




Metaがモバイルデバイスで実行できる軽量な量子化Llamaモデルをリリース

Metaが展開する大規模言語モデルの「Llama 3.2」ファミリーにおいて、初の軽量な量子化モデルがリリースされました。既存の性能をほとんど維持しながら推論速度やメモリの使用量が大きく改善されています。
Introducing quantized Llama models with increased speed and a reduced memory footprint
https://ai.meta.com/blog/meta-llama-quantized-lightweight-models/

Metaは2024年9月26日にLlama 3.2ファミリーを公開。11B・90Bという大きなモデルに加え、1B・3Bというモバイルデバイス向けの小さなモデルも用意されていました。
Metaが「Llama 3.2」を公開、画像認識性能が向上&スマホ特化の小型版もあり - GIGAZINE

今回、MetaはLlama 3.2の1Bモデルおよび3Bモデルについて、部分ごとに4bitから8bitの量子化を行いました。トレーニング時に量子化の影響を考慮する量子化認識トレーニング(QAT)を行った後、LoRAアダプターを適用して教師付きファインチューニングを行う「QLoRA」という手法を用いることで、ほとんど性能を維持しつつモデルの軽量化に成功したとのこと。
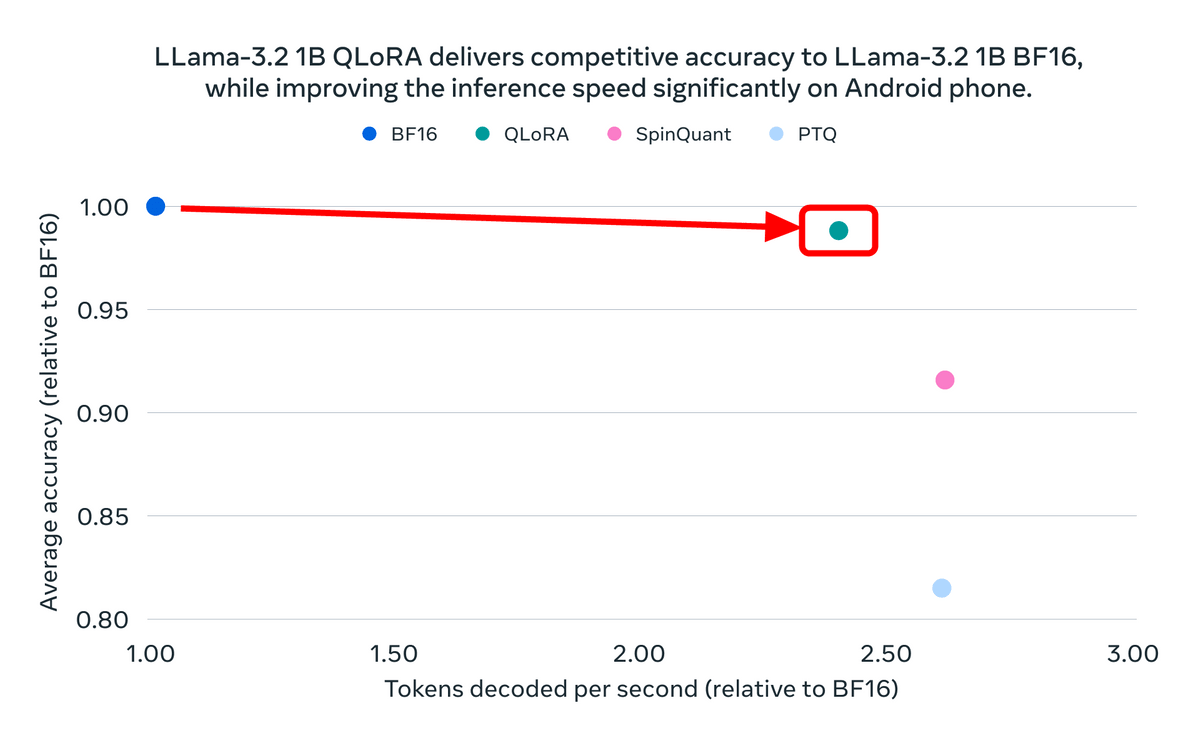
下図はLlama 3.2の1Bモデルについて、量子化前の元のモデルである「BF16」を1として、精度とトークンのデコード速度を比較したもの。QLoRAは精度をわずかに落としながらもデコード速度を約2.5倍まで引き上げていることが分かります。また、SpinQuantおよびPTQという別の手法はQLoRA以上の速度を達成できたものの精度が下がってしまっていることも読み取れます。
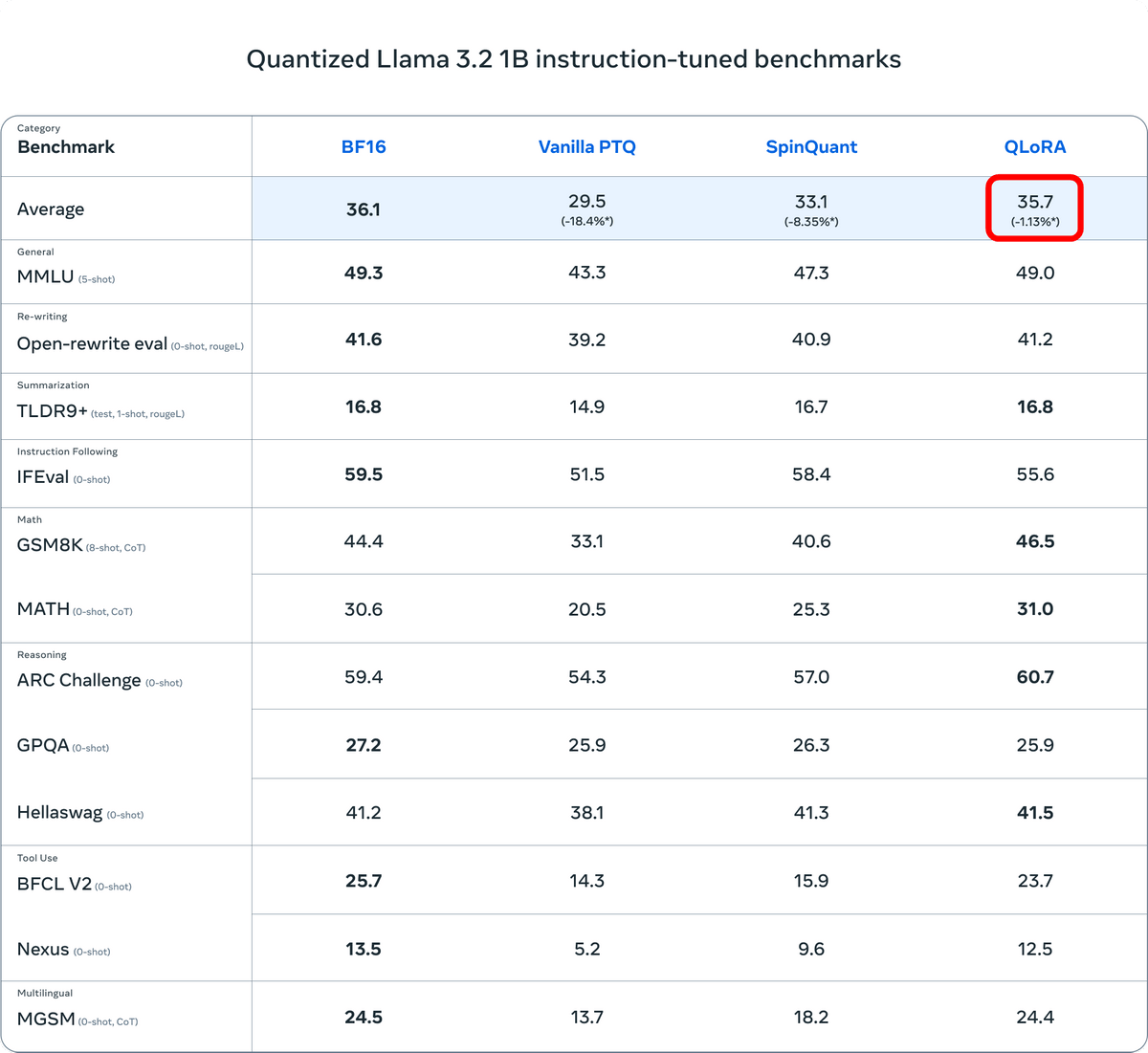
具体的な各種ベンチマークの値は下図の通り。平均スコアを見ると、QLoRAはBF16に比べて1.13%低下してしまいました。
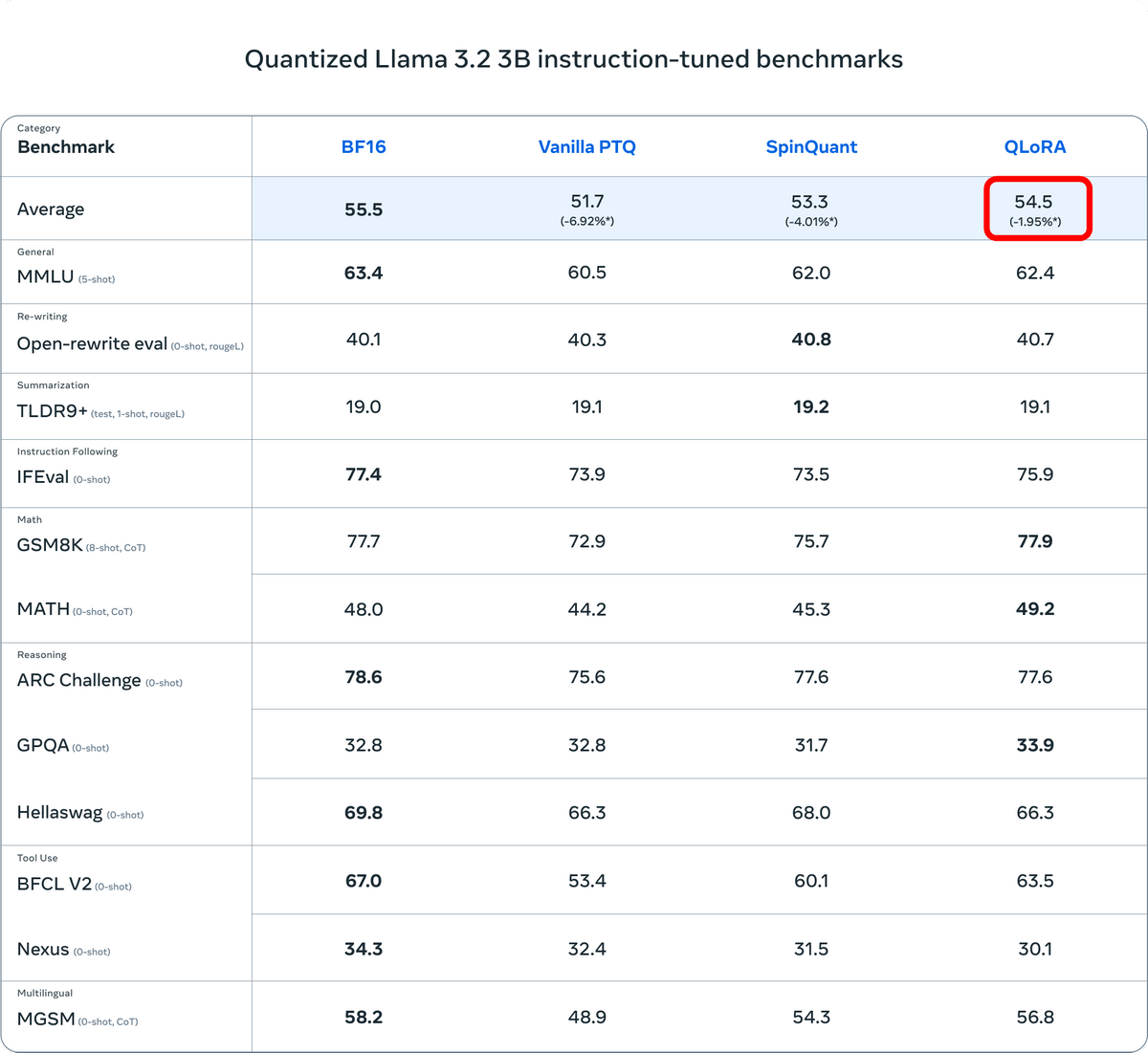
Llama 3.2の3Bモデルでも、QLoRAはBF16に比べて1.95%の性能低下が発生したとのこと。
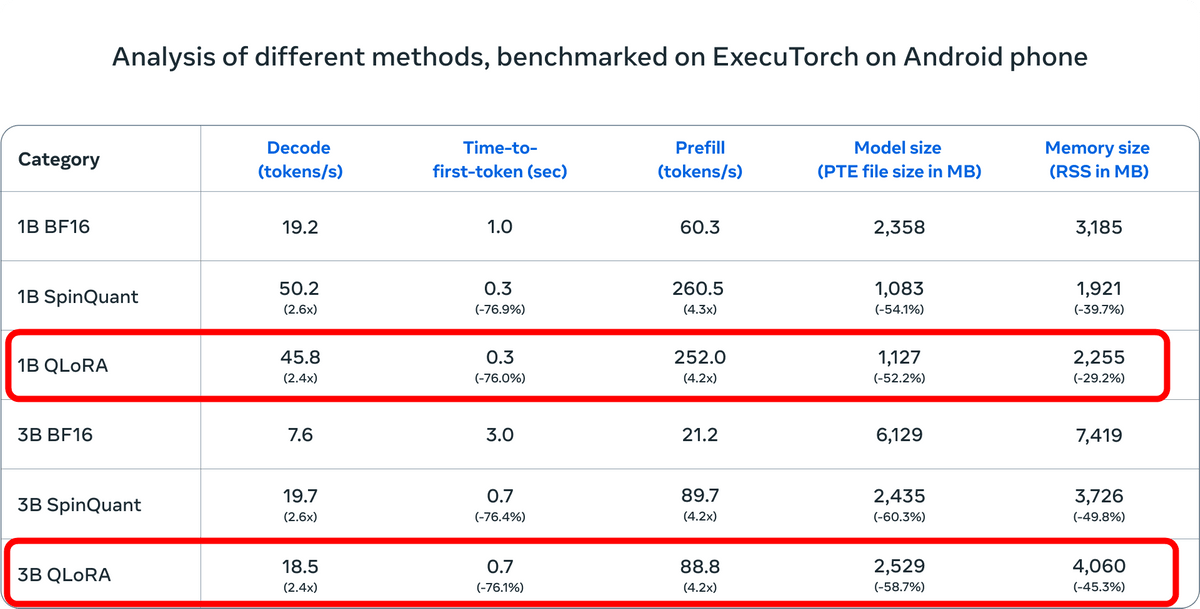
一方、トークンのデコード速度はどちらのモデルも2.4倍になったほか、最初のトークンが生成されるまでにかかる時間は76%減少。入力トークンを並列処理するPrefillを使う場合の速度は4.2倍になり、モデルのサイズは半分以下になりました。推論中に使用するメモリの量は1Bモデルで約30%減少し、3Bモデルでは約45%減少するという結果に。
今回リリースされたモデルはLlamaの公式サイトおよびHugging Faceからダウンロード可能です。
・関連記事
Metaの大規模言語モデル「Llama」の累計ダウンロード数が3億5000万回に迫る - GIGAZINE
なぜ研究者はローカルPCでAIを実行する必要があるのか? - GIGAZINE
OpenAIのGPTシリーズ・MetaのLlama・BigScienceのBLOOMのような新しくて大きなバージョンの大規模言語モデルを使ったAIは無知を認めるよりも間違った答えを与える傾向が強い - GIGAZINE
Metaが「Llama 3.2」を公開、画像認識性能が向上&スマホ特化の小型版もあり - GIGAZINE
Mistral AIがデバイス向け小規模モデル「Ministral 3B」「Ministral 8B」をリリース - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Meta releases lightweight quantized Llam….