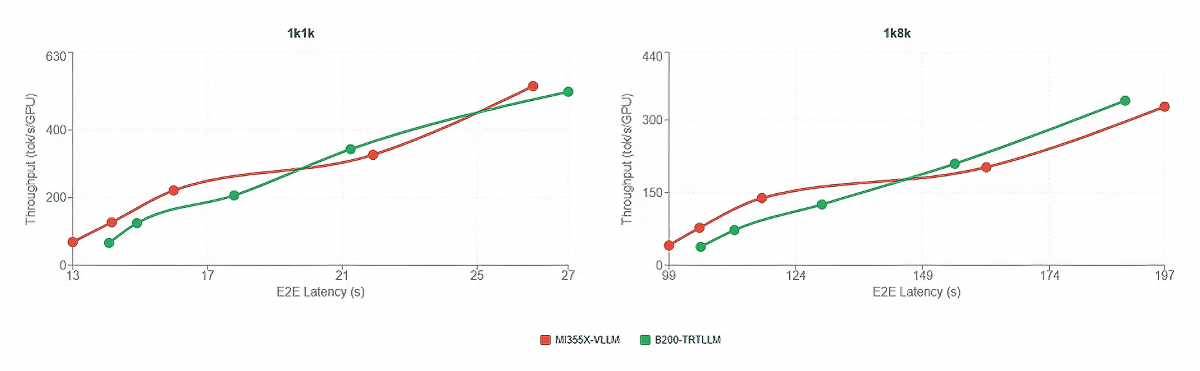
AMD also claims that the MI355X's performance is approaching that of the B200 due to optimizations, and that it will be able to achieve equivalent performance in the near future.
InferenceMAX is developed as open source, and the source code can be viewed at the following link.
GitHub - InferenceMAX/InferenceMAX
https://github.com/InferenceMAX/InferenceMAX
Related Posts:








in Software, Posted by log1o_hf