Ollama, a local AI execution tool, now supports MLX, resulting in faster performance on Macs.

Ollama, a tool that allows users to run numerous AI models locally, has released Ollama 0.19, a preview version optimized for Apple Silicon and based on Apple's machine learning framework,
Ollama is now powered by MLX on Apple Silicon in preview · Ollama Blog
https://ollama.com/blog/mlx
This performance improvement is achieved by leveraging the unified memory architecture provided by MLX. In particular, Apple's M5, M5 Pro, and M5 Max chips utilize a new GPU neural accelerator to accelerate both the time to first token generation (TTFT) and the generation speed.
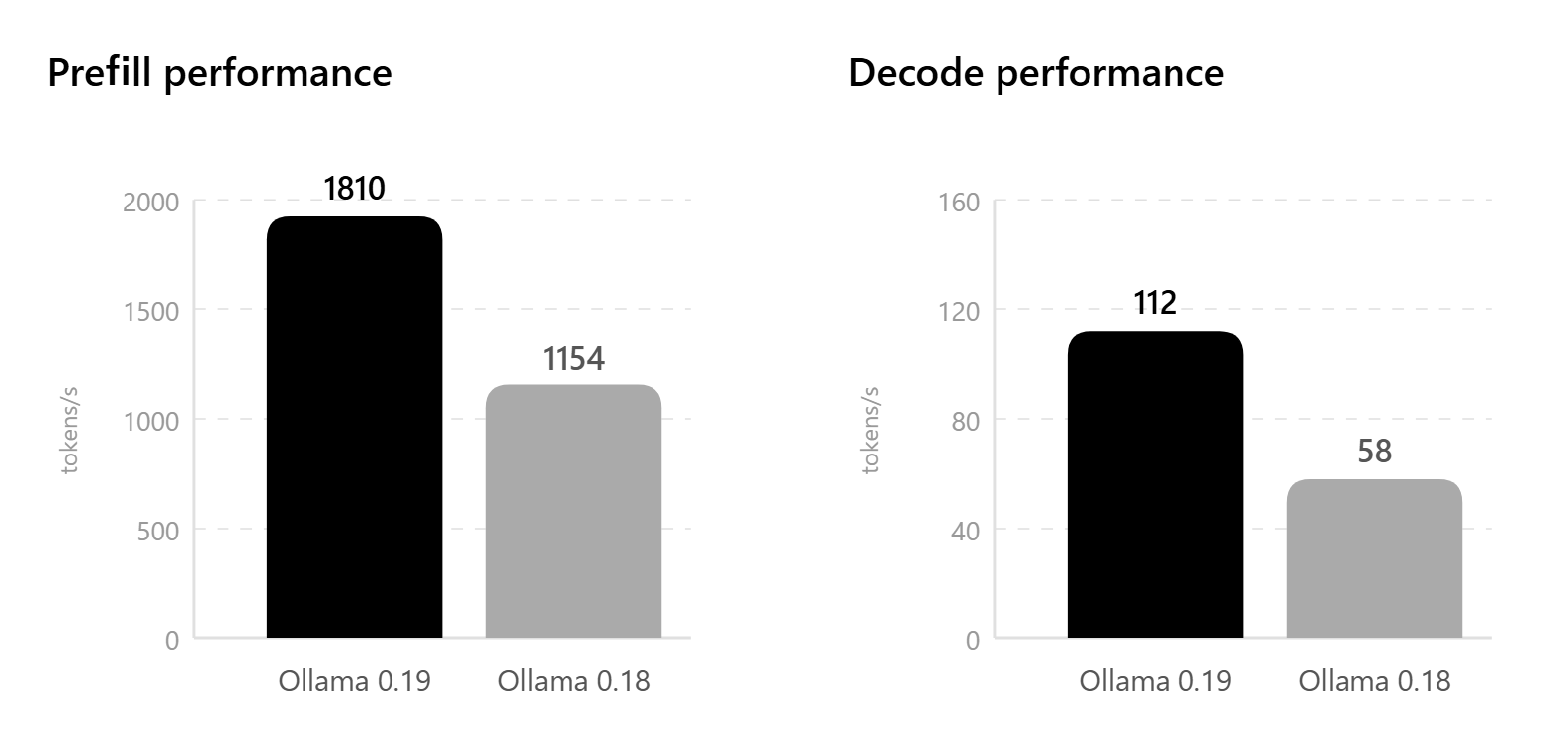
Performance tests of Ollama 0.19 show a dramatic improvement compared to the previous version 0.18, with prefill performance increasing from 1154 tokens/second to 1810 tokens/second and decoding performance increasing from 58 tokens/second to 112 tokens/second. Furthermore, when using int4 quantization, it achieves extremely high performance of 1851 tokens/second for prefill and 134 tokens/second for decoding.
In terms of functionality, support for NVIDIA's
The caching system has also been significantly upgraded. Features such as reusing the cache between conversations to reduce memory usage, intelligent checkpoints that save snapshots at the right location in the prompt to shorten processing time, and a smart discard algorithm that retains shared prefixes for longer periods have been implemented, resulting in improved efficiency for coding and agent work.
Interfaces like Claude Code and Pi allow you to quickly perform a variety of operations using keyboard shortcuts, such as switching models, adjusting thinking levels, executing bash scripts, and pasting images.
Note that, as of the time of writing, this preview version targets Alibaba's Qwen3.5-35B-A3B model, which is optimized for coding tasks, and requires a Mac with 32GB or more of unified memory. Qwen3.5-35B-A3B can be used through tools such as Claude Code and OpenClaw, or it can be run directly from the command line.
In the future, we plan to gradually expand the supported architectures and introduce a mechanism to Ollama that will allow users to easily import their own finely tuned models.
Related Posts:







