




大規模言語モデルを動作させる時に必要なVRAMの使用量を推定してくれる「VRAM Estimator」
大規模言語モデルを動作させるには、演算処理にGPUを使用するため、グラフィックスメモリ(VRAM)の容量が重要になります。「VRAM Estimator」はさまざまなモデルで必要となるVRAMの容量をシミュレーションで予測するウェブアプリです。
VRAM Calculator
https://vram.asmirnov.xyz/
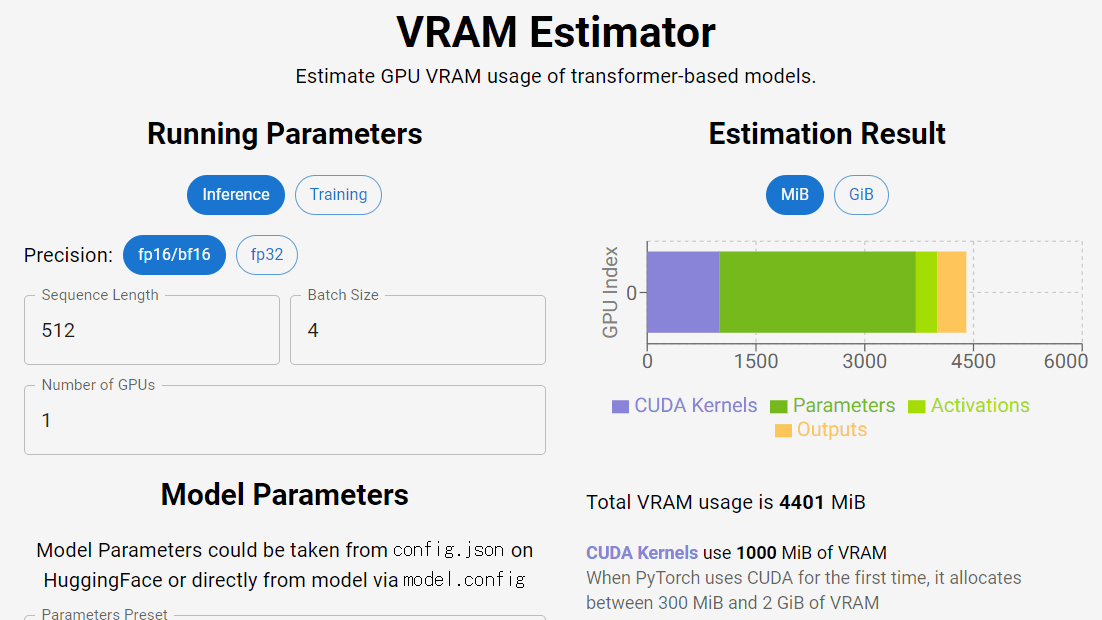
VRAM Estimatorにアクセスするとこんな感じ。
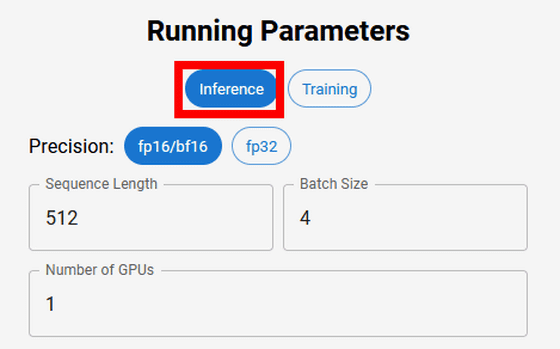
左上の「Running Parameters」で演算内容を指定します。Inference(推論)の場合、Precision(精度)でbf16/fp16か、fp32を選択し、Sequence Length(シークエンス長)・Batch Size(バッチサイズ)・Number of GPUs(GPU数)を指定できます。
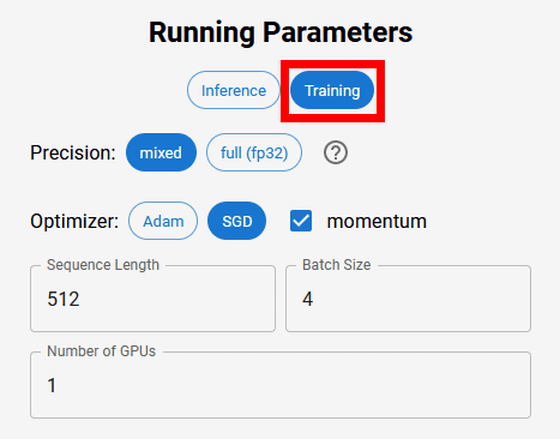
Training(学習)の場合、Precisionで「mixed(混合精度)」か「full(fp32)」を、Optimizer(勾配法)で「Adam」か「SGD」を選択し、Sequence Length・Batch Size・Number of GPUsを指定できます。
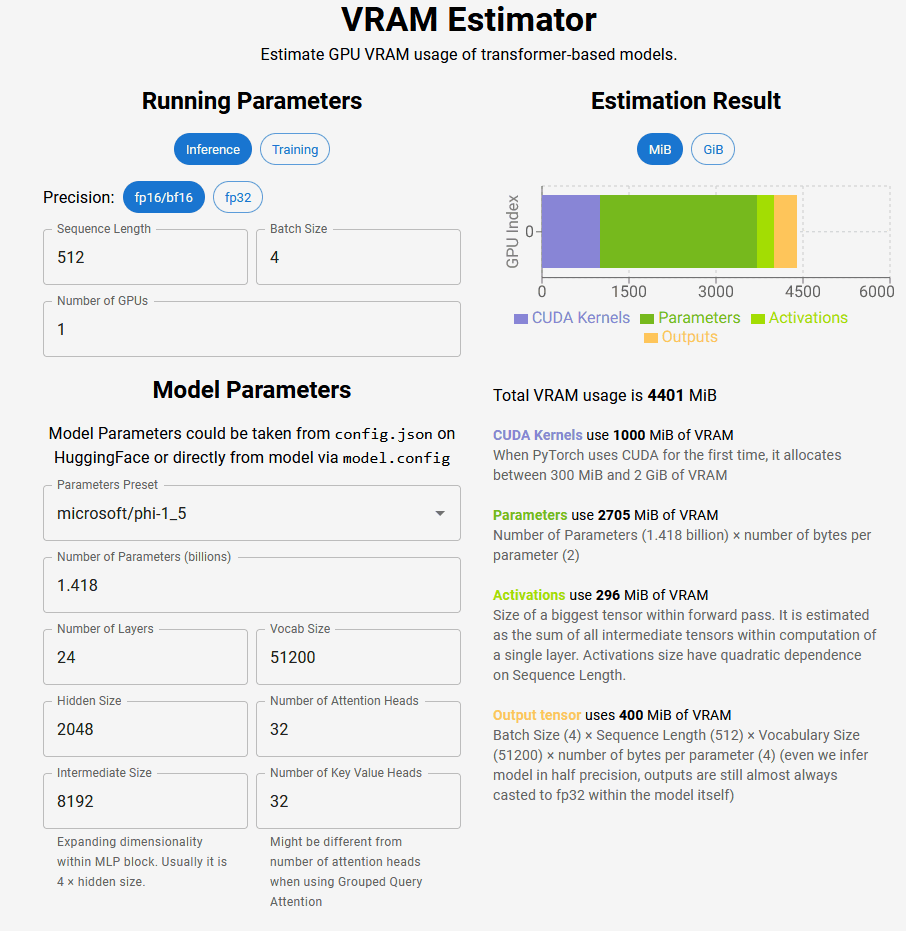
「Model Parameters」では、model.configやAIプラットフォームのHugging Faceで示されている数値を入力します。Palameters Presetでモデル名を選択し、Number of Parameters(パラメーター数、10億単位)、Number of Layers(レイヤー数)、Vocab Size(語彙サイズ)、Hidden Size(隠れサイズ)、Number of Attention Heads(Attention-Headsの数)、Intermediate Size(中間層のサイズ)、Number of Key Value Heads(キー値の重み)を指定すればOK。
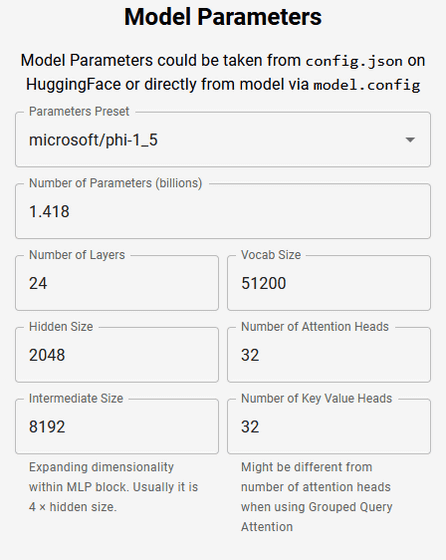
すると、右にVRAMの合計使用量の推定が表示されます。以下の場合だと、合計使用料は4401MiB(メビバイト)で、内訳としてCUDAカーネルに1000MiB、パラメーターに2705Mi、フォワードパス内の最大テンソルに296MiB、出力テンソルに400MiB使用すると推測されています。
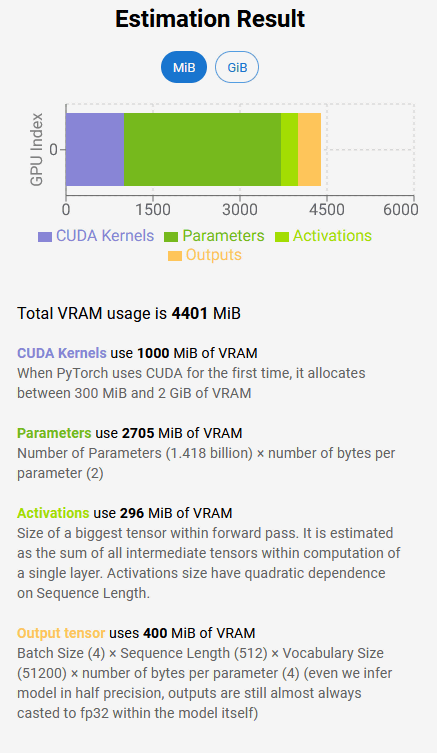
各要素の意味については、開発者のアレクサンダー・スミルノフ氏が以下のブログで解説しています。
Breaking down GPU VRAM consumption
https://asmirnov.xyz/vram
また、VRAM Estimatorのソースコードは以下のGitHubリポジトリで公開されています。
vram-calculator/app/_lib/index.ts at main · furiousteabag/vram-calculator · GitHub
https://github.com/furiousteabag/vram-calculator/blob/main/app/_lib/index.ts
・関連記事
数学・物理学の知識を理解するための「足りない知識」を「ツリー構造」で掘り下げていける学習サイト「コグニカル」レビュー - GIGAZINE
ChatGPTのような高性能言語モデルを生み出した技術はどんな仕組みなのか?をAI企業のエンジニアが多数の図解でゼロから解説 - GIGAZINE
大規模言語モデルの構造を3Dで視覚化してどんな計算が行われているのかを見やすく表示してくれるサイト「LLM Visualization」 - GIGAZINE
ChatGPTなどの対話型AIの基礎となっている「Attention」を可視化した「Attention Viz」 - GIGAZINE
1万種類を超える大規模言語モデル(LLM)をまとめてダウンロード数や類似性などを分かりやすく視覚化したデータライブラリが公開される - GIGAZINE
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
・関連コンテンツ






in ソフトウェア, レビュー, Posted by log1i_yk
You can read the machine translated English article 'VRAM Estimator' that estimates the amou….