``Attention Viz'' that visualizes ``Attention'', which is the basis of interactive AI such as ChatGPT
Many of the large-scale language models behind ChatGPT and Bing Chat use
Attention Viz Docs
https://catherinesyeh.github.io/attn-docs/
You can understand the architecture of how Transformer works by reading the following article.
What is the mechanism by which the machine learning model 'Transformer', which is also used for ChatGPT, generates natural sentences? -GIGAZINE

Until now, recurrent neural networks (RNNs) have been used in deep learning for natural language processing. However, in June 2017, Google announced a system that incorporates the concept of attention in a paper called ` ` Attention is All You Need '', greatly raising the score of the natural language processing model. The attention system not only has higher performance than RNN, but also has faster learning due to better GPU computation efficiency, and is easier to handle than RNN, so attention has become an indispensable mechanism for large-scale language models.
The Transformer is divided into an encoder part that processes the input and a decoder part that processes the output result, both of which adopt a system called Self-Attention. This Self-Attention is to calculate how much a token in a sentence is related to other words. To compute the relevance between tokens, the encoder's self-attention computes two values from each input element: the query and the key.
For example, the sentence ``the sky is blue'' can be decomposed into four tokens: ``the'', ``sky'', ``is'' and ``blue''.
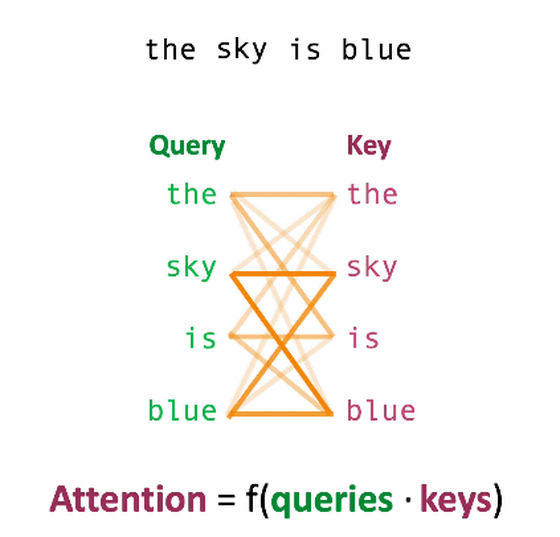
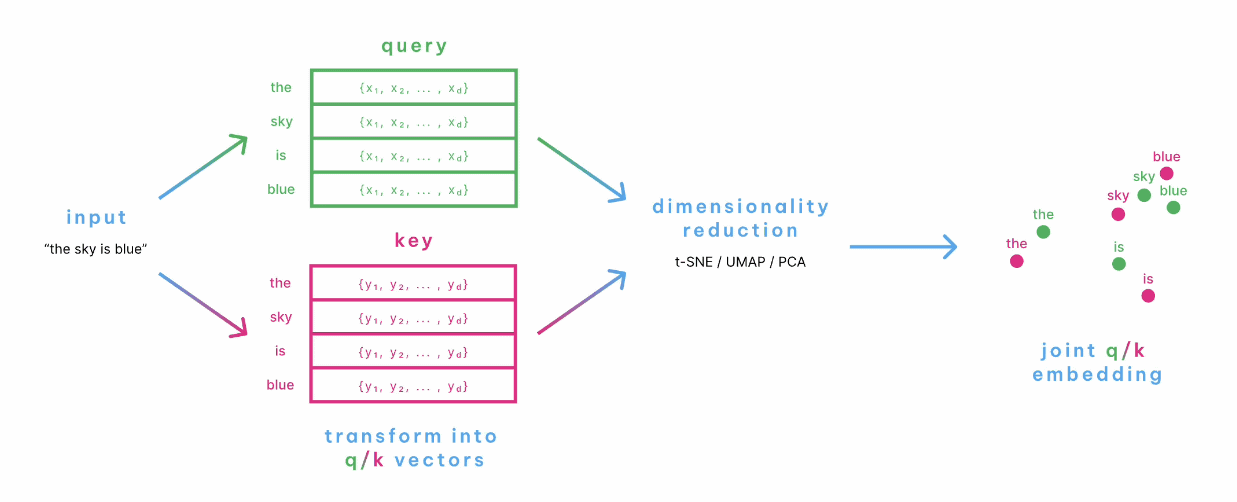
Calculate the matrix of each query and key and show it on the coordinates as follows.
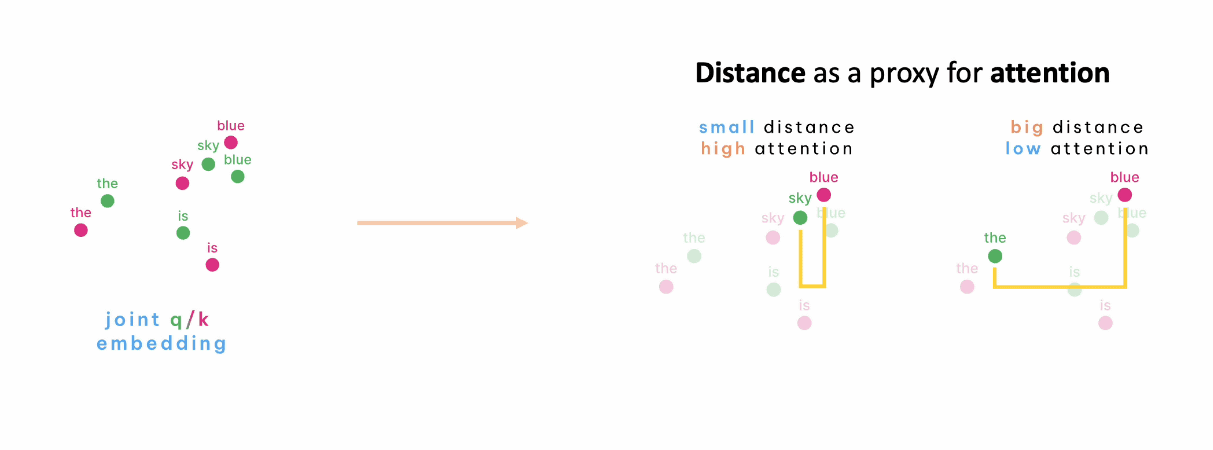
On this coordinate, if the distance of each token is close, the relevance is high, and if it is far, the relevance is low.
In this way, Attention Viz is a visualization of the query and key of each token as coordinates. A demo of Attention Viz is available below.
Attention Viz
http://attentionviz.com/
When you access the demo site, it looks like this. Links to papers, GitHub, etc. will be displayed, so click the × icon to close it.
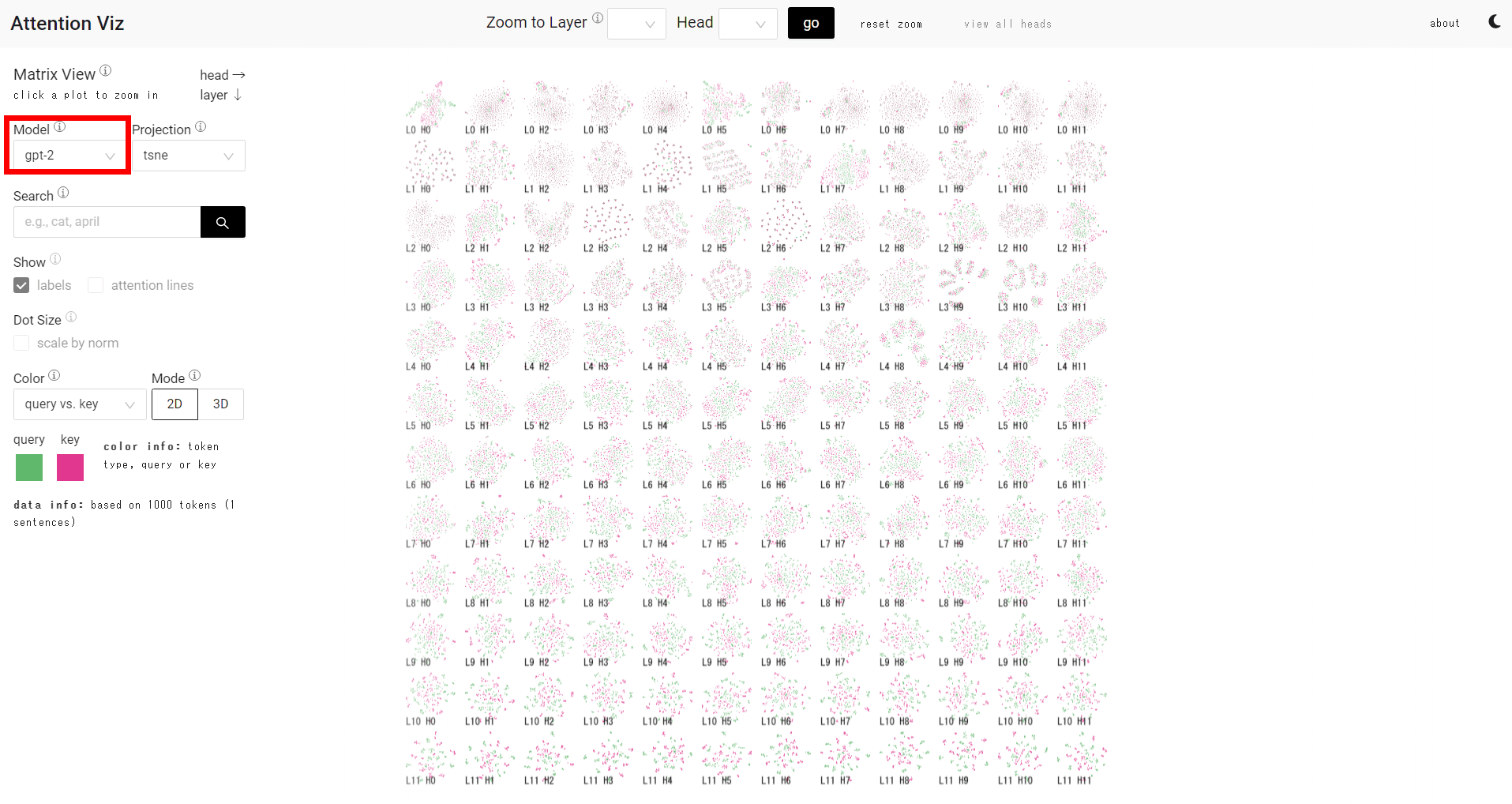
In the left column, 'Model', you can select a large language model. At the time of article creation, there are two types of image recognition models,
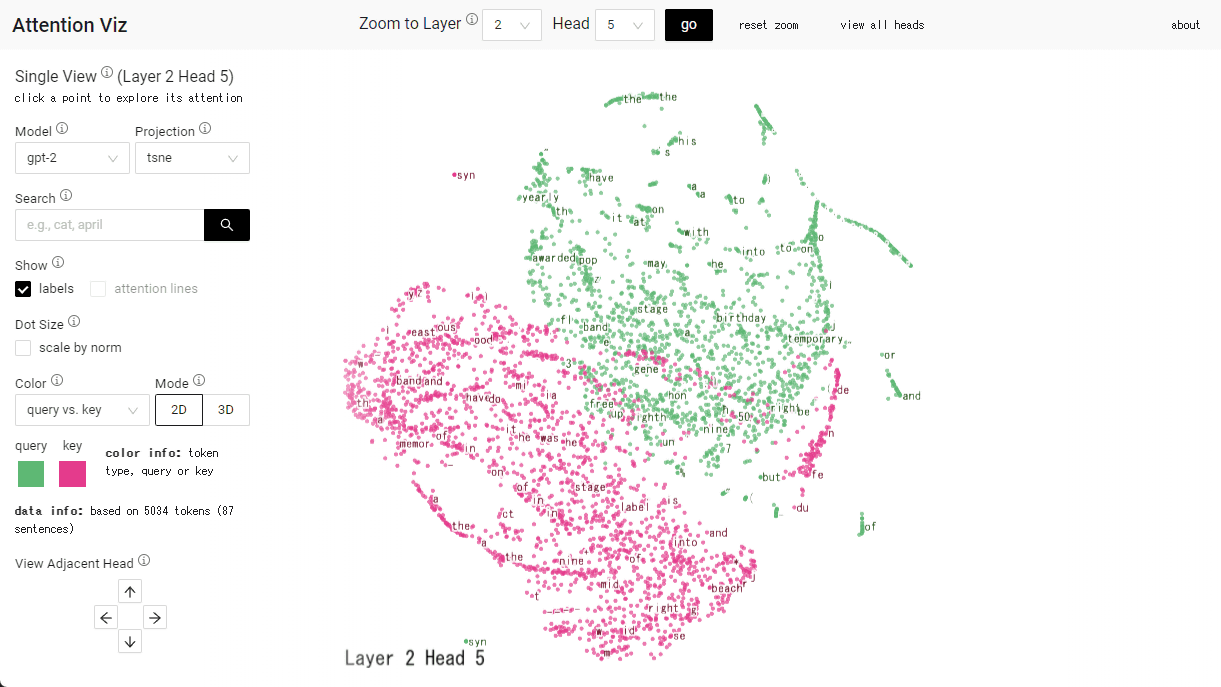
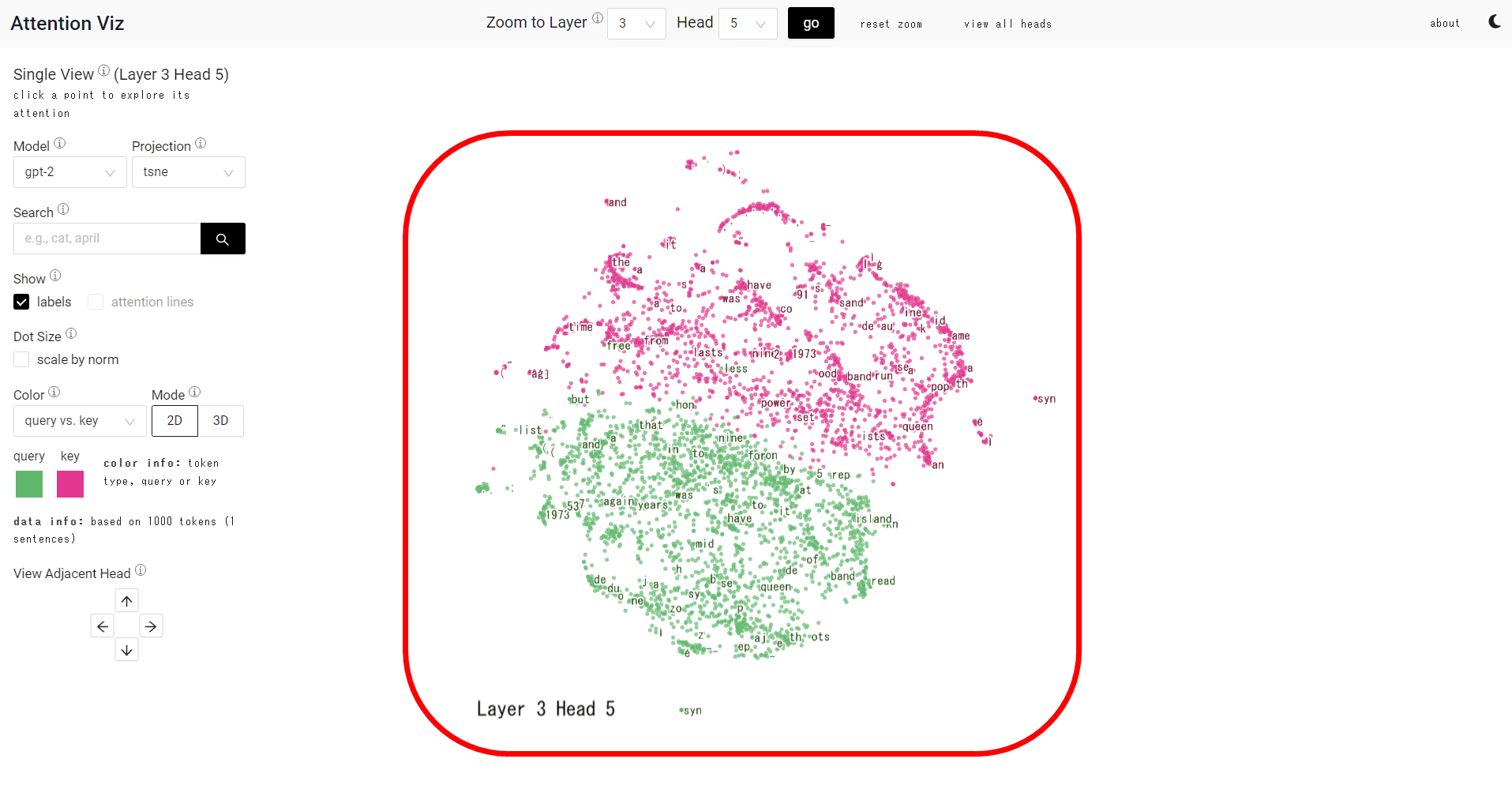
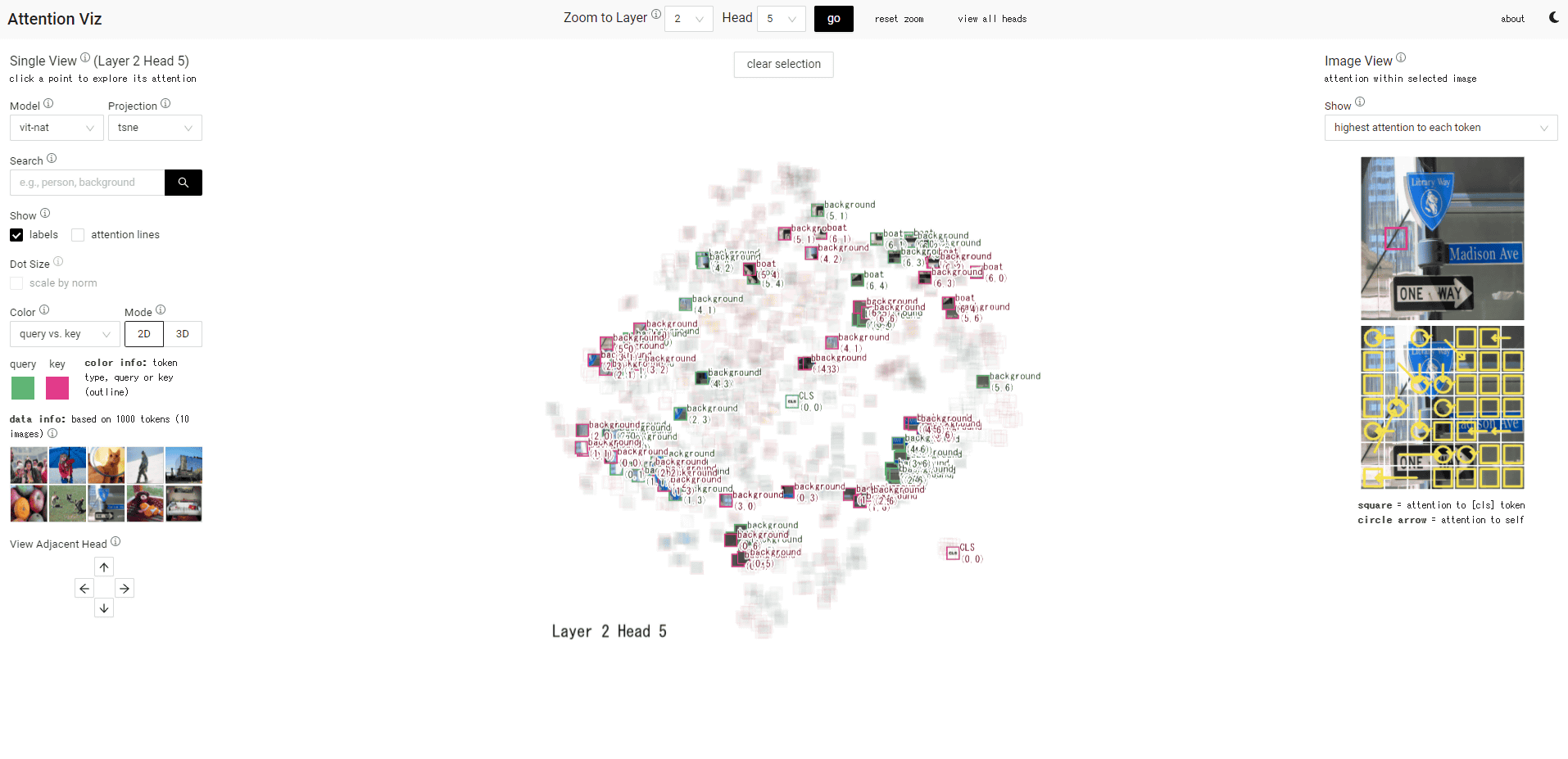
Specify the layer and head numbers at the top of the screen and click 'go' to display a specific map.

This time, 'L3H5' was displayed. The green dot is the query and the red dot is the key vector.
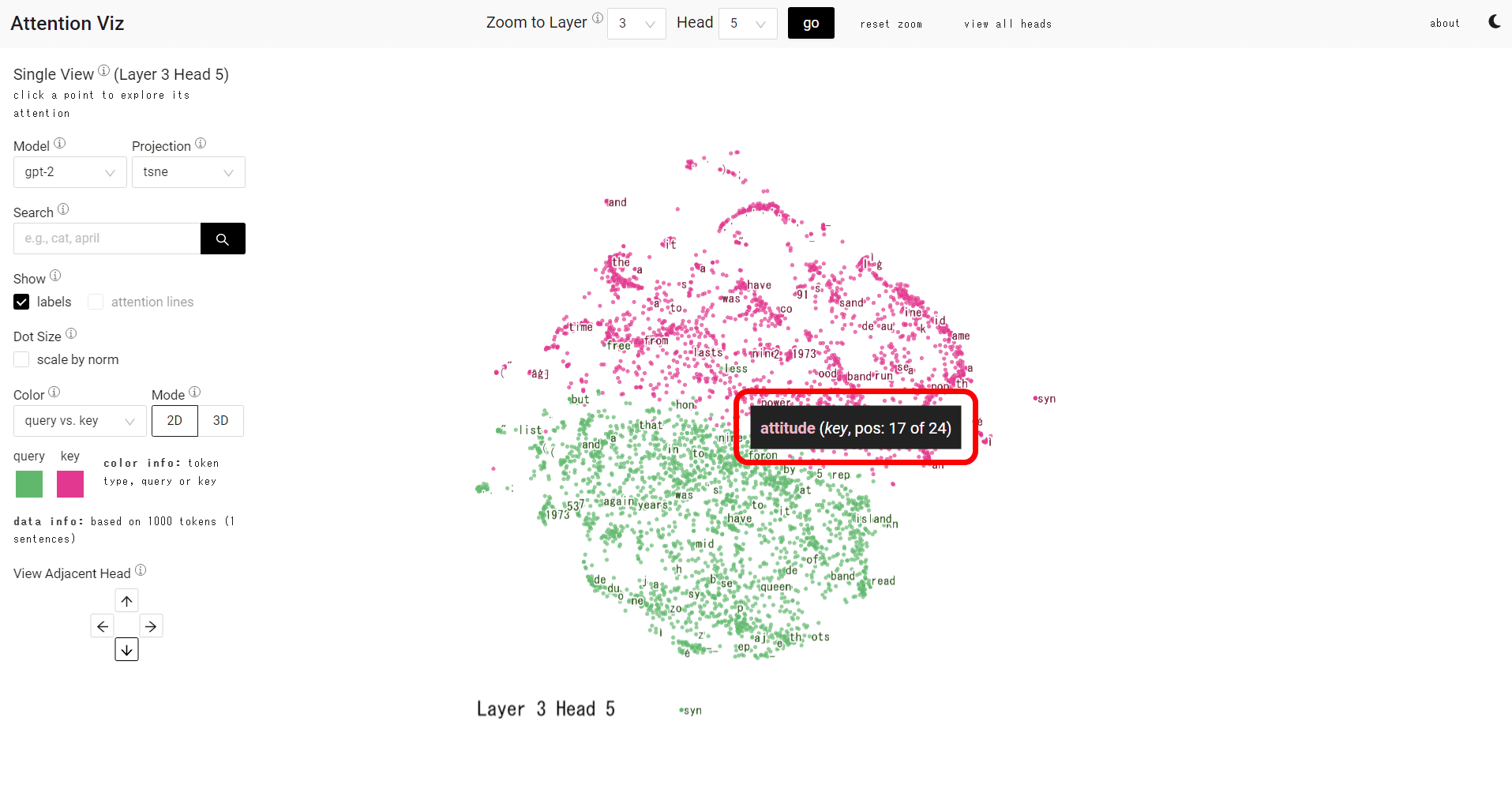
Hover over the dot to see the token.
When I changed the model to VisionTransformer, I got images instead of token dots.
Related Posts:




in Review, Software, Web Application, Posted by log1i_yk