The author reports that the natural language library 'wordfreq' has been contaminated by AI and cannot be updated

'
wordfreq/SUNSET.md at master · rspeer/wordfreq · GitHub
https://github.com/rspeer/wordfreq/blob/master/SUNSET.md
The database that wordfreq uses is a snapshot of natural language that was publicly available online up until 2021. However, Speer reported that wordfreq could no longer be updated because 'after 2021, no one had reliable information about human language use.'
At the time of writing, the Internet is full of content generated by large-scale language models (LLMs). Speer said, 'The products of LLMs are very miscellaneous, not written by anyone, and have no communication purpose. If we included them in the wordfreq data, it would distort the word frequency data.'
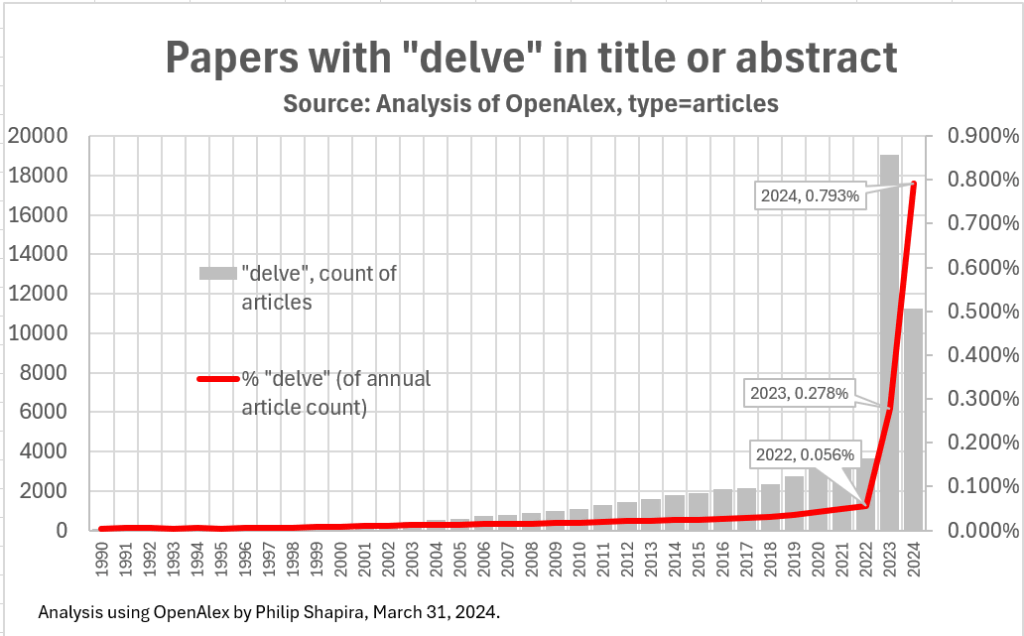
Although the existing wordfreq database also contained spam, it was manageable and in many cases easily identifiable. On the other hand, the output of LLM seems to be 'unintentionally biased in some cases.' One concrete example of this is the word ' delve ' (to dig deep), which is overused by ChatGPT, a chat AI.
Below is data on the number of webpage and article titles containing the phrase 'delve.' Until 2022, 'delve' had a very low occurrence rate of 0.056% of the total, but with the emergence of ChatGPT, its occurrence rate increased to 0.793% in 2024.
Originally, wordfreq's database included not only formal print texts, but also texts from social media sites such as Twitter and Reddit, with the intention of collecting data on more conversational language usage.
Even when Twitter allowed free access to the 'firehose,' a compilation of all public tweet data, the terms of use did not allow Speer to distribute the data outside of the company that collected it (Luminoso). Therefore, while wordfreq contains 'word frequency data' built using the firehose data as input, it does not contain the data itself. However, Twitter has changed to X and completely blocked access to the firehose.
Regarding the current state of X, Speer wrote, 'X has become a plaything for
Additionally, Reddit has also stopped providing its public data archive.

In response to this situation, Speer wrote, 'Wordfreq used to be the center of my interests, learning about corpus linguistics in a way that would inform natural language processing tools. But what I used to call 'natural language processing' is no longer around these days. It's been swallowed up by generative AI. Other technologies still exist, but generative AI dominates the conversation and steals all the funding. It's rare to see natural language research that doesn't rely on closed data managed by OpenAI and Google, which I hate.' He said he was tired of studying the field.
Wordfreq is a natural language database built by collecting a large amount of text from many languages. This was a fairly reasonable method for its creation, and no one seemed to object to it at the time. However, at the time of writing, this kind of database is used to train generative AI, so people are becoming skeptical.
So Speer said, 'I don't want to work on anything that could be confused with or benefit generative AI. OpenAI and Google can collect their own data. I hope they have to pay a very high price for it, and constantly curse the mess they've caused.'
Related Posts: