Systems equipped with NVIDIA's AI-specialized chip 'H100' topped all nine tests in the AI processing benchmark 'MLPerf Training 4.0'

MLPerf Training Benchmark - 1910.01500v3.pdf
(PDF file) https://arxiv.org/pdf/1910.01500
MLPerf Training Results Showcase Unprecedented Performance, Elasticity | NVIDIA Blog
https://blogs.nvidia.com/blog/mlperf-training-benchmarks/
Nvidia Conquers Latest AI Tests - IEEE Spectrum
https://spectrum.ieee.org/mlperf-nvidia-conquers
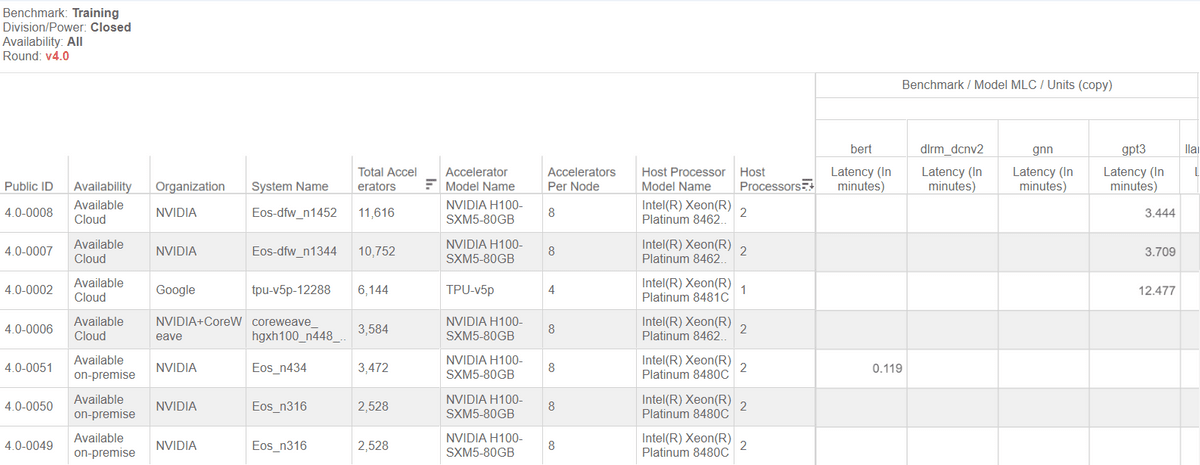
The benchmark results can be seen below.
Benchmark MLPerf Training | MLCommons Version 2.0 Results
https://mlcommons.org/benchmarks/training/
The top result was a system equipped with 11,616 NVIDIA H100 GPUs, the largest number ever. The largest system measured in 2023 was equipped with 3,584 H100s, about three times the size of the previous system. While it took 67 minutes to complete the GPT-3 training trial with 1,024 Intel hardware, the system equipped with 11,616 H100s completed it in less than three and a half minutes.
NVIDIA said, 'Stable Diffusion v2 training performance has also increased by up to 80% at the same system scale as the previous submission. These advances reflect numerous enhancements to the NVIDIA software stack and demonstrate how software and hardware improvements work hand in hand to deliver top-class performance.'
NVIDIA has made numerous optimizations to its software stack, and a system consisting of 512 H100s is up to 27% faster than a year ago. NVIDIA points out that this shows how continuous software enhancements can significantly improve performance, even with the same hardware.

MLPerf Training 4.0 introduces the first benchmarks for LoRA fine-tuning and GNN (Graph Neural Network) on LLama 2 70B. NVIDIA performed well in both, with the GPU scaled from 8 to 1024 GPUs completing the benchmark in 1.5 minutes. In GNN, the platform equipped with the H100 achieved a superior score, with the H200 achieving a 47% improvement over the H100 in single-node GNN training.
Regarding the H200, the successor to the H100, NVIDIA said, 'It builds on the strengths of the Hopper architecture with 141GB of HBM3 memory and 40% more memory bandwidth than the H100. Pushing the boundaries of what's possible in AI training, the H200 improved performance over the H100 by up to 47% in its debut MLPerf training.'
Related Posts:








in Hardware, Posted by log1p_kr