AI system 'Imagen' that can automatically generate high-precision images even from outlandish texts

' Imagen ', an AI model that can naturally generate high-resolution images even from outlandish text, has been announced. It seems that increasing the size of the language model will greatly improve both the fidelity of the sample and the integrity of the image and the text.
Imagen: Text-to-Image Diffusion Models
The mechanism of 'Imagen' is as follows. First , embed words by using the text encoder T5-XXL. Then convert the text to a 64x64 pixel image using the diffusion model . Furthermore, by applying this to the diffusion model for high resolution twice, it is possible to finally generate a high resolution image of 1024 × 1024 pixels.
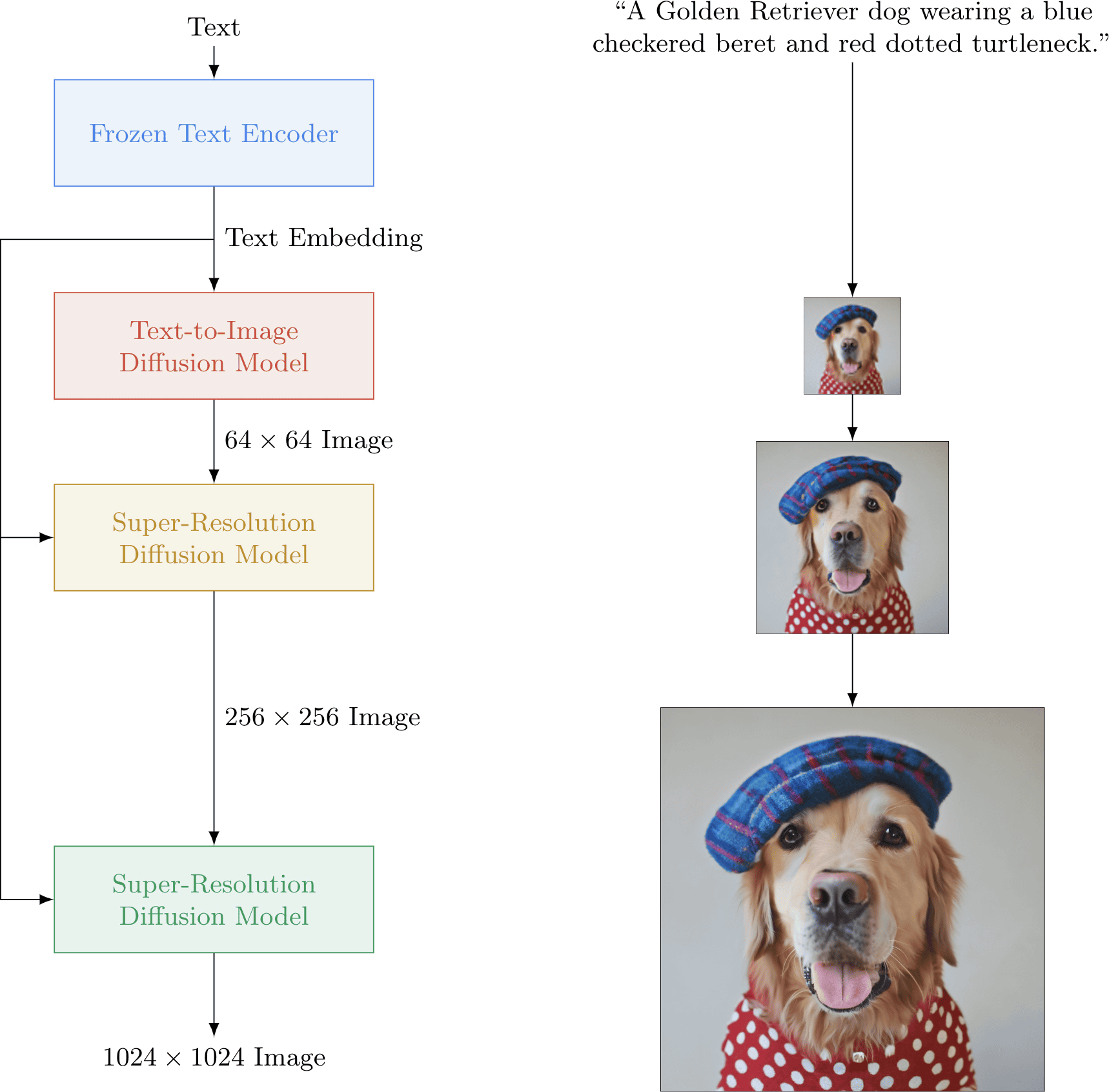
What kind of image can actually be generated from what kind of text Imagen is as follows.
'A raccoon wearing an astronaut's helmet looks at the night view from the window.'

'A couple of robots eating at a fine restaurant with the Eiffel Tower in the background'

'Photo of Corgi wearing sunglasses and a beach hat riding a bicycle in Times Square'

'Google Brain logo and Toronto skyline written in fireworks'

'Corgi in the sushi house'

In addition, there is also an area on Imagen's official page where you can change the generated image by clicking the condition.

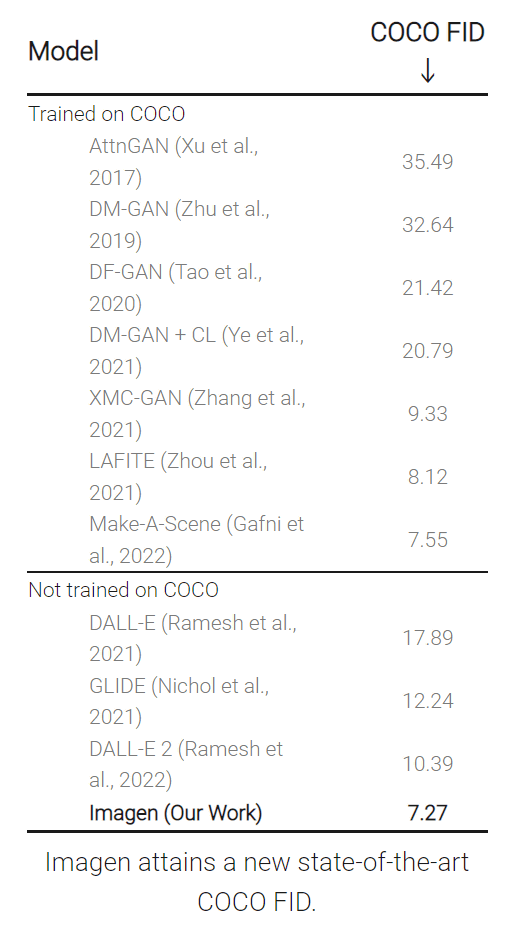
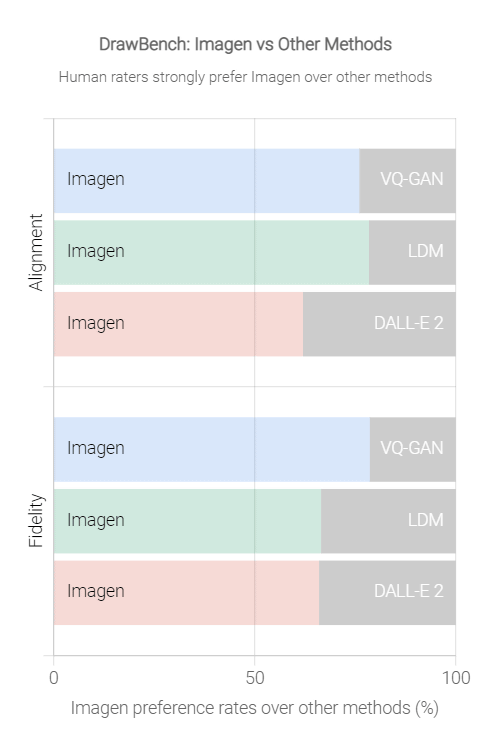
In addition, using 'DrawBench', a benchmark using a human evaluator to evaluate the accuracy of the model that converts text to images, Imagen and VQ-GAN + CLIP, Latent Diffusion Models (LDM),
A research paper on Imagen has also been published and can be checked from the following.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
(PDF file) https://gweb-research-imagen.appspot.com/paper.pdf
Related Posts:








in Software, Posted by logu_ii