Google's data set 'C4' used for learning interactive AI contains a large amount of problematic content such as 4chan and white supremacist sites

A huge dataset `` Colossal Clean Crawled Corpus (C4) '' created by Google is used for AI training, including the large-scale language model ``
See the websites that make AI bots like ChatGPT sound so smart - Washington Post
https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
Starting with OpenAI's ChatGPT, conversational AI
In order to investigate this black box, The Washington Post conducted an analysis of C4 in collaboration with the non-profit research institute Allen Institute for Artificial Intelligence .
The Washington Post used data from Internet analytics firm Similarweb to categorize the sites that were the source of C4 information, and found that about 5 million of the 15 million sites were hidden and had no content. was unknown.
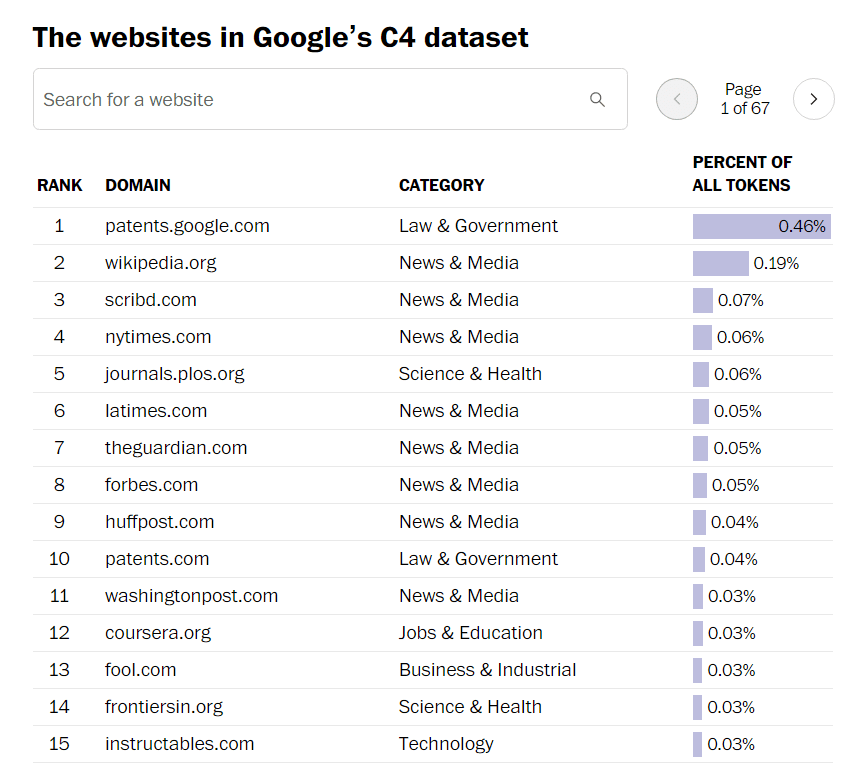
And when we examined the remaining two-thirds, the breakdown of the site is as follows: 16% for 'business and industry', 15% for 'technology', and 13% for 'news and media'. I understand.

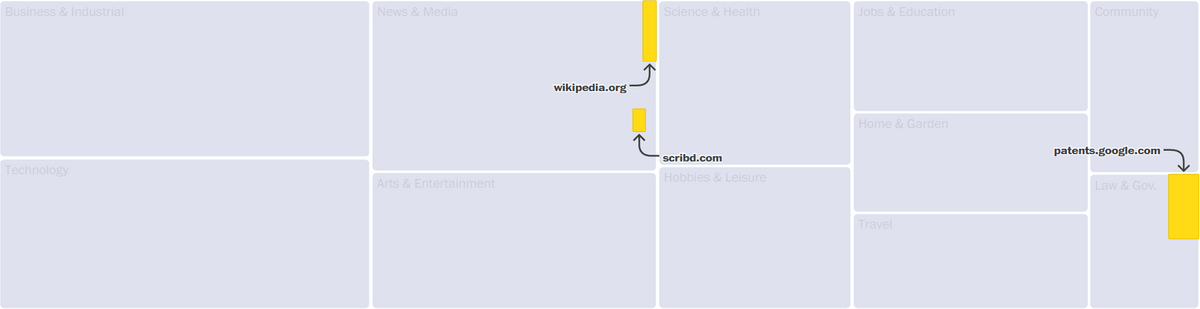
The largest source of data was 'patents.google.com', Google's patent literature search service that aggregates patent texts from around the world. After second place, the free online encyclopedia `` wikipedia.org '' and the subscription service `` scribd.com '' containing e-books and audio books followed. Also in 190th place was 'b-ok.org', which is notorious as a site that trades pirated e-books.
In 25th place was the crowdfunding site 'kickstarter.com', and in 2398th place was the artist support platform 'patreon.com'. Among the artists and creators active on the Internet, there are many who do not feel comfortable with having their content learned or copied by AI. and

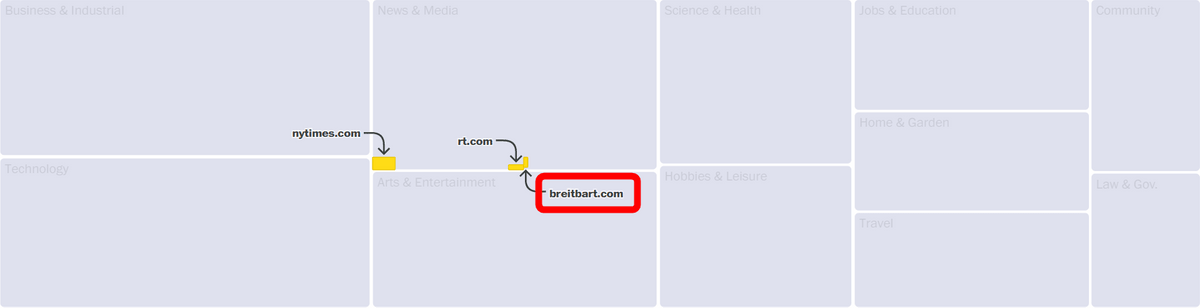
In particular, The Washington Post is concerned with contamination with harmful data such as discriminatory content. Among the third largest data category, ``news and media,'' ``breitbart.com (159th),'' an alternative right-wing media that deals with news about white supremacy, and ``vdare,'' an anti-immigrant site .com (ranked 993)' etc.
C4 also includes kiwifarms.net (ranked 378,986), which is the domain of
C4 was created by Google as a 'cleaned' version of AI training data created by the nonprofit Common Crawl. In addition to being used for training T5 , a natural language processing AI developed by Google, 15% is also used for the dataset used for training by Meta's LLaMA.
This time, the harmful content found to be used in the development of large-scale language models and conversational AI is considered to be the tip of the iceberg. According to The Washington Post, ``Chatbots are known to confidently provide misinformation and do not always provide citations. , and the user cannot trace the original source of the information.'
In addition, it is possible to search the analysis results of C4 on the Washington Post site .
According to it, GIGAZINE was ranked 359,741.

Related Posts:








in Software, Posted by darkhorse_log