




Python向けの機械学習ライブラリ「PyTorch」とは何かをわかりやすく解説
PyTorchはMeta AI(旧Facebook AI)によって開発されたオープンソースのディープラーニング用フレームワークであり、現在はLinux Foundationの一部となっています。このライブラリは、記事作成時点で開発が終了しているTorchライブラリを基盤として構築されました。テクノロジー系のブロガーであるObyteが、PyTorchの基本的な構成要素からニューラルネットワークの実装までを視覚的に解説しています。
Introduction to PyTorch | 0byte
https://0byte.io/articles/pytorch_introduction.html
Visual Introduction to PyTorch - YouTube
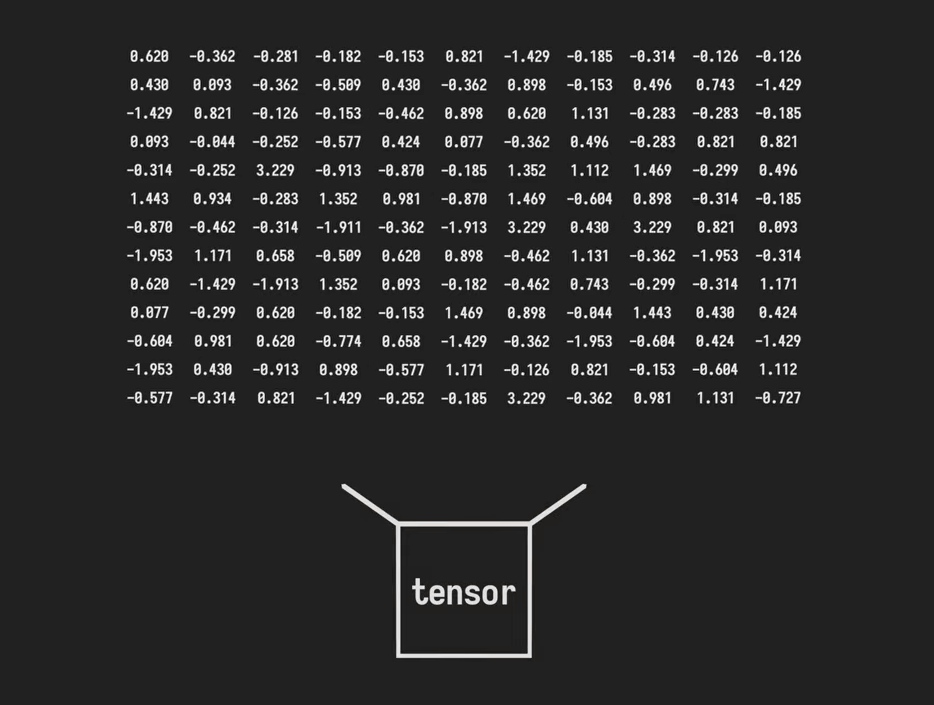
PyTorchの最も基本的な構成要素はテンソルと呼ばれるデータ型です。これは機械学習で扱う数値を格納するための特殊な容器であり、通常のリストや配列をより強力にした多次元配列のようなものです。
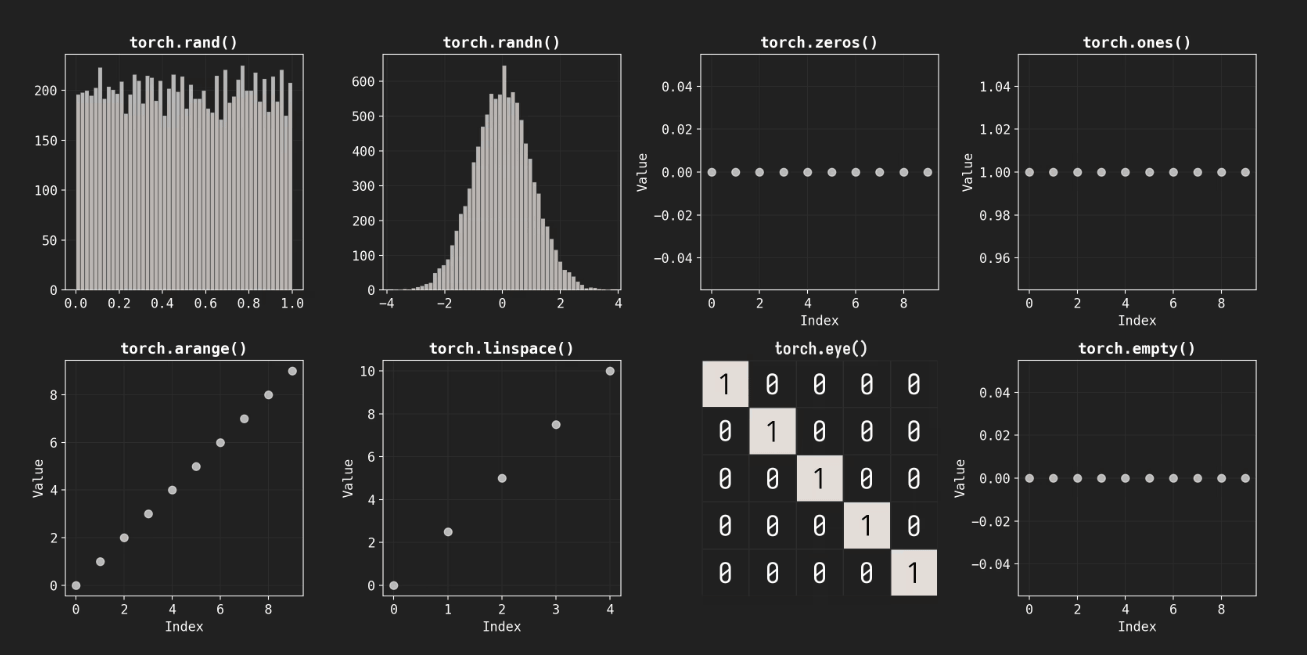
テンソルの初期化には様々な関数が用意されており、0から1の間の乱数を生成するtorch.rand()や、0を中心に正規分布する乱数を得るtorch.randn()、すべての要素を1にするtorch.ones()などがあります。また、0で埋めるtorch.zeros()や単位行列を作るtorch.eye()、メモリの割り当てのみを行って値を初期化しないtorch.empty()といった用途に応じた使い分けが可能です。
現実世界のあらゆるデータは、PyTorchで計算を行うために数値表現へと変換される必要があります。文章データであれば、最もシンプルな手法として各単語に固有のIDを割り当てて数値化し、画像データであればRGBの色情報を持つピクセルのグリッドとしてテンソル化します。たとえば、28×28ピクセルのグレースケール画像は[28, 28]の形状を持つテンソルとなり、3Dメッシュデータであれば頂点のx/y/z座標を保持する[1000, 3]のような形状で管理されます。
PyTorchには100種類以上の演算があらかじめ定義されており、四則演算のほか、合計値を求めるsum()や平均値を求めるmean()といった集約操作を簡単に行えます。また、ニューラルネットワークにおいて重要な役割を果たす活性化関数も豊富に用意されています。たとえば、最も一般的なReLUは負の値を0に置き換える関数であり、Sigmoidは値を0から1の間に、Tanhは値を-1から1の間に正規化する特性を持っています。
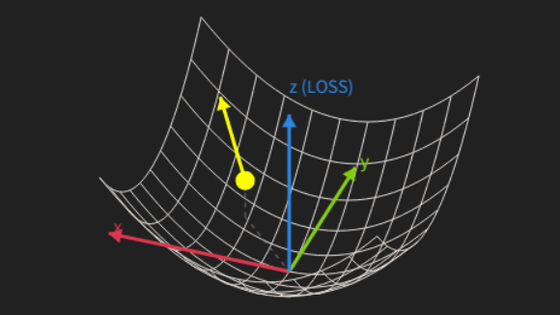
PyTorchの計算能力を支える中心的な機能が、自動微分エンジンであるautogradで、ニューラルネットワークのエンジンとも称される重要な機能です。微分は科学や工学のあらゆる場面で利用される基本的な計算であり、関数がある変数に対してどのように変化するかを記述します。
たとえば以下の放物線f(x)=x2に接する直線の傾きは、f(x)を微分することで求めることができます。この直線の傾きf'(x)は、xに対応したf(x)の瞬間的な変化率を示しているといえます。

そして、勾配はすべての変数に対する微分の集合であり、あらゆる方向における傾斜を一度に示します。数百万のパラメータを持つ現代のネットワークを視覚化することは困難ですが、autogradを利用することでこれらの複雑な微分計算をGPUの支援を受けて高速に自動実行することが可能です。
モデルの学習には、勾配降下法などのアルゴリズムが用いられます。数百万ものパラメータを持つ現代のネットワークでも、autogradとGPUの支援によって、人間が手計算を行うことなく高速に学習を進めることが可能です。
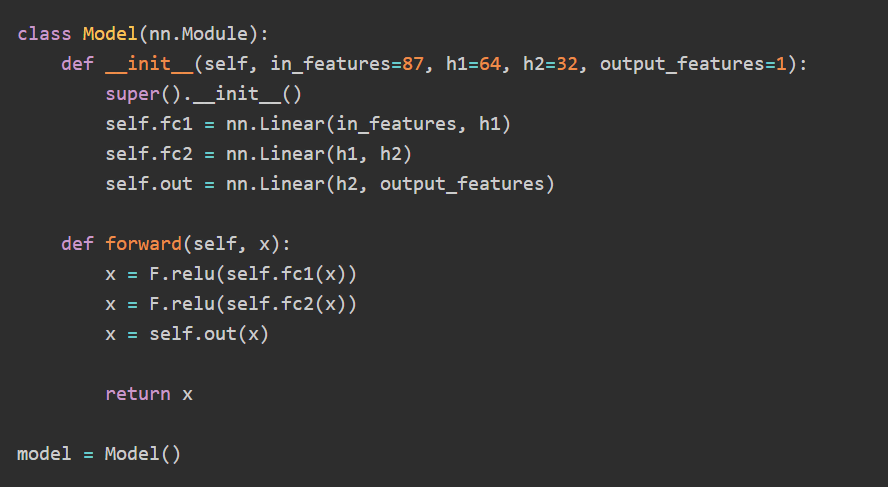
実際のモデル構築では、nn.Moduleを継承したクラスを定義してネットワークの構造を記述します。ロンドンの物件価格予測を例に取ると、87個の特徴量を入力し、2つの隠れ層を経て最終的な価格を出力するモデルが構成されます。
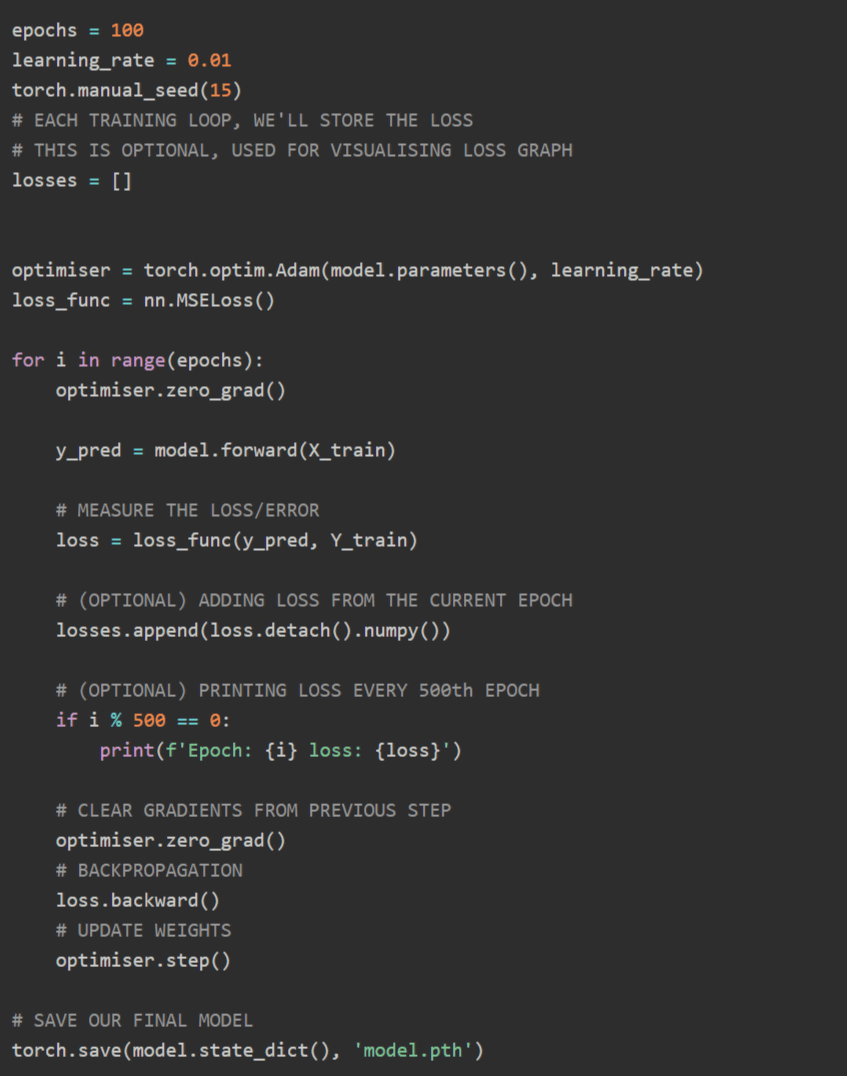
学習ループでは、データをモデルに通して予測を得る順伝播、予測の誤りを測定する損失計算、autogradによる逆伝播、そしてAdamなどの最適化アルゴリズムによる重みの更新という手順を数百回から数千回繰り返します。
このモデルを100エポックにわたって学習させた結果、未知のデータに対する平均絶対誤差(MAE)は33.0万ポンド(約6600万円)となりました。平均絶対誤差率(MAPE)は18.6%であり、予測値の誤差が10.0%以内に収まったケースは全体の37.0%だったとObyte氏は報告しています。
ここまでの処理プロセスを経て、データの準備から訓練、評価までを一貫して行えるのがPyTorchの特徴。ただし、Obyte氏は「最終的な精度はモデルの構造以上に、適切な特徴量(データ)の質に依存します。これが機械学習の現実です」と述べています。
・関連記事
AI開発の重要基盤「PyTorch」の発明者がMetaを退職 - GIGAZINE
PyTorchやPythonなしの純粋なC言語を使用した大規模言語モデルトレーニングツール「llm.c」がリリースされる - GIGAZINE
これからの時代を生き抜くITスキルとしての「Python」で立身出世は可能なのか? - GIGAZINE
AIの仕組みであるLLMの「ブラックボックス」の内部を見てどのニューラルネットワークが特定の概念を呼び起こすかを知る試みをAnthropicが解説 - GIGAZINE
畳み込みニューラルネットワークの処理についてアニメーションで解説する「Animated AI」 - GIGAZINE
・関連コンテンツ





in AI, 動画, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article This article provides a clear explanatio….