




ローカルAI実行ツールのOllamaがMLXに対応してMacでの動作が高速に

数多くのAIモデルをローカル環境で実行できるツール「Ollama」が、Appleの機械学習フレームワークであるMLXを基盤としてAppleシリコンに最適化したプレビュー版である「Ollama 0.19」を公開しました。このアップデートにより、macOS上での動作性能が大幅に向上し、パーソナルアシスタントやコーディングエージェントといった高度なタスクをこれまで以上に高速に実行できるようになります。
Ollama is now powered by MLX on Apple Silicon in preview · Ollama Blog
https://ollama.com/blog/mlx
今回の性能向上は、MLXが提供するユニファイドメモリ・アーキテクチャを活用することで実現されています。特にAppleのM5、M5 Pro、M5 Maxチップにおいては、新しいGPUニューラルアクセラレータを利用することで、最初のトークン生成までの時間(TTFT)と生成速度の両方が加速されました。
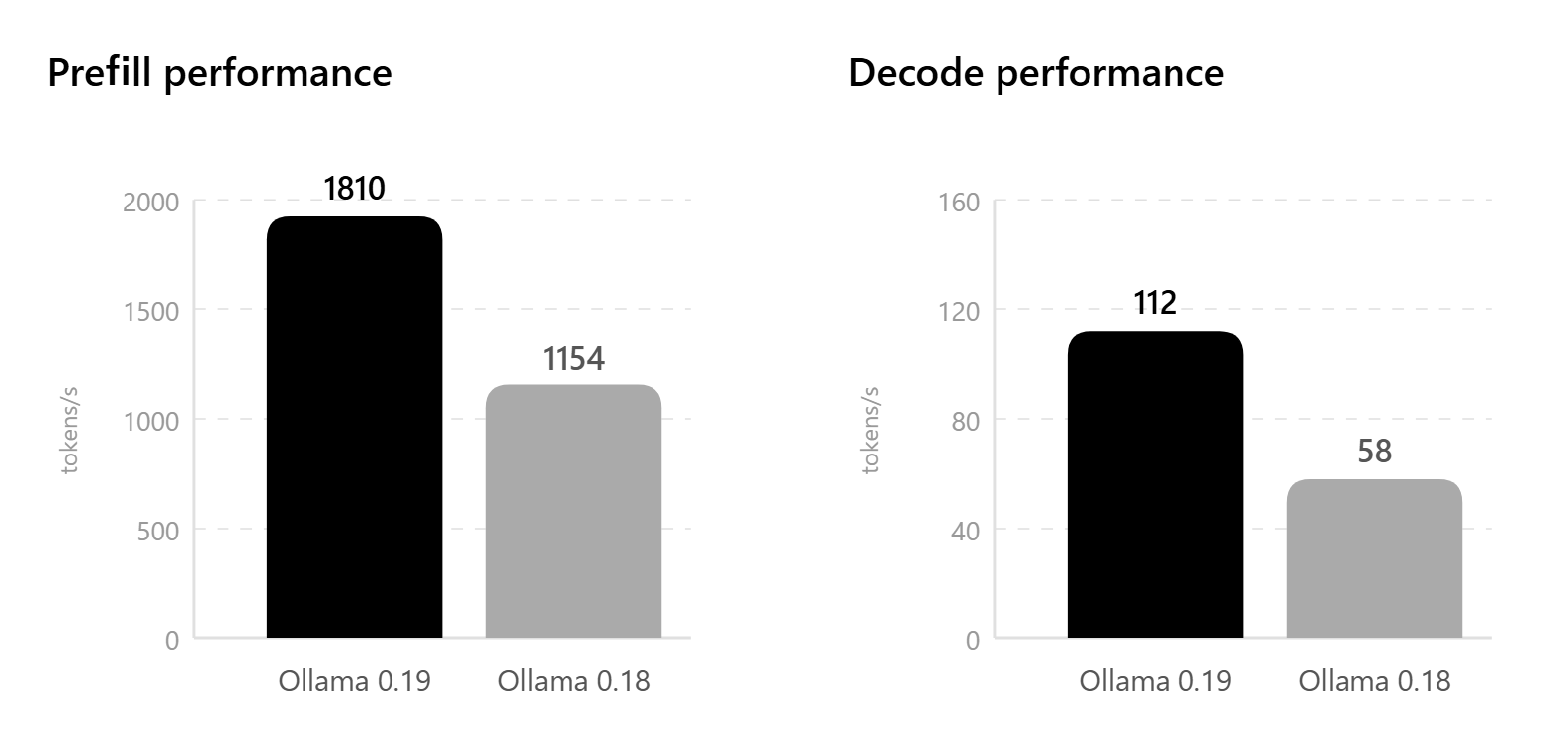
Ollama 0.19の性能測定では、旧版の0.18と比較してプリフィル性能が1154トークン/秒から1810トークン/秒へ、デコード性能が58トークン/秒から112トークン/秒へと飛躍的に向上しているとのこと。さらにint4量子化を使用した場合には、プリフィルで1851トークン/秒、デコードで134トークン/秒という極めて高いパフォーマンスを発揮します。
機能面では、NVIDIAのNVFP4フォーマットをサポートしたことにより、モデルの精度を維持しながら推論時のメモリ帯域幅とストレージ要件を削減しています。これにより、商用の推論プロバイダーと同等の結果をローカル環境で得ることが可能になり、NVIDIAのモデルオプティマイザーで最適化されたモデルの実行もサポートされました。
また、キャッシュシステムも大幅にアップグレードされました。会話間でキャッシュを再利用してメモリ使用率を抑える機能や、プロンプトの適切な位置にスナップショットを保存して処理を短縮するインテリジェント・チェックポイント、さらに共有プレフィックスを長く保持するスマートな破棄アルゴリズムにより、コーディングやエージェント作業の効率が向上しているとのこと。
Claude CodeやPiのようなインターフェースでは、モデルの切り替えや思考レベルの調整、bashの実行や画像の貼り付けといった多様な操作をキーボードショートカットで迅速に行うことが可能です。
なお、このプレビュー版は記事作成時点だとコーディングタスク向けに調整されたAlibabaのQwen3.5-35B-A3Bモデルが高速化の対象となっており、32GB以上のユニファイドメモリを搭載したMacが必要です。Qwen3.5-35B-A3BはClaude CodeやOpenClawといったツールを介して利用できるほか、コマンドラインから直接実行することもできます。
将来的にはサポートされるアーキテクチャを順次拡大し、ユーザーが独自にファインチューニングしたモデルを容易にインポートできる仕組みもOllamaに導入される予定です。
・関連記事
さまざまなチャットAIを簡単にローカル環境で動かせるアプリ「Ollama」の公式Dockerイメージが登場 - GIGAZINE
Llama 2などの大規模言語モデルをローカルで動かせるライブラリ「Ollama」がAMD製グラボに対応 - GIGAZINE
ローカルAIアプリのOllamaが画像生成に対応、まずは「FLUX.2 [klein]」と「Z-Image-Turbo」から - GIGAZINE
OpenAIのオープンウェイトモデル「gpt-oss」はOllamaを使って個人用PCで簡単に使用可能 - GIGAZINE
定番ローカルAIツール「Ollama」のGUIアプリ版が登場、数多くの大規模言語モデルをローカルで実行してチャットできる - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Ollama, a local AI execution tool, now s….