




AIインフラストラクチャの性能を測定するMLPerfのバージョン5.0が登場し「NVIDIA」「AMD」「Intel」などが結果を公開

ニューラルネットワークのパフォーマンス評価を実施する業界コンソーシアムのMLCommonsが、さまざまなAIモデルの推論スループットを測定するベンチマークスイートの最新バージョンである「MLPerf Inference v5.0」を公開しました。
MLCommons Releases New MLPerf Inference v5.0 Benchmark Results - MLCommons
https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/

1/ We are excited to announce the latest MLCommons MLPerf Inference v5.0 benchmark suite results. This round featured robust participation from 23 submitting organizations delivering over 17,000 performance results! https://t.co/vlrJcoz25t pic.twitter.com/6V56AjkRUq
— MLCommons (@MLCommons) April 2, 2025
MLPerf Inferenceはデータセンターとエッジシステムの両方を網羅し、システムがさまざまなワークロードでAIや機械学習(ML)モデルをどれだけ高速に実行できるかを測定するためのベンチマークです。MLPerf Inferenceはオープンソースの査読付きベンチマークスイートで、業界全体のイノベーション、パフォーマンス、エネルギー効率を促進するための公平な競争の場を作り出すためのものになっています。
MLPerf Inferenceの最新バージョンとなるMLPerf Inference v5.0では、新たに「Llama 3.1 405B」「Llama 2 70B Interactive for low-latency applications」「RGAT」「Automotive PointPainting for 3D object detection」でのベンチマークテストが実施されています。
「Llama 3.1 405B」を用いた新しいベンチマークも導入されています。Llama 3.1 405Bは最大12万8000トークンの入出力をサポートしているため、AIモデルに最大4050億のパラメーターを組み込むことが可能です。Llama 3.1 405Bのベンチマークでは一般的な質疑応答、数学、コード生成という3つのタスクがテストされます。

「Llama 2 70B Interactive for low-latency applications」は、Llama 2 70Bのベンチマークに低レイテンシー要件を追加するテストです。このベンチマークは対話型チャットボットや次世代推論システム、エージェントシステムといった業界トレンドを反映しており、被試験システム(SUT)に対して最初のトークンまでの時間(TTFT)や出力トークンあたりの時間(TPOT)といった、より厳しいシステム応答指標を満たすことが要求されます。
「RGAT」はGNNモデルを実装したデータセンター向けのベンチマークです。
「Automotive PointPainting for 3D object detection」は、エッジコンピューティングデバイス、特に自動車を対象とした新しいベンチマークです。2024年夏に発表された「Minimum Viable Product」ベンチマークに関するもので、自動運転車などのアプリケーションにおけるカメラフィードの3Dオブジェクト検出という、重要なエッジコンピューティングシナリオのプロキシを提供します。

MLPerf Inference v5.0におけるLlama 2 70Bを用いたベンチマークテストでは、生成AIの推論ワークロードが測定されています。同テストに関するベンチマークスコアの提出率は過去1年間で2.5倍に増加しており、MLCommonsは「生成AIが勢いを増している」と評しています。
Llama 2 70Bを用いたテストの提出スコアを過去のバージョンと比較すると、中央値は2倍、ベストスコアはInference v4.0と比べて3.3倍も高速になりました。
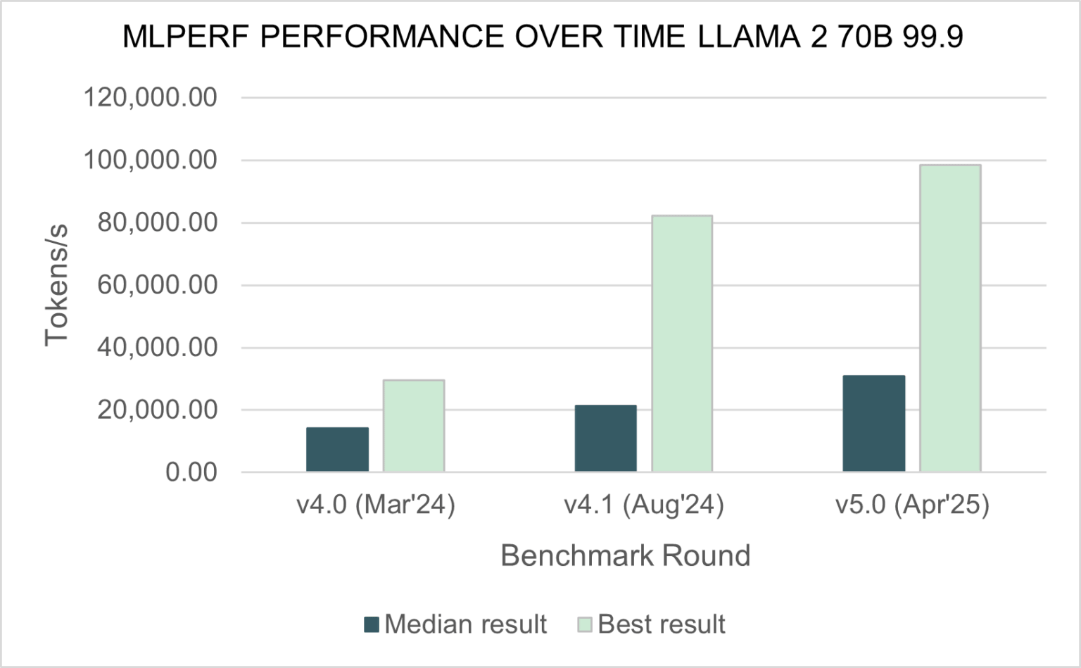
MLCommonsでMLPerfの責任者を務めるDavid Kanter氏は、「エコシステムの多くが、生成AIの導入に正面から取り組んでおり、パフォーマンスベンチマークのフィードバックループが機能していることは明らかです。前例のない新世代のアクセラレータが氾濫しており、ハードウェアはFP4フォーマットのハードウェアとソフトウェア間の整合サポートを含む、新しいソフトウェア技術とペアになっています。これらの進歩により、コミュニティは生成AI推論性能の新記録を打ち立てようとしています」と語りました。
なお、今回のベンチマーク結果には新たに発売された、あるいは間もなく出荷される以下の6つのプロセッサのベンチマークスコアも含まれています。
・AMD Instinct MI325X
・Intel Xeon 6980P
・Google TPU Trillium
・NVIDIA B200
・NVIDIA Jetson AGX Thor 128
・NVIDIA GB200

MLPerf Inference v5.0には、23の組織から1万7457件のパフォーマンスデータが提出されています。MLPerf Inference v5.0に協力した企業はAMD、ASUSTeK、Broadcom、Cisco、CoreWeave、CTuning、Dell、FlexAI、富士通、GATEOverflow、Giga Computing、Google、HPE、Intel、Krai、Lambda、Lenovo、MangoBoost、NVIDIA、Oracle、Quanta Cloud Technology、Supermicro、Sustainable Metal Cloudの23社です。
NVIDIA、AMD、Intelといった企業は自社のブログやニュースルームでMLPerf Inference v5.0のスコアをアピールしています。
NVIDIA Blackwell Takes Pole Position in Latest MLPerf Inference Results | NVIDIA Blog
https://blogs.nvidia.com/blog/blackwell-mlperf-inference/
AMD Instinct GPUs Continue AI Momentum Across Indu... - AMD Community
https://community.amd.com/t5/instinct-accelerators/amd-instinct-gpus-continue-ai-momentum-across-industry/ba-p/756056
AMD InstinctTM MI325X GPUs Produce Strong Performance in MLPerf Inference v5.0 — ROCm Blogs
https://rocm.blogs.amd.com/artificial-intelligence/mi325x-accelerates-mlperf-inference/README.html
Intel Xeon Remains Only Server CPU on MLPerf - Intel Newsroom
https://newsroom.intel.com/data-center/intel-xeon-remains-only-server-cpu-mlperf
なお、MLCommonsは「提出コミュニティが成長を続けていることは、AIコミュニティにとって正確で信頼できる性能指標が重要であることの証です」と語り、MLPerf Inference v5.0から新しく協力しているCoreWeave、FlexAI、GATEOverflow、Lambda、MangoBoostの5社への感謝とコミュニティの成長に対して喜びのコメントを記しています。
・関連記事
GoogleのAI処理チップ「Trillium」がGoogle Cloud経由で利用可能に、旧世代TPUと比べて4倍の学習性能を発揮 - GIGAZINE
AMDが帯域幅6.0TB/sの256GBメモリを搭載したAIアクセラレータ「Instinct MI325」を発表、NVIDIAのH200を一部のテストで打ち負かす - GIGAZINE
NVIDIAが数兆パラメータ規模のAIモデルを実現するGPUアーキテクチャ「Blackwell」と新GPU「B200」を発表 - GIGAZINE
AMDがデータセンター部門の収益で初めてIntelを上回る - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article MLPerf version 5.0, which measures AI in….