MLPerf version 5.0, which measures AI infrastructure performance, has been released, with results published by NVIDIA, AMD, Intel, and others.

MLCommons Releases New MLPerf Inference v5.0 Benchmark Results - MLCommons
https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/

1/ We are excited to announce the latest MLCommons MLPerf Inference v5.0 benchmark suite results. This round featured robust participation from 23 submitting organizations delivering over 17,000 performance results! https://t.co/vlrJcoz25t pic.twitter.com/6V56AjkRUq
— MLCommons (@MLCommons) April 2, 2025
MLPerf Inference is a benchmark that covers both data center and edge systems and measures how fast systems can run AI and machine learning (ML) models across a variety of workloads. MLPerf Inference is an open-source, peer-reviewed benchmark suite designed to create a level playing field to drive innovation, performance, and energy efficiency across the industry.
MLPerf Inference v5.0, the latest version of MLPerf Inference, includes new benchmark tests for Llama 3.1 405B, Llama 2 70B Interactive for low-latency applications, RGAT, and Automotive PointPainting for 3D object detection.
New benchmarks using Llama 3.1 405B have also been introduced. Llama 3.1 405B supports input and output of up to 128,000 tokens, allowing AI models to incorporate up to 405 billion parameters. The Llama 3.1 405B benchmark tests three tasks: general question-and-answering, mathematics, and code generation.

'Llama 2 70B Interactive for low-latency applications' adds low-latency requirements to the Llama 2 70B benchmark. This benchmark reflects industry trends such as conversational chatbots, next-generation reasoning systems, and agent systems, and requires the system under test (SUT) to meet more stringent system response metrics such as time to first token (TTFT) and time per output token (TPOT).
'RGAT' is a benchmark for data centers that implements the
'Automotive PointPainting for 3D object detection' is a new benchmark targeted at edge computing devices, specifically automobiles. It is part of a 'Minimum Viable Product' benchmark released in summer 2024 and provides a proxy for an important edge computing scenario: 3D object detection in camera feeds in applications such as self-driving cars.

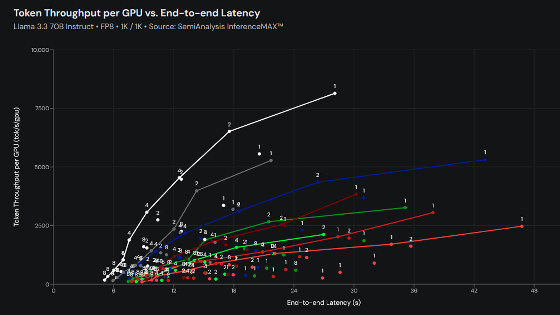
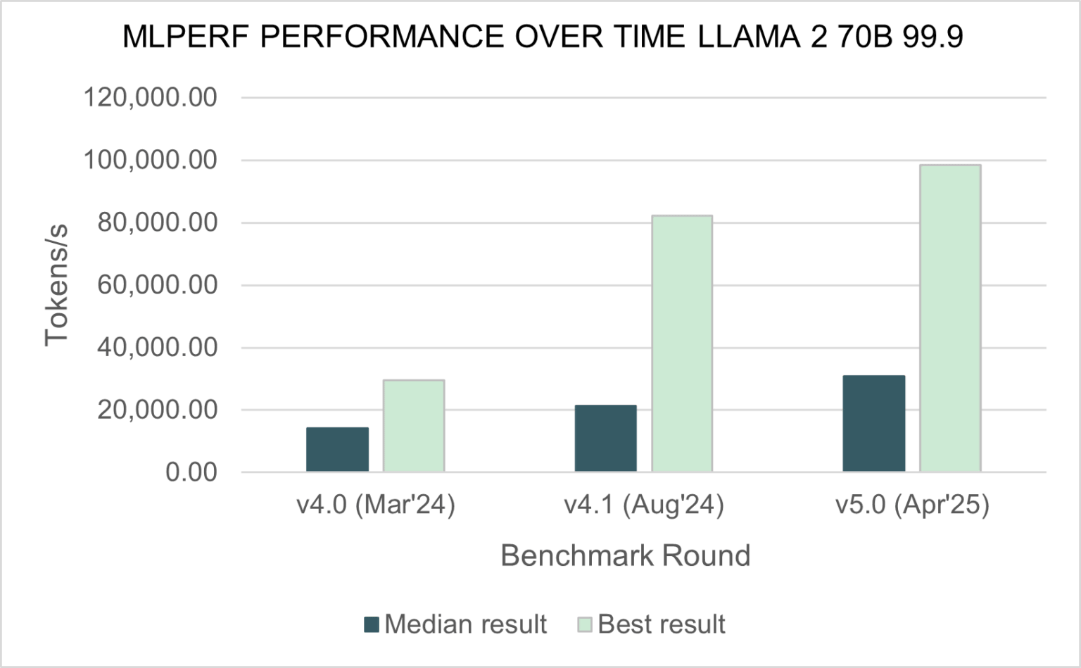
The MLPerf Inference v5.0 benchmark test using Llama 2 70B measures generative AI inference workloads. The rate of submissions for this test has increased 2.5x over the past year, and MLCommons has stated that 'generative AI is gaining momentum.'
Comparing test submission scores using Llama 2 70B with previous versions, the median score was 2x faster and the best score was 3.3x faster than Inference v4.0.
'Much of the ecosystem is tackling the adoption of generative AI head-on, and it's clear that a performance benchmark feedback loop is at work,' said David Kanter, MLPerf lead at MLCommons. 'We're seeing an unprecedented new generation of accelerators, paired with new software technologies, including hardware-software alignment support for the FP4 format. These advancements are driving the community to set new records in generative AI inference performance.'
The benchmark results also include benchmark scores for the following six processors that are either newly released or will soon be shipping:
AMD Instinct MI325X
・Intel Xeon 6980P
・Google TPU Trillium
・NVIDIA B200
・NVIDIA Jetson AGX Thor 128
・NVIDIA GB200

MLPerf Inference v5.0 includes 17,457 performance data submissions from 23 organizations: AMD, ASUSTeK, Broadcom, Cisco, CoreWeave, CTuning, Dell, FlexAI, Fujitsu, GATEOverflow, Giga Computing, Google, HPE, Intel, Krai, Lambda, Lenovo, MangoBoost, NVIDIA, Oracle, Quanta Cloud Technology, Supermicro, and Sustainable Metal Cloud.
Companies like NVIDIA, AMD, and Intel are touting their MLPerf Inference v5.0 scores on their blogs and newsrooms.
NVIDIA Blackwell Takes Pole Position in Latest MLPerf Inference Results | NVIDIA Blog
https://blogs.nvidia.com/blog/blackwell-mlperf-inference/
AMD Instinct GPUs Continue AI Momentum Across Indu... - AMD Community
https://community.amd.com/t5/instinct-accelerators/amd-instinct-gpus-continue-ai-momentum-across-industry/ba-p/756056
AMD InstinctTM MI325X GPUs Produce Strong Performance in MLPerf Inference v5.0 — ROCm Blogs
https://rocm.blogs.amd.com/artificial-intelligence/mi325x-accelerates-mlperf-inference/README.html
Intel Xeon Remains Only Server CPU on MLPerf - Intel Newsroom
https://newsroom.intel.com/data-center/intel-xeon-remains-only-server-cpu-mlperf
MLCommons also stated, 'The continuing growth of the submission community is a testament to the importance of accurate and reliable performance metrics to the AI community.' They also expressed their gratitude to the five new collaborators in MLPerf Inference v5.0: CoreWeave, FlexAI, GATEOverflow, Lambda, and MangoBoost, and their delight at the growth of the community.
Related Posts: