This article provides a clear explanation of PyTorch, a machine learning library for Python.
PyTorch is an open-source deep learning framework developed by Meta AI (formerly Facebook AI) and is now part of the Linux Foundation. This library was built on the Torch library, which is no longer under development at the time of writing. Technology blogger Obyte provides a visual explanation of PyTorch, from its basic components to the implementation of neural networks.
Introduction to PyTorch | 0byte
Visual Introduction to PyTorch - YouTube
The most fundamental building blocks of PyTorch are data types called tensors. These are special containers for storing numerical values used in machine learning, and are like multidimensional arrays that are more powerful than regular lists or arrays.
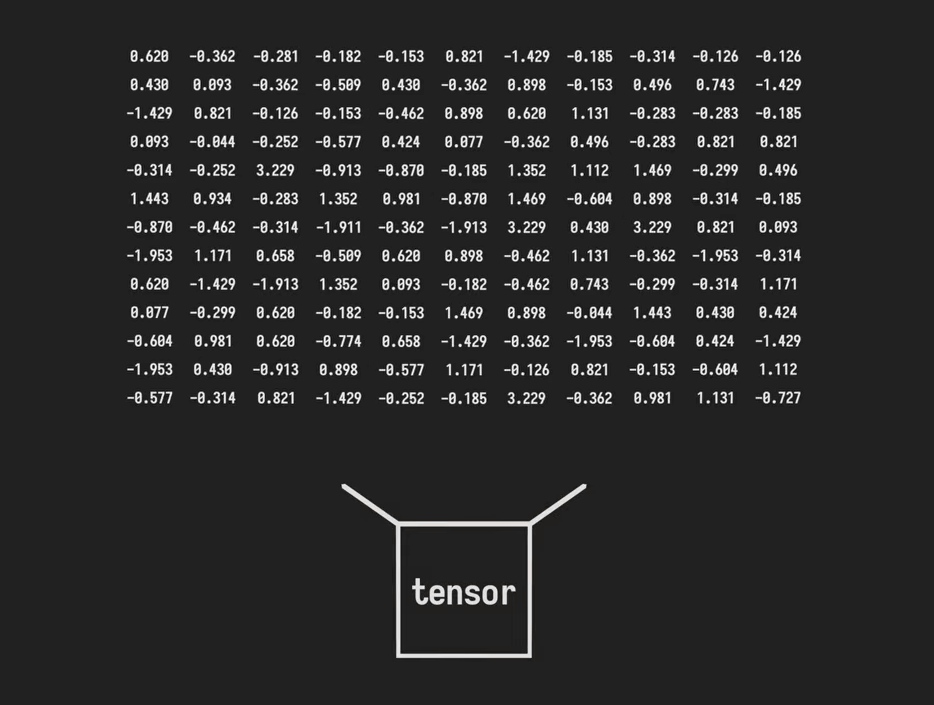
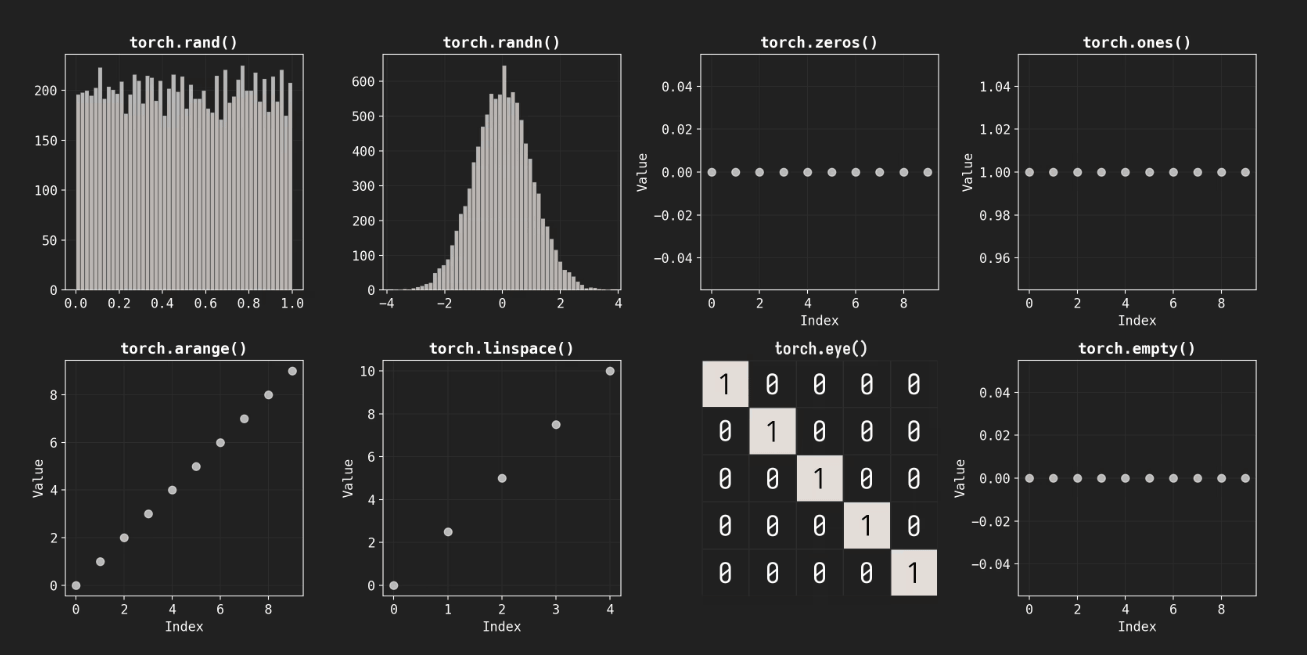
Various functions are available for initializing tensors, including torch.rand() which generates random numbers between 0 and 1, torch.randn() which obtains normally distributed random numbers centered around 0, and torch.ones() which sets all elements to 1. In addition, you can use torch.zeros() to fill with zeros, torch.eye() to create an identity matrix, and torch.empty() which only allocates memory and does not initialize the values, depending on the application.
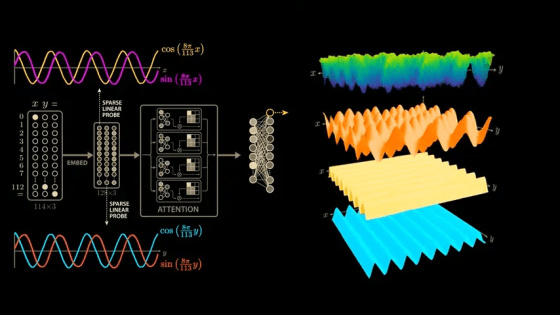
All data from the real world needs to be converted into a numerical representation in order to be computed in PyTorch. For text data, the simplest method is to assign a unique ID to each word and convert it to a numerical value, and for image data, it is converted into a tensor as a grid of pixels that hold RGB color information. For example, a 28x28 pixel grayscale image becomes a tensor with the shape [28, 28], and 3D mesh data is managed with a shape like [1000, 3] that holds the x/y/z coordinates of the vertices.
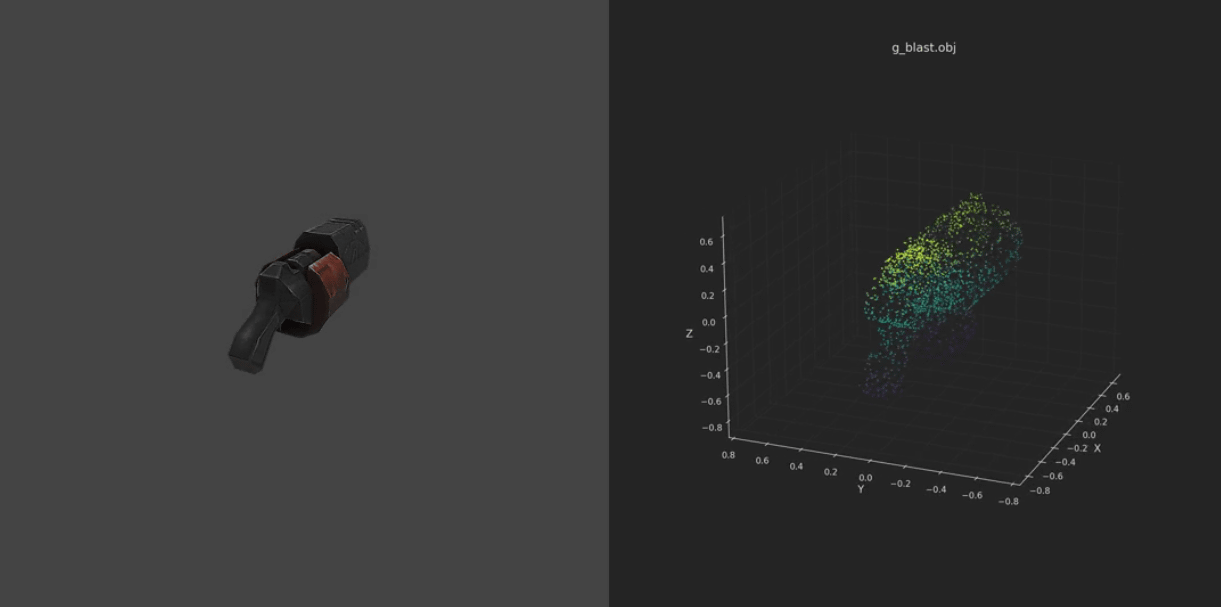
PyTorch comes with over 100 predefined operations, making it easy to perform basic arithmetic operations as well as aggregation operations such as sum() for calculating the sum and mean() for calculating the average. It also provides a wide range of activation functions that play an important role in neural networks. For example, the most common ReLU function replaces negative values with 0, Sigmoid normalizes values between 0 and 1, and Tanh normalizes values between -1 and 1.
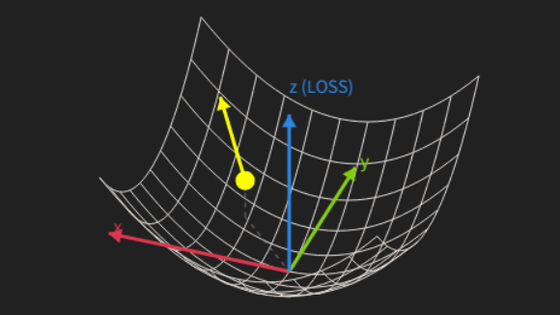
The core function supporting PyTorch's computational power is the autograd automatic differentiation engine, also known as the engine of neural networks. Differentiation is a fundamental calculation used in all aspects of science and engineering, describing how a function changes with respect to a given variable.
For example, the slope of a line tangent to the following parabola f(x) = x² can be found by differentiating f(x). The slope f'(x) of this line can be said to represent the instantaneous rate of change of f(x) corresponding to x.

The gradient is the set of derivatives with respect to all variables, and it shows the slope in all directions at once. Visualizing modern networks with millions of parameters is difficult, but autograd makes it possible to automate these complex differential calculations at high speed with the help of a GPU.
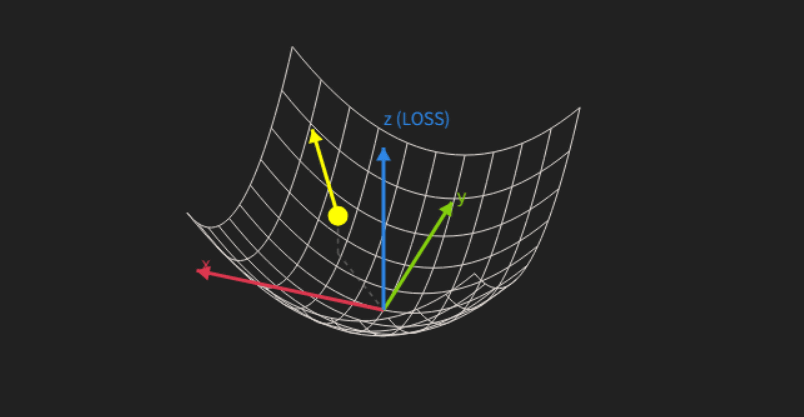
Model training utilizes algorithms such as gradient descent. Even with modern networks containing millions of parameters, the use of autograd and GPU assistance allows for rapid training without manual calculations.
In actual model construction, you define a class that inherits from nn.Module to describe the network structure. Taking London property price prediction as an example, a model is constructed that takes 87 features as input, processes them through two hidden layers, and outputs the final price.
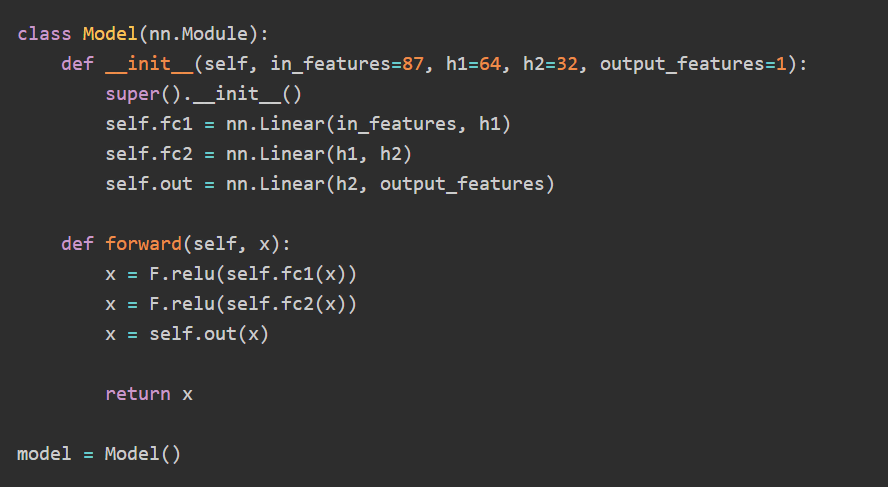
The learning loop repeats the following steps hundreds to thousands of times: forward propagation, which involves passing data through the model to obtain predictions; loss calculation, which measures the error in the predictions; backpropagation using autograd; and weight updates using optimization algorithms such as Adam.
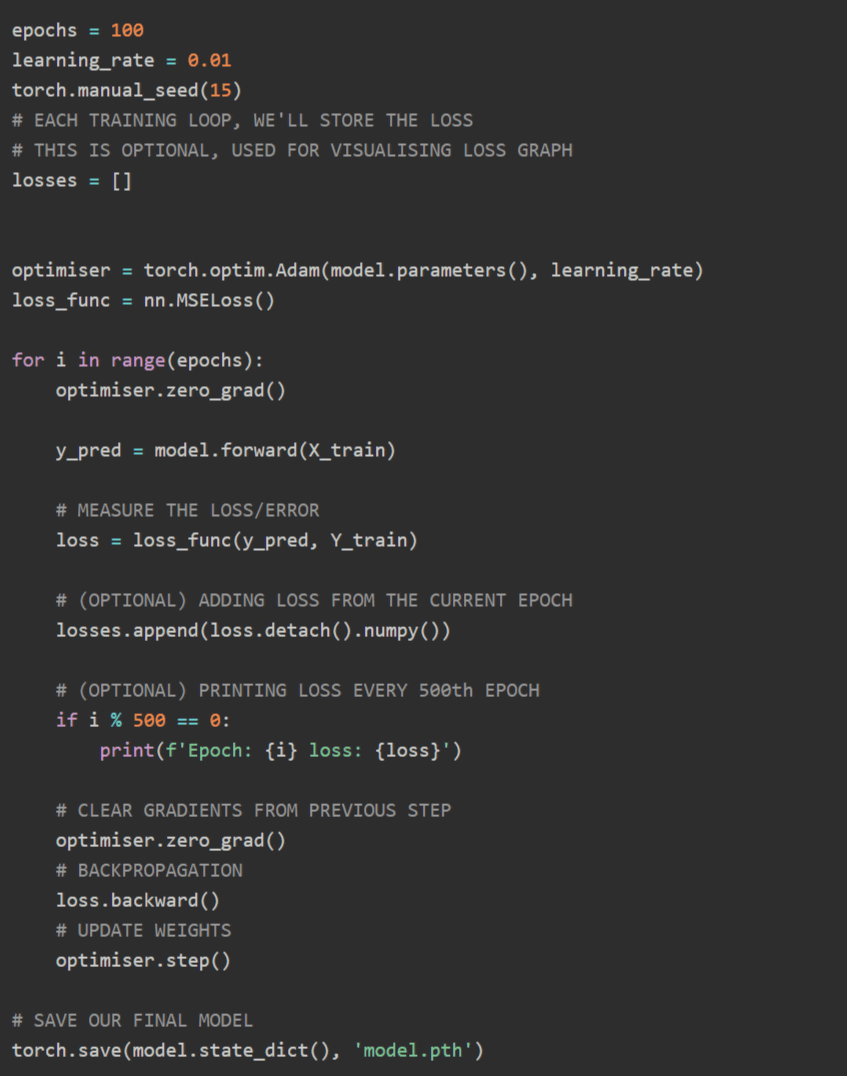
After training this model for 100 epochs, the mean absolute error (MAE) for unknown data was £330,000 (approximately 66 million yen). The mean absolute rate of error (MAPE) was 18.6%, and Obyte reports that in 37.0% of cases, the error in the predicted value was within 10.0%.
The key feature of PyTorch is that it allows you to perform the entire process from data preparation to training and evaluation in a single, integrated manner. However, Obyte states, 'The final accuracy depends more on the quality of the appropriate features (data) than on the structure of the model. This is the reality of machine learning.'
Related Posts: