




GoogleのAI処理チップ「Trillium」がGoogle Cloud経由で利用可能に、旧世代TPUと比べて4倍の学習性能を発揮

2024年5月に発表されたGoogleの第6世代TPU「Trillium(v6e)」が、Google Cloudのユーザー向けに一般提供されたことがわかりました。Trilliumは以前のモデルと比べてパフォーマンスが4倍、エネルギー効率が67%向上しています。
Trillium TPU is GA | Google Cloud Blog
https://cloud.google.com/blog/products/compute/trillium-tpu-is-ga?hl=en
TPU v6e | Google Cloud
https://cloud.google.com/tpu/docs/v6e
Trilliumは5月のGoogle I/O 2024で発表された第6世代TPUで、前世代のTPU v5eと比較してチップ当たりのピークパフォーマンスが4.7倍に、高帯域幅メモリ(HBM)の容量と帯域幅が2倍に増加するなどさまざまな進化を遂げました。
Googleは「TrilliumはGoogle CloudのAIハイパーコンピューターの主要コンポーネントであり、パフォーマンスに最適化されたハードウェア、オープンソフトウェア、MLフレームワークを採用した画期的なスーパーコンピュータアーキテクチャです」と紹介しています。
Googleが第6世代TPU「Trillium」発表、TPU v5eよりも1チップ当たり4.7倍優れたパフォーマンスと67%優れたエネルギー効率でGoogle CloudのAIを支える - GIGAZINE

このTrilliumが、一般ユーザーにも提供され始めました。Googleは、Trilliumを使用することで「AIトレーニングワークロードの拡張」「高密度なモデルとMixture of Experts(MoE)モデルを含むLLMのトレーニング」「推論パフォーマンスとコレクションスケジューリング」など幅広いワークロードで優れた性能を享受できるとアピールしています。
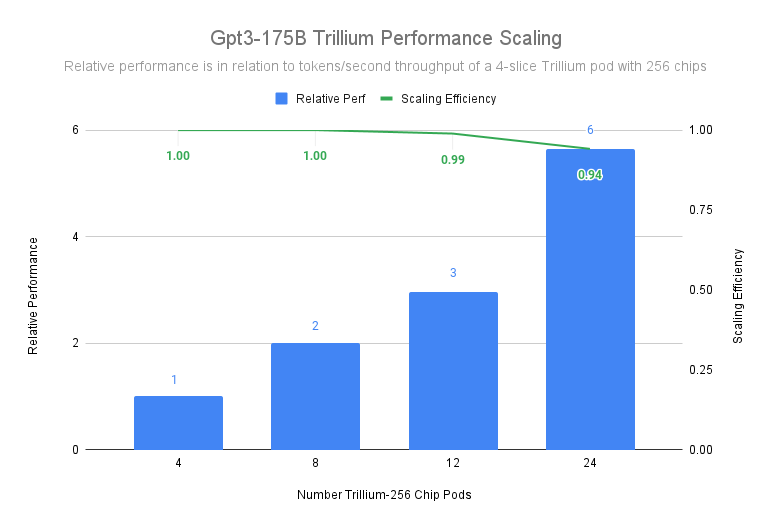
AIトレーニングワークロードの拡張の例では、以下のようにgpt3-175bモデルの事前トレーニングのスケーリング効率が示されています。Trilliumは1つのポッドあたり256個のチップがあり、これを12個使用した場合、スケーリング効率は最大99%を達成。24個使用した場合でも94%の効率を維持しています。
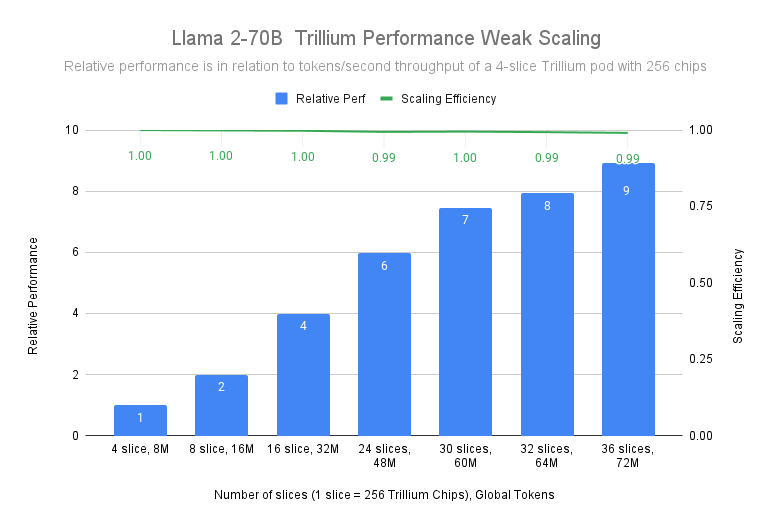
Llama-2-70Bモデルのトレーニングでは、4スライスのTrillium-256チップポッドから36スライスのTrillium-256チップポッドまで、99%のスケーリング効率でほぼ直線的なスケーリングを達成することが実証されました。
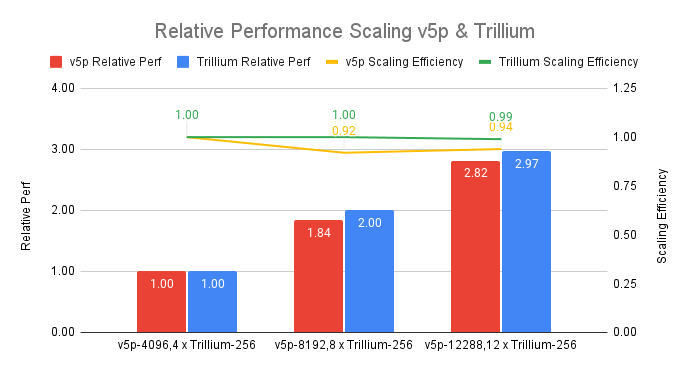
また、同等規模の前モデルのv5pと比較した場合でも、Trilliumはより優れたスケーリング効率を示します。
このTrilliumは同日発表された「Gemini 2.0」のトレーニングにも使われています。Geminiのような大規模言語モデル(LLM)は数十億のパラメータを持つためトレーニングが複雑で、膨大な計算能力を必要とします。Googleによると、前々モデルのv5eと比較すると、Trilliumは高密度LLMのgpt3-175bに対して3.24倍、Llama-2-70bに対して最大4倍高速なトレーニングを実現するとのことです。

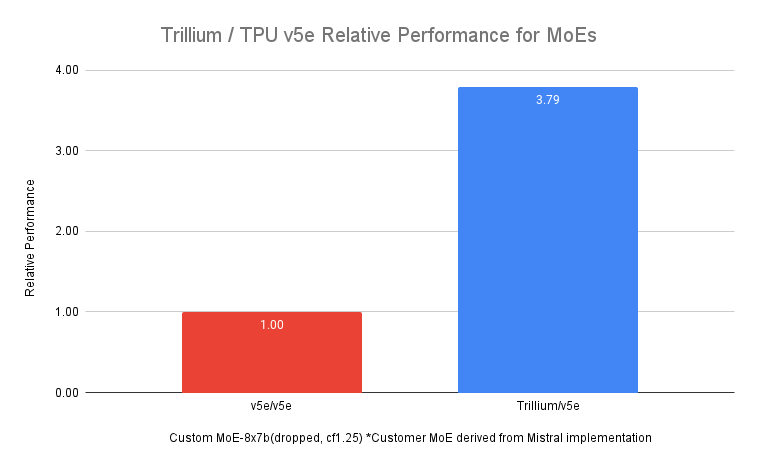
また、Mixture of Experts(MoE)という機械学習の手法でLLMをトレーニングすることが一般的になっていますが、トレーニング中に管理・調整するのはより複雑だといいます。Trilliumはこの複雑さを緩和し、v5eと比較してMoEモデルのトレーニングを最大3.8倍高速化します。
さらに、Trilliumはv5eと比べて3倍のホストDRAMを提供します。Googleは「これは、計算の一部をホストにオフロードし、スケール時のパフォーマンスとグッドプットを最大化するのに役立つ」と述べています。
推論時のマルチステップ推論の重要性が高まっていることを受け、Trilliumは推論ワークロードで大きく進歩しており、v5eと比較してStable Diffusion XLの相対推論スループット(秒間生成画像数)が3倍以上、Llama2-70Bの相対推論スループット(秒間処理トークン数)が2倍近く向上しています。オフラインとサーバー推論の両方のユースケースで最高のパフォーマンスを発揮するのも特徴で、オフライン推論だと相対スループットがv5eの3.11倍、サーバー推論だと2.9倍になります。
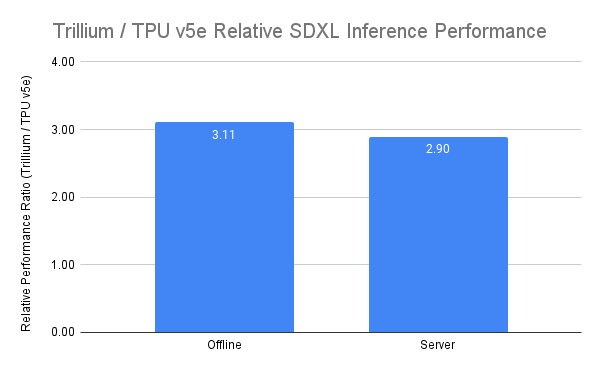
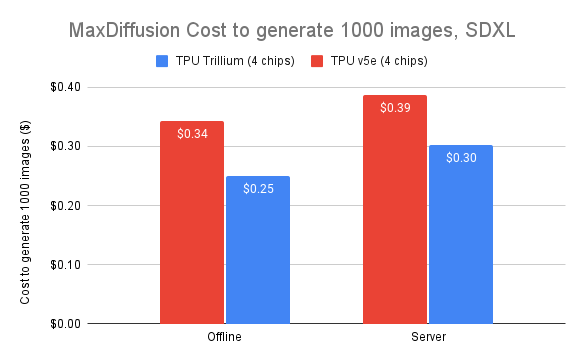
1ドル当たりのコストパフォーマンスも高く、v5eと比較して1ドルあたり最大2.1倍の性能向上、v5pと比較して1ドルあたり最大2.5倍の性能向上を実現しています。Trilliumで1000枚の画像を生成するコストは、オフライン推論ではv5eより27%低く、サーバー推論ではv5eより22%低いとのことです。
Trilliumを収納したサーバーの実物は以下の動画で紹介されています。
Trillium TPU, built to power the future of AI - YouTube

ケースを開けるGoogleスタッフ。

中にボードがあります。

これがTrillium。

Googleは「TrilliumはGoogle CloudのAIインフラストラクチャを大きく飛躍させ、さまざまなAIワークロードに驚異的なパフォーマンス、スケーラビリティ、効率性を提供します。世界トップクラスの共同設計ソフトウェアを使用して数十万チップまで拡張できるTrilliumは、より迅速なブレークスルーの達成と優れたAIソリューションの提供を可能にします」と述べました。
・関連記事
Google DeepMindが最大15日先までの天気予報をより迅速かつ正確に提供するAIモデル「GenCast」を発表 - GIGAZINE
Googleがチップ設計AI「AlphaChip」を発表、すでにスマホ向けチップやAI特化チップの設計で活躍 - GIGAZINE
Googleが第6世代TPU「Trillium」発表、TPU v5eよりも1チップ当たり4.7倍優れたパフォーマンスと67%優れたエネルギー効率でGoogle CloudのAIを支える - GIGAZINE
GoogleがArmベースのCPU「Axion」を発表 - GIGAZINE
GoogleがAI向けチップ「TPU v5p」を発表、前世代から最大2.8倍の性能向上で「Gemini」のトレーニングにも使用される - GIGAZINE
・関連コンテンツ







in AI, 動画, ハードウェア, Posted by log1p_kr
You can read the machine translated English article Google's AI processing chip 'Trilliu….