




自然言語ライブラリ「wordfreq」がAIで汚染され更新不可能になったと作者が報告

さまざまなデータベースをもとに、自然言語の使用頻度を調べるためのPythonライブラリが「wordfreq」です。そんなwordfreqが、「AIで汚染され更新不可能となってしまった」と開発者のRobyn Speer氏が報告しています。
wordfreq/SUNSET.md at master · rspeer/wordfreq · GitHub
https://github.com/rspeer/wordfreq/blob/master/SUNSET.md
wordfreqがデータベースとして利用しているのは、2021年までにオンライン上で公開されていた自然言語のスナップショットです。しかし、「2021年以降、人間の使用言語に関する信頼できる情報を持っている人がいなくなった」ことを理由にwordfreqを更新することができなくなったとSpeer氏が報告しました。
記事作成時点で、インターネット上には大規模言語モデル(LLM)によって生成されたコンテンツが溢れています。これについて、Speer氏は「LLMの生成物は何のコミュニケーションも目的としない、誰によって書かれたものでもない、非常に雑多なものです。これをwordfreqのデータに含めてしまうと、単語の使用頻度データが歪んでしまいます」と語りました。
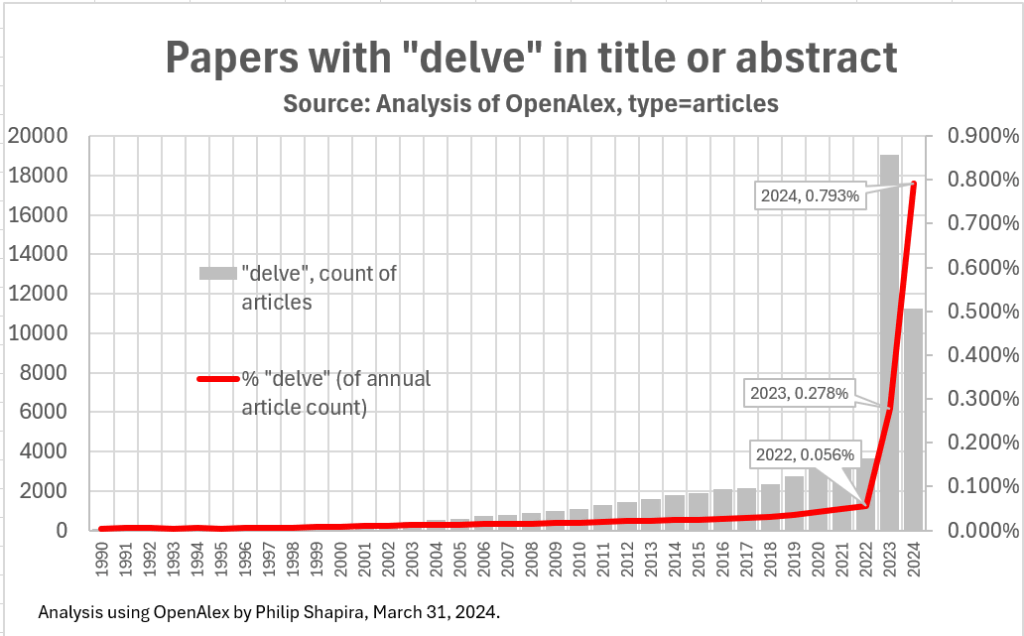
既存のwordfreqのデータベースにもスパムは含まれていたものの、これは管理が可能で、多くの場合簡単に識別することができたそうです。一方で、LLMの出力は「意図がないにもかかわらず、過剰な偏りが発生するケースがある」模様。この具体例のひとつが、チャットAIの代名詞となっているChatGPTがなぜか過剰に使用する「delve」(掘り下げる)という単語です。
以下は「delve」というフレーズを含むウェブページや記事のタイトルの数を調査したデータ。2022年までは全体の0.056%と非常に出現頻度が低かった「delve」が、ChatGPTの登場により2024年には0.793%にまで出現頻度を上げています。
元々、wordfreqは正式な印刷物だけでなく、X(旧Twitter)やRedditといったソーシャルメディア上のテキストもデータベースとしています。これは、より会話的な言語の使用法に関するデータを収集するという意図からです。
Twitterが全公開ツイートデータをまとめた「firehose」への無料アクセスを許可した時でさえ、使用条件によりSpeer氏はデータを収集した会社(Luminoso)の外部にデータを配布することは許可されていませんでした。そのため、wordfreqにはfirehoseのデータを入力として構築した「単語の使用頻度データ」が含まれているものの、データそのものは含まれていません。ただし、TwitterはXに変わり、firehoseへのアクセスも完全に遮断されています。
現状のXについて、Speer氏は「Xは寡頭政治家のおもちゃ、スパムだらけの右翼の汚水溜めとなってしまいました。Xが生のデータフィードを公開したとしても、そこに価値がある情報が見つかるとは思えません」と記し、Xがデータソースとしての価値を失ってしまったことを「wordfreqの更新が不可能となった理由のひとつ」として挙げています。
さらに、Redditも公開データアーカイブの提供を停止してしまいました。

このような状況を受け、Speer氏は「かつてwordfreqは私の興味の中心地で、自然言語処理ツールに役立つような方法でコーパス言語学について学習していました。しかし、私がかつて『自然言語処理』と呼んでいた分野は、最近ではもはや見当たりません。生成AIに飲み込まれてしまいました。他の技術もまだ存在しますが、生成AIが話題を独占し、資金もすべて奪い取ってしまいます。私の嫌いなOpenAIとGoogleが管理するクローズドデータに依存しない自然言語研究はめったにありません」と記し、この分野について研究することに疲れてしまったと語っています。
wordfreqは多くの言語、大量のテキストを収集して構築された自然言語データベースです。これは、作成時としてはかなり合理的な方法を採用しており、当時は誰かから反対されるようなこともなかったそうです。しかし、記事作成時点ではこの種のデータベースは生成AIのトレーニングに使用されるため、人々は懐疑的な目を向けるようになっています。
そのため、Speer氏は「生成AIと混同される可能性のあるものや、生成AIに利益をもたらす可能性のあるものに取り組みたくありません。OpenAIとGoogleは、独自のデータを収集できます。そのために非常に高い代償を払わなければならないことを望みますし、自らが引き起こした混乱を絶えず呪っていることを望みます」と記しました。
・関連記事
AI成果物が急増したことで「AI生成コンテンツをAIが学習するループ」が発生し「モデルの崩壊」が起きつつあると研究者が警告 - GIGAZINE
AIモデルのトレーニングにAI生成データを使用するとAIが物事を忘却してしまう「モデル崩壊」が起きるという指摘 - GIGAZINE
AIが偽の研究を量産する「論文工場」との戦いが激化している - GIGAZINE
中国で大量生産される「ニセ論文」が学術誌を汚染している - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article The author reports that the natural lang….