Microsoft's AI chip 'Maia 200' is now operational, manufactured using a 3nm process and supports inference such as GPT-5.2

Microsoft has announced Maia 200 , an inference accelerator designed to dramatically improve the economics of AI token generation, delivering significantly improved performance per fee.
Maia 200: The AI accelerator built for inference - The Official Microsoft Blog
Microsoft introduces newest in-house AI chip — Maia 200 is faster than other bespoke Nvidia competitors, built on TSMC 3nm with 216GB of HBM3e | Tom's Hardware
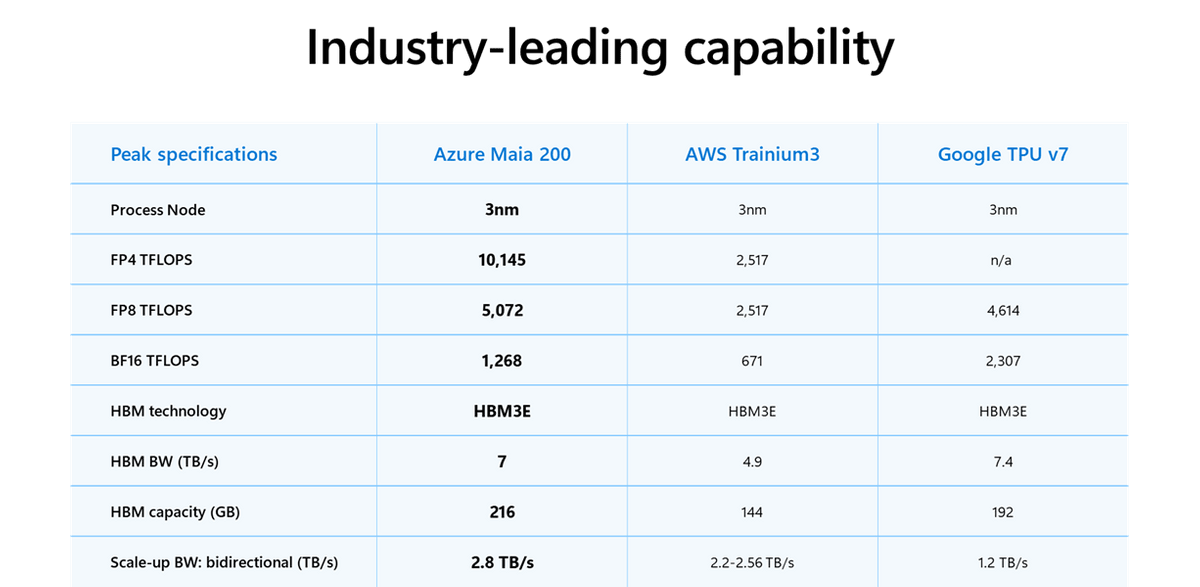
The Maia 200 is a chip manufactured using TSMC's 3nm process and boasts a 30% improvement in performance per dollar compared to its predecessor.
In addition, the processor features 216GB of HBM3E (7TB/s) and 272MB of on-chip SRAM , integrating a data movement engine for fast and efficient data delivery to large models. With over 140 billion transistors, it's optimized for large-scale AI workloads, delivering cost-effective performance. Within a 750W SoC TDP, it delivers over 10 petaFLOPS in FP4 (4-bit floating point) and over 5 petaFLOPS in FP8 (8-bit floating point). In practical terms, it can easily run the largest existing models, with ample headroom for even larger models in the future.
Compared to other companies' products, it is said to have three times the FP4 performance of the third-generation Amazon Trainium and more FP8 performance than Google's seventh-generation TPU.
In addition, the accompanying memory subsystem eliminates bottlenecks in AI acceleration, and by keeping high-bandwidth communications local, optimal inference efficiency is achieved. Designed from the outset for rapid and seamless deployment in data centers, Microsoft says data center deployment time is reduced by more than half compared to comparable systems. 'A core principle of our silicon development program is to validate the entire end-to-end system to the greatest extent possible before delivering final silicon,' Microsoft said.
Maia 200 supports multiple models, including OpenAI's GPT-5.2 model, and is said to bring cost-effective advantages to Microsoft Foundry and Microsoft 365 Copilot. It has already been deployed in the central data center region near Des Moines, Iowa, and will next be deployed in the western data center region near Phoenix, Arizona, with subsequent rollouts planned.

Also available in preview is the Maia SDK, which seamlessly integrates with Azure and provides a complete set of model building and optimization tools for Maia 200. It provides a comprehensive set of features, including PyTorch integration, the Triton compiler, an optimized kernel library, and access to Maia's low-level programming language, enabling developers to easily port models across heterogeneous hardware accelerators.
Microsoft also stated, 'The era of large-scale AI is just beginning, and infrastructure will determine its potential. Our Maia AI accelerator program is multi-generational in design, and we are already designing the next generation as we deploy Maia 200 across our global infrastructure.'
Related Posts: