




AIモデルのトレーニングにAI生成データを使用するとAIが物事を忘却してしまう「モデル崩壊」が起きるという指摘

インターネット上にはAIで生成されたデータがあふれていますが、これらをトレーニングデータとして利用してしまうと、AIモデルが元の物事を忘却してしまう「モデル崩壊」が起きると指摘されています。
AI models collapse when trained on recursively generated data | Nature
https://www.nature.com/articles/s41586-024-07566-y

Researchers find that AI-generated web content could make large language models less accurate - SiliconANGLE
https://siliconangle.com/2024/07/24/researchers-find-ai-generated-web-content-make-llms-less-accurate/
'Model collapse': Scientists warn against letting AI eat its own tail | TechCrunch
https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eat-its-own-tail/
2024年7月25日、オックスフォード大学のイリア・シュマイロフ氏率いる研究チームが、AIモデルは「モデル崩壊」と呼ばれる現象に対して根本的に脆弱であること示す論文を学術誌のNatureで発表しました。論文によると、他のAIモデルによって生成されたデータから無差別に学習すると、AIモデルは「モデル崩壊」を起こすそうです。「モデル崩壊」は、時間の経過と共にAIモデルが基礎となるデータ分布を忘れてしまうという退化プロセスを指します。
AIモデルの本質はパターンマッチングシステムにあります。トレーニングデータ内のパターンを学習し、入力されたプロンプトをそのパターンと照合し、最も可能性の高いものを出力するというものです。「おいしいスニッカードゥードルのレシピは何ですか?」や「就任時の年齢順にアメリカの歴代大統領を列挙してください」という質問であっても、基本的にAIモデルは一連の単語の最も可能性の高い続きを出力するだけです。
しかし、AIモデルの出力は「最も一般的なもの」に引き寄せられるという性質を持ち合わせています。AIモデルは「物議を醸すスニッカードゥードルのレシピ」ではなく「最も人気な普通のレシピ」を回答として出力しがちになるというわけです。これは画像生成AIでも同様で、例えば「犬の画像を生成してください」と入力すると、トレーニングデータにわずか数枚しか含まれていないような犬種の画像が出力されることはありません。

記事作成時点で、インターネット上にはさまざまなAI生成コンテンツがあふれかえっているため、新しいAIモデルが登場する際にはAI生成コンテンツをトレーニングデータとして活用する可能性が十分にあります。しかし、AIモデルが前述の通り「最も一般的なもの」を出力することを考慮すると、AI生成コンテンツをトレーニングデータとして活用した新しいAIモデルは、犬の90%以上がゴールデンレトリバーであると考えるようになってしまいます。このサイクルが繰り返し起きると、AIモデルは「犬が何なのか」を根本的に忘れてしまうそうで、これが「モデル崩壊」と呼ばれているわけです。
このプロセスをわかりやすく4段階に分けて図示したのが以下の画像です。
(a)あるAIモデル(AIモデル1)をトレーニングする際に、さまざまな犬種の画像を利用したとします。
(b)このAIモデル1が出力する「犬の画像」は、最も多く犬の画像としてトレーニングデータに含まれていたゴールデンレトリバーの画像が多くなります。
(c)AIモデル1が出力した「犬の画像」をトレーニングデータとした新しいAIモデル(AIモデル2)が登場。
(d)このサイクルを繰り返していくと、AIモデルは「犬の画像」がどんなものなのかを忘れてしまいます。
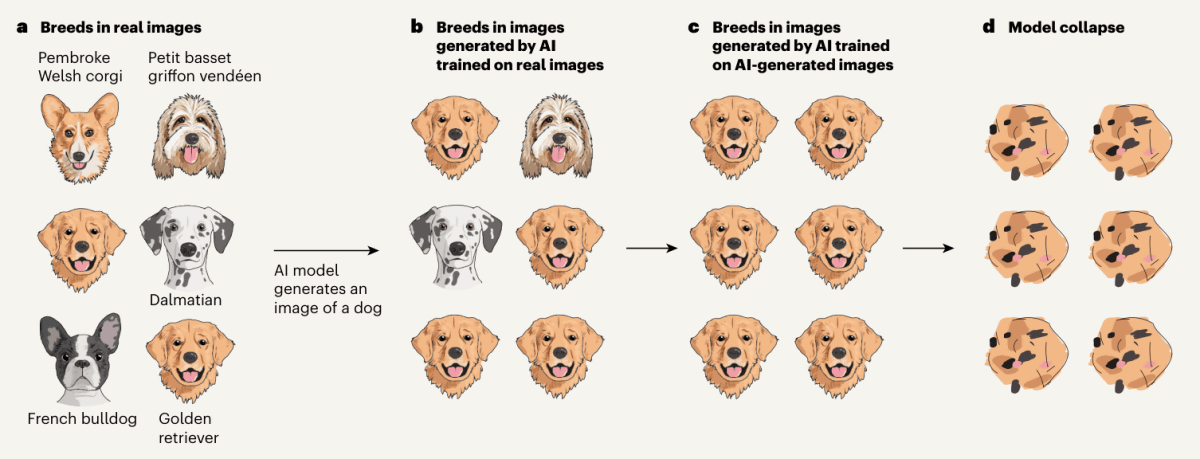
言語モデルやその他のモデルであっても、基本的にAIモデルは回答を得るためにトレーニングデータセットの中で最も一般的なデータを優先します。そのため、AI生成コンテンツがトレーニングデータとして活用する場合、モデル崩壊が問題となるわけです。
基本的にAIモデルが互いのデータでトレーニングを続けると、気付かないうちにAIモデルが愚かになっていき、最終的に崩壊してしまいます。研究チームは複数の緩和策を提示しているものの、理論上は「モデル崩壊を避けることはできない」と記しました。

研究チームは「ウェブ上から収集した大規模なデータセットからAIモデルをトレーニングすることのメリットを維持するには、モデル崩壊の危機を真摯に受け止める必要があります。インターネット上から収集されたデータに大規模言語モデル(LLM)が生成したコンテンツが含まれていることを考えると、システムと人間の真のやり取りについて収集されたデータの価値はますます高まります」「技術が大規模に採用される前にインターネット上から収集されたデータにアクセスしたり、人間が大規模に生成したデータに直接アクセスしたりせずに、新しいバージョンのLLMをトレーニングすることはますます困難になる可能性があります」と記しています。
・関連記事
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE
天文学者が銀河測定ツールを使ってAIが作成したディープフェイクを見分ける手法を発明 - GIGAZINE
作家が小説のアイデアをAIで得ると創造性は向上するが大きな問題も発生すると判明 - GIGAZINE
「AIは人間より高性能だが一部のテストでは人間の方が優秀」「高性能AIの学習コストは数百億円」などをまとめたスタンフォード大学のレポート「AI Index Report 2024」が公開される - GIGAZINE
「AIは個人的な未来を予測して警告できるのか?」ということに哲学教授が回答 - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article It is pointed out that using AI-generate….