A research team such as the Toyota Research Institute develops an AI model 'Zero-1-to-3' that generates an image from a different viewpoint from just one image
The AI model ' Zero-1-to-3 ', which can generate high-precision images from different viewpoints simply by inputting a single image of an object, has been developed by Columbia University in the United States and Toyota Research, a research institute of
[2303.11328] Zero-1-to-3: Zero-shot One Image to 3D Object
https://doi.org/10.48550/arXiv.2303.11328
Zero-1-to-3: Zero-shot One Image to 3D Object
https://zero123.cs.columbia.edu/
Zero-1-to-3 is an AI model that learns relative camera viewpoint control using a large-scale diffusion model , and can output images with different camera viewpoints from a single RGB image. .
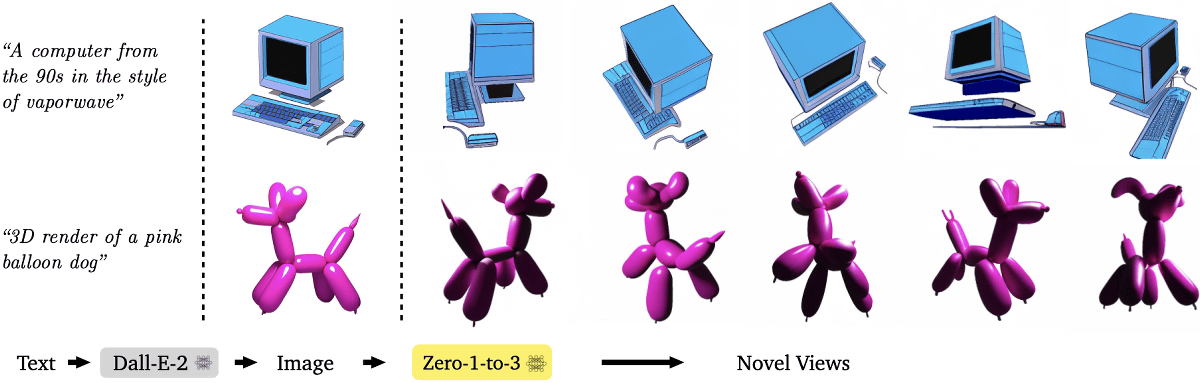
The following images show the results of inputting images generated by DALL E 2 of image generation AI into Zero-1-to-3 and outputting images from various viewpoints. It can be seen that the input image of the object viewed from one viewpoint reproduces the object viewed from different viewpoints quite accurately.
It is also possible to reconstruct a complete 3D model by combining ``images of objects viewed from different viewpoints'' generated using Zero-1-to-3.

On
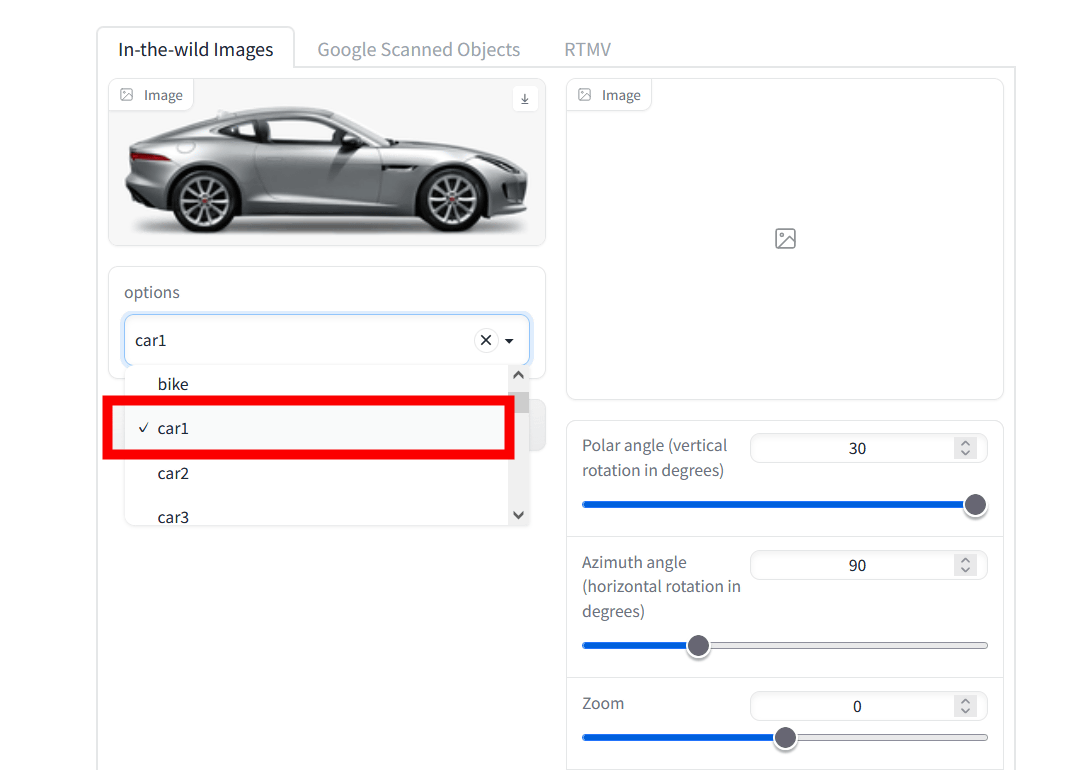
Set the 'Polar angle', 'Azimuth angle', 'Zoom' and 'Random seed' with the slide bar, and click 'Generate Novel Vies'. Generate)'.
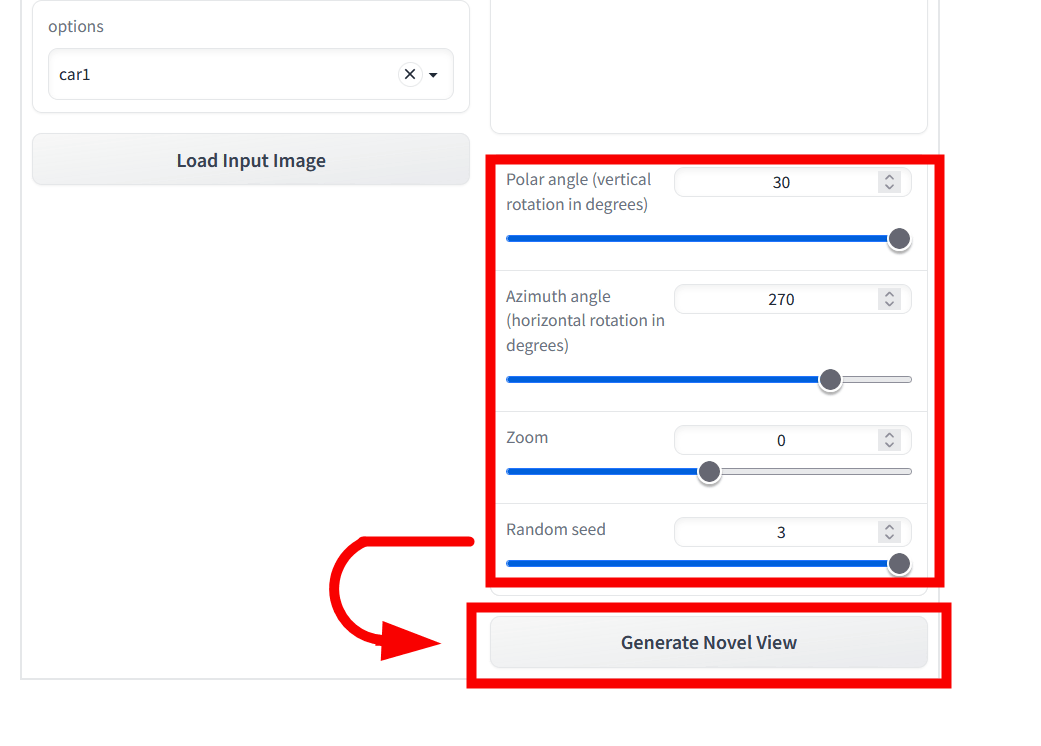
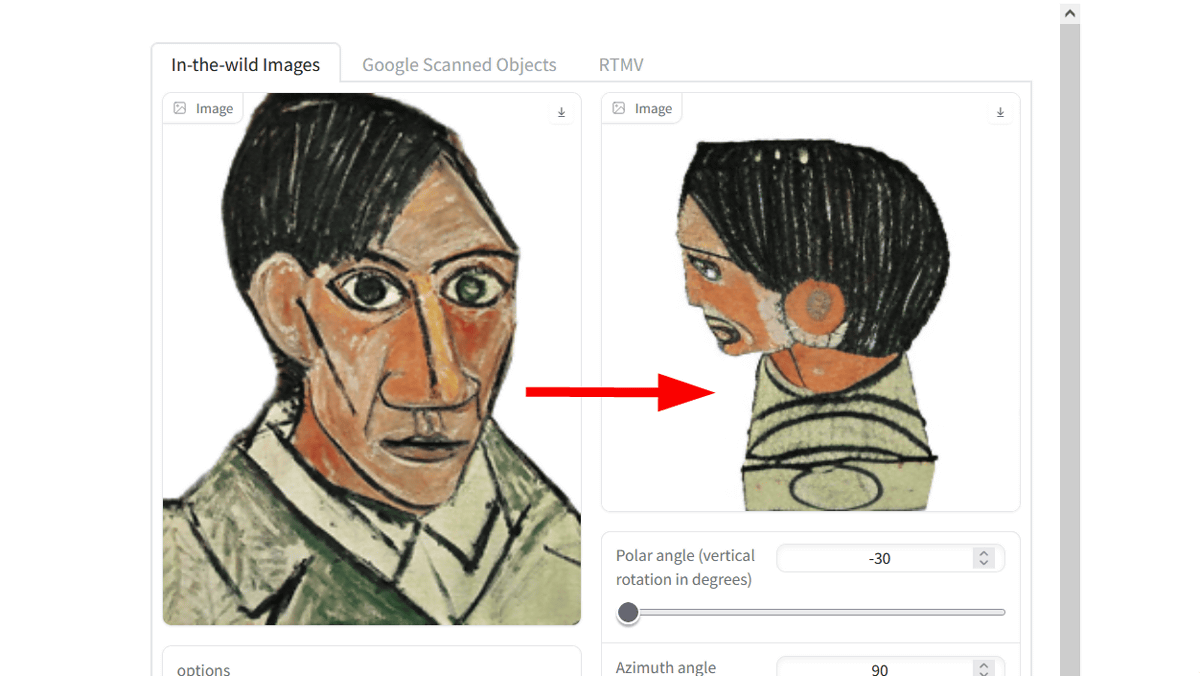
Then, the image seen from the set viewpoint was generated.
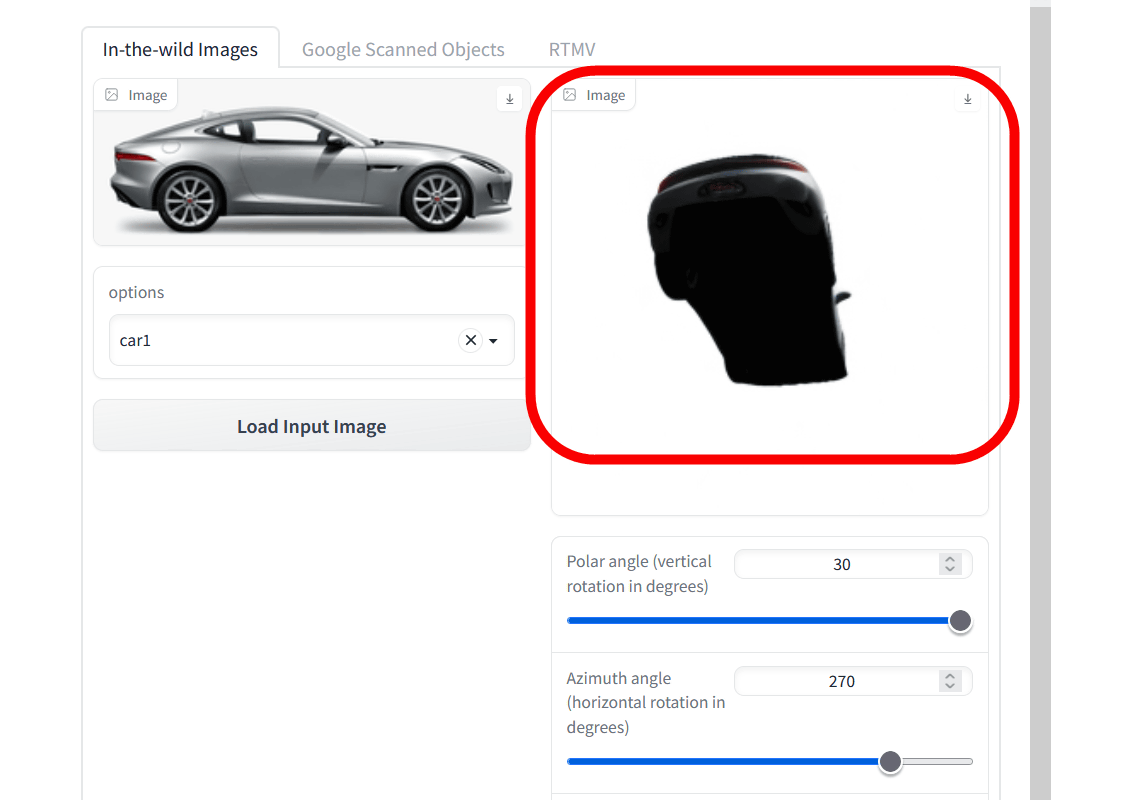
You can generate images from different perspectives, not just one.

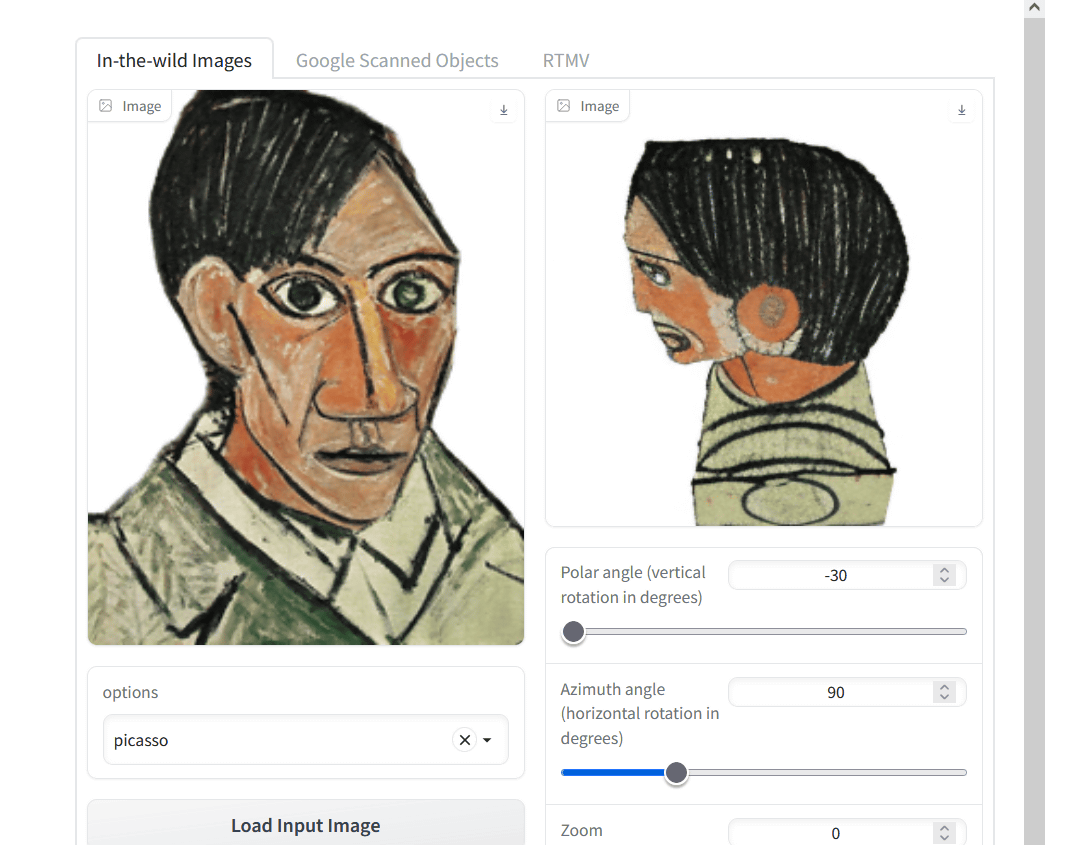
It also works with images with a painting touch.
A Zero-1-to-3 demo page is also available on the AI-related repository site Hugging Face, where you can input your favorite image and output an image with a different viewpoint.
Zero-1-to-3 Live Demo - a Hugging Face Space by cvlab
https://huggingface.co/spaces/cvlab/zero123-live
Related Posts:



in AI, Software, Web Service, Posted by log1h_ik