It is pointed out that using AI-generated data to train an AI model will cause 'model collapse' in which the AI forgets things

The internet is full of AI-generated data, but it has been pointed out that using this data as training data can lead to a 'model collapse' in which the AI model forgets the original data.
AI models collapse when trained on recursively generated data | Nature

Researchers find that AI-generated web content could make large language models less accurate - SiliconANGLE
https://siliconangle.com/2024/07/24/researchers-find-ai-generated-web-content-make-llms-less-accurate/
'Model collapse': Scientists warn against letting AI eat its own tail | TechCrunch
https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eat-its-own-tail/
On July 25, 2024, a research team led by Ilya Shmailov of the University of Oxford published a paper in the academic journal Nature showing that AI models are fundamentally vulnerable to a phenomenon called 'model collapse.' According to the paper, an AI model will experience 'model collapse' if it indiscriminately learns from data generated by other AI models. 'Model collapse' refers to a degeneration process in which an AI model forgets the underlying data distribution over time.
At their core, AI models are pattern-matching systems that learn patterns in the training data, match the input prompt against those patterns, and output the most likely one. Whether the question is 'What is the recipe for a good snickerdoodle?' or 'List the US presidents in order of age at inauguration,' the AI model essentially just outputs the most likely sequence of a series of words.
However, the output of an AI model has the property of being attracted to the 'most common'. The AI model tends to output the 'most popular normal recipe' as an answer rather than the 'controversial snickerdoodle recipe'. This is also true for image generation AI. For example, if you input 'generate an image of a dog', it will not output an image of a dog breed that only a few images are included in the training data.

At the time of writing, the Internet is overflowing with various AI-generated content, so there is a good chance that new AI models will use AI-generated content as training data when they emerge. However, considering that the AI model outputs the 'most common' as mentioned above, a new AI model that uses AI-generated content as training data will think that more than 90% of dogs are golden retrievers. If this cycle is repeated, the AI model will fundamentally forget what a dog is, which is called 'model collapse.'
The image below clearly illustrates this process in four steps.
(a) Suppose you train an AI model (AI model 1) using images of various dog breeds.
(b) The “dog images” output by AI Model 1 tend to be images of golden retrievers, which were the most common dog images included in the training data.
(c) A new AI model (AI model 2) is developed using the “dog images” output by AI model 1 as training data.
(d) As this cycle continues, the AI model will forget what an 'image of a dog' looks like.
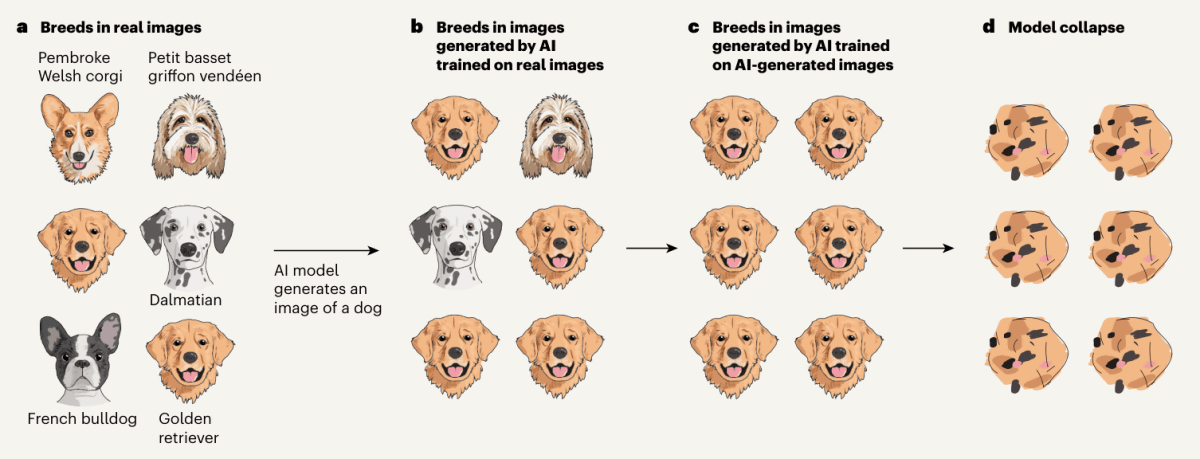
AI models, whether they be language models or any other models, will generally prioritize the most common data in their training dataset to find an answer, which is why model collapse is an issue when AI-generated content is used as training data.
Essentially, if AI models continue to train on each other's data, they will become stupider without even realizing it, and eventually collapse. Although the research team presents several mitigation measures, in theory, 'model collapse cannot be avoided,' they wrote.

The research team wrote, 'To maintain the benefits of training AI models from large-scale datasets collected from the web, we need to take the threat of model collapse seriously. Given that data collected from the internet includes content generated by large-scale language models (LLMs), the value of data collected about real interactions between systems and humans will increase. 'It may become increasingly difficult to train new versions of LLMs without access to data collected from the internet before the technology was adopted at scale, or without direct access to large-scale human-generated data.'
Related Posts:







