




ChatGPTなどの対話型AIの基礎となっている「Attention」を可視化した「Attention Viz」
ChatGPTやBing Chatの背景にある大規模言語モデルの多くは、Googleが開発したニューラルネットワークアーキテクチャーの「Transformer」を採用しています。このTransformerの鍵になるのが「Self-Attention」というシステムです。このSelf-Attentionを視覚化するためのツール「Attention Viz」を、ハーバード大学とGoogleの共同研究チームが発表しました。
AttentionViz Docs
https://catherinesyeh.github.io/attn-docs/
Transformerがどういう仕組みのアーキテクチャなのかについては、以下の記事を読むとよくわかります。
ChatGPTにも使われる機械学習モデル「Transformer」が自然な文章を生成する仕組みとは? - GIGAZINE

自然言語処理をディープラーニングで行う場合、これまでは回帰型ニューラルネットワーク(RNN)が使われていました。しかし、2017年6月にGoogleが「Attention is All You Need」という論文でAttentionという概念を取り入れたシステムを発表し、自然言語処理モデルのスコアを大きく引き上げました。AttentionシステムはRNNよりも性能が高いだけでなく、GPU演算効率が良いことから学習が速く、さらにRNNよりも扱いが簡単であることから、大規模言語モデルにとってAttentionは不可欠な機構となりました。
Transformerは入力を処理するエンコーダー部分と出力結果を処理するデコーダー部分にわけられ、その両方でSelf-Attentionというシステムが採用されています。このSelf-Attentionとは、ある文中のトークンが他の単語とどれだけ関連しているのかを計算するというもの。トークン間の関連性を計算するために、エンコーダーのSelf-Attentionでは、各入力要素からクエリとキーという2つの値が算出されます。
例えば、「the sky is blue(その空は青い)」という文章は、「the」「sky」「is」「blue」という4つのトークンに分解できます。
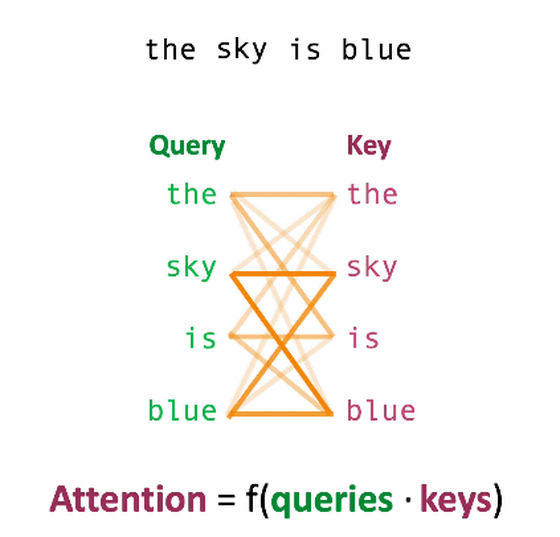
それぞれのクエリとキーの行列を算出し、座標上に示すと以下の通り。
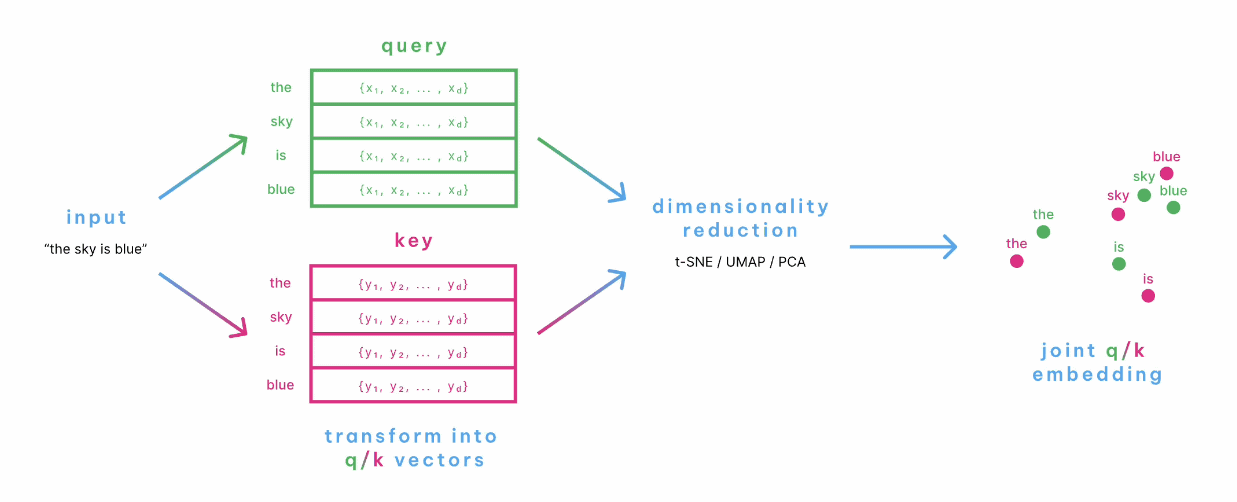
この座標上で、それぞれのトークンの距離が近ければ関連性が高く、遠ければ関連性が低いということになります。
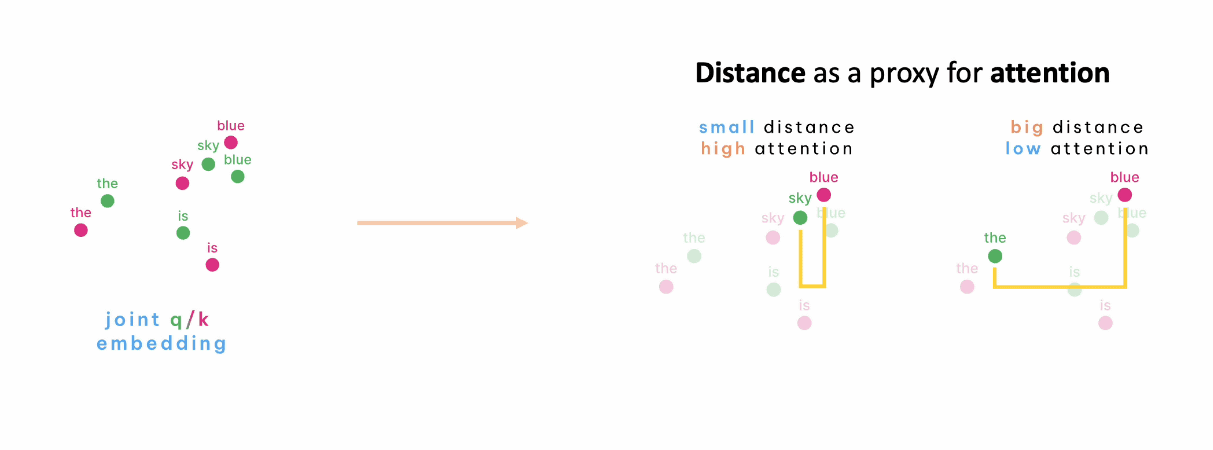
このように、各トークンのクエリとキーを座標に示して可視化したものがAttention Vizです。Attention Vizのデモは以下で公開されています。
Attention Viz
http://attentionviz.com/
デモサイトにアクセスするとこんな感じ。論文やGitHubなどへのリンクが表示されるので、×アイコンをクリックして閉じます。
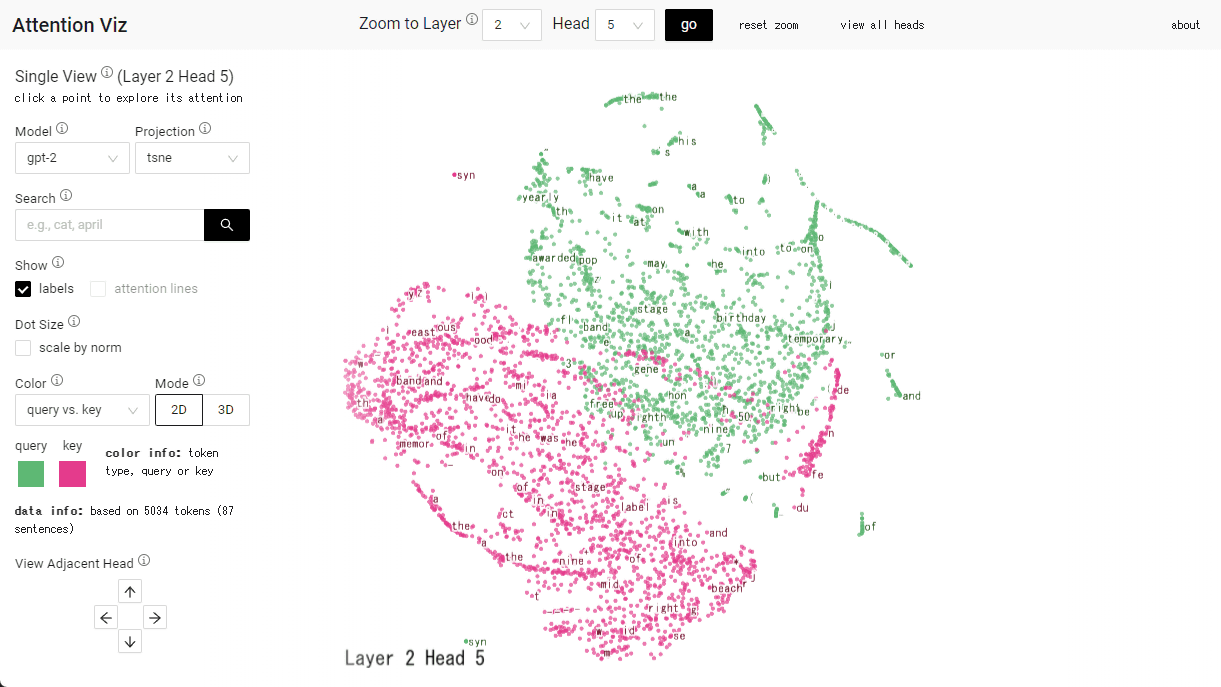
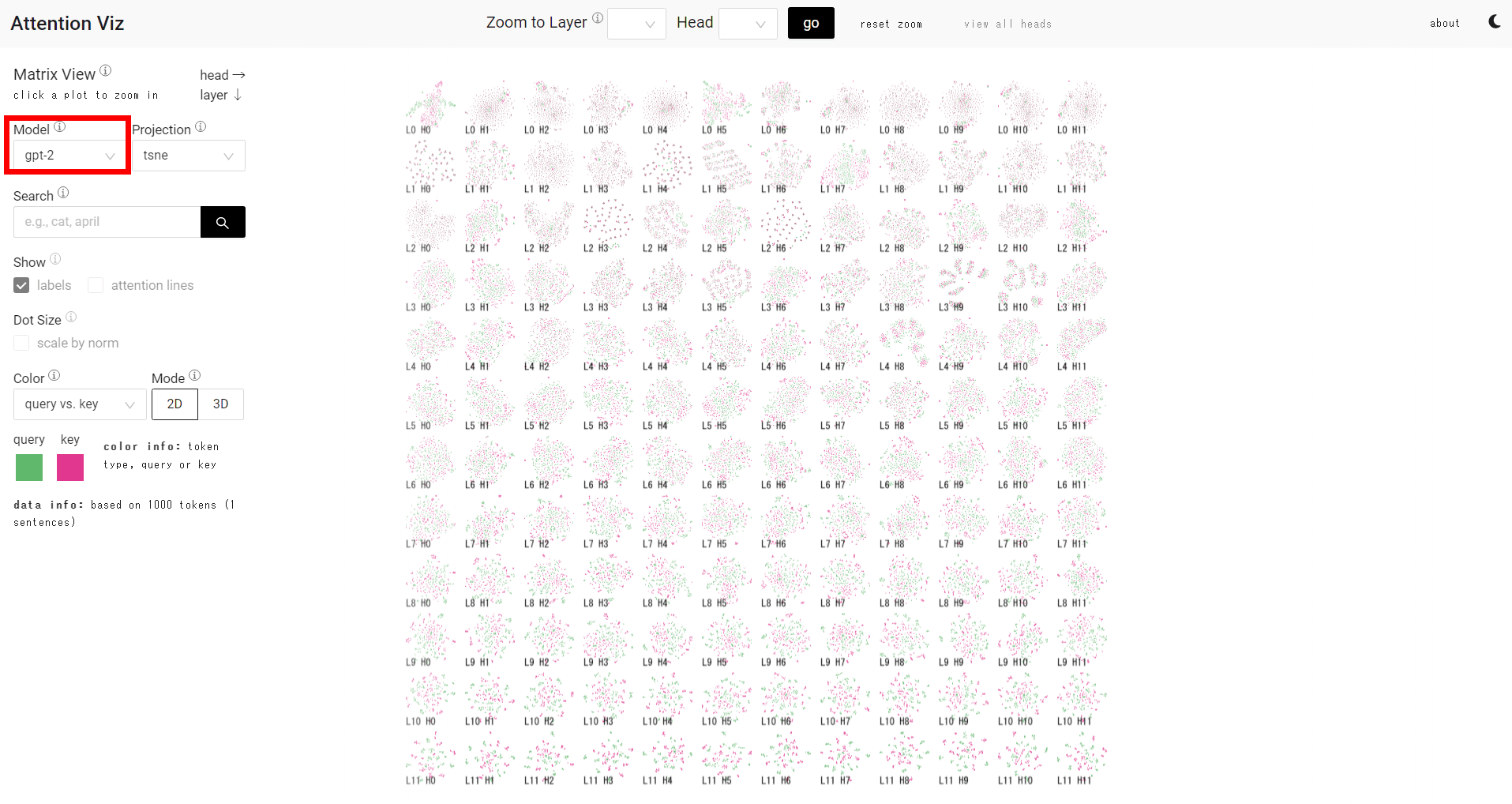
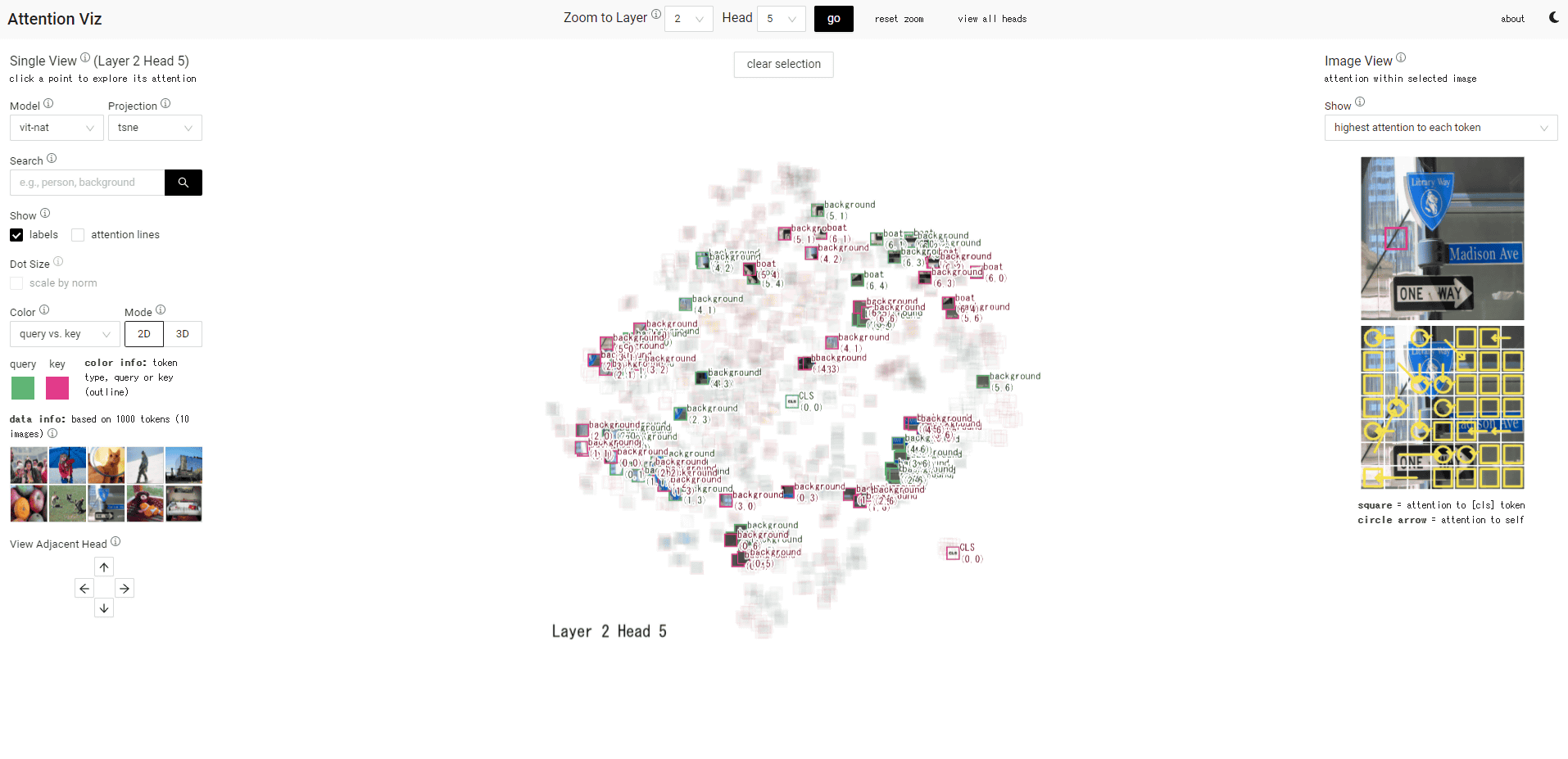
左カラムの「Model」で、大規模言語モデルを選択できます。記事作成時点では画像認識モデルのVision Transformer(vit)2種、Google Bert、GPT-2です。今回はGPT-2を選択。右側に、トークンのクエリとキーを可視化したものをレイヤー(L)とヘッド(H)ごとに表示したマトリックスが表示されます。
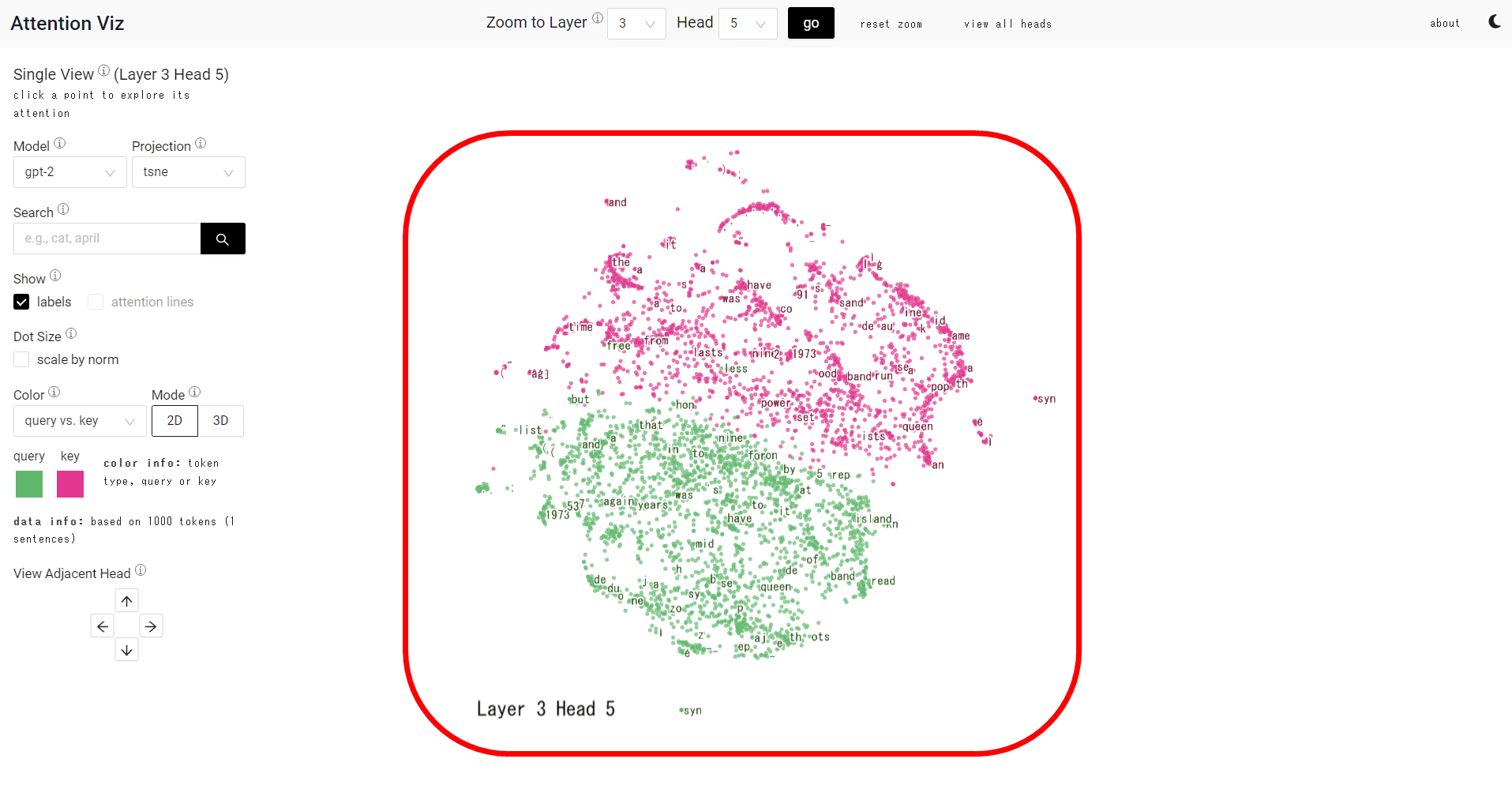
画面上部にレイヤーとヘッドの数値を指定して「go」をクリックすると、特定のマップを表示します。

今回は「L3H5」を表示しました。緑のドットがクエリ、赤いドットがキーのベクトルを示しています。
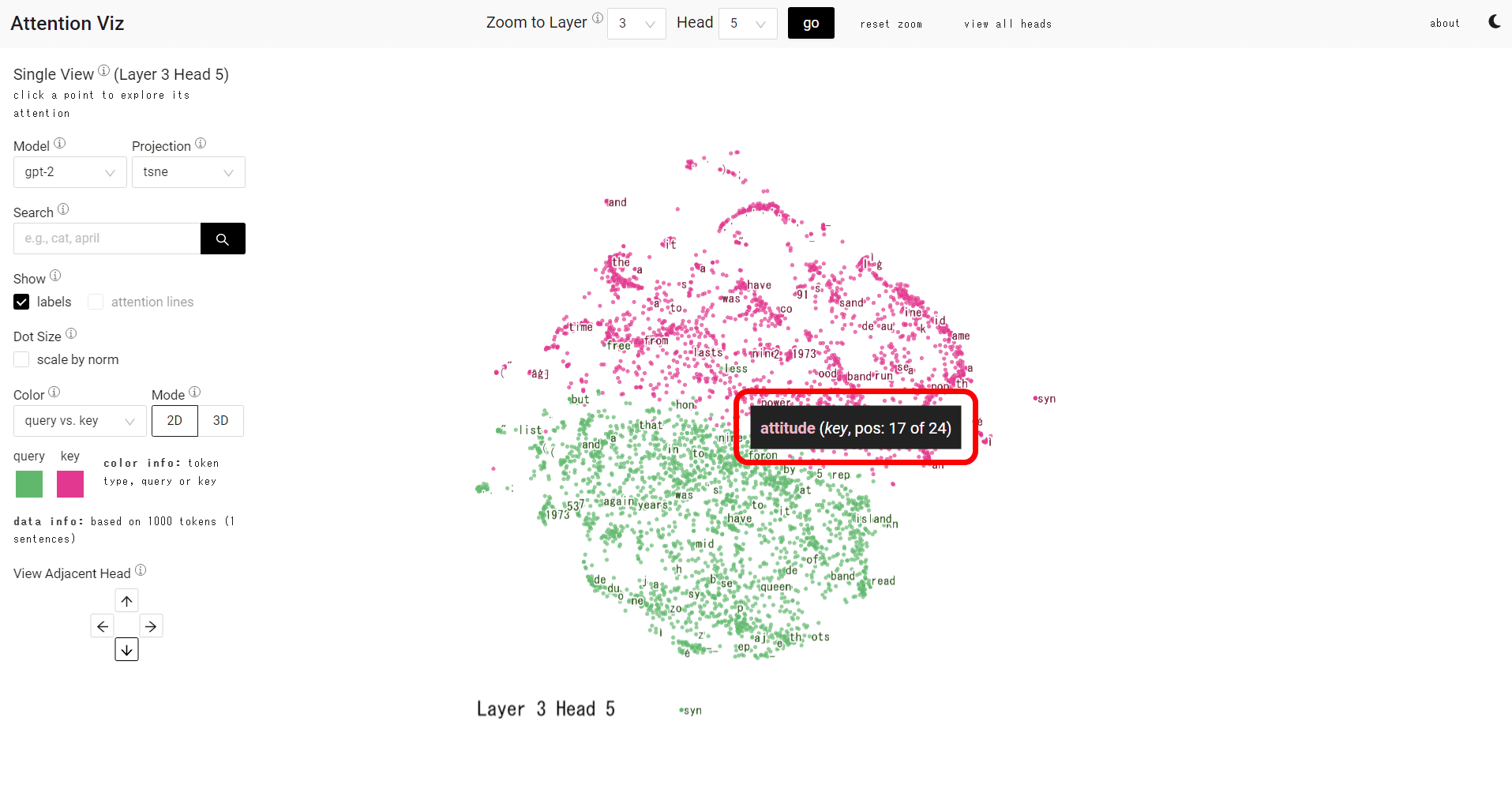
ドットにカーソルを重ね合わせると、トークンが表示されます。
モデルをVisionTransformerに変更すると、トークンのドットの代わりに画像が表示されました。
・関連記事
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
ChatGPTは何をしていてなぜ機能するのか?を理論物理学者が解説 - GIGAZINE
ChatGPTなどのチャットAIがどんな風に文章をトークンとして認識しているのかが一目で分かる「Tokenizer」 - GIGAZINE
OpenAI開発のテキスト生成AI「GPT-3」がどんな処理を行っているのかを専門家が解説 - GIGAZINE
・関連コンテンツ






in ソフトウェア, レビュー, ウェブアプリ, Posted by log1i_yk
You can read the machine translated English article ``Attention Viz'' that visualize….