




画像を見て質問に答えられるオープンソースなGPT-4レベルのAI「LLaVA-1.5」をGCP上で動作させてみた

Microsoftやウィスコンシン大学マディソン校などの研究チームが開発し、2023年4月17日に公開した「LLaVA」は「視覚」を持つAIで、画像を入力するとその画像に基づいて返答を行うことができます。2023年10月5日に登場したLLaVA-1.5はさらにクオリティが向上しているとのことなので、実際にGoogleのクラウドコンピューティングサービス「Google Cloud Platform(GCP)」上で動作させてみました。
LLaVA/pyproject.toml at main · haotian-liu/LLaVA
https://github.com/haotian-liu/LLaVA
2023年4月にリリースされた旧バージョンの性能や、デモサイトの使い方については下記の記事で確認できます。
画像を認識して年齢推測可能&人名クイズにも正答できる無料の高性能チャットAI「LLaVA」を使ってみた - GIGAZINE
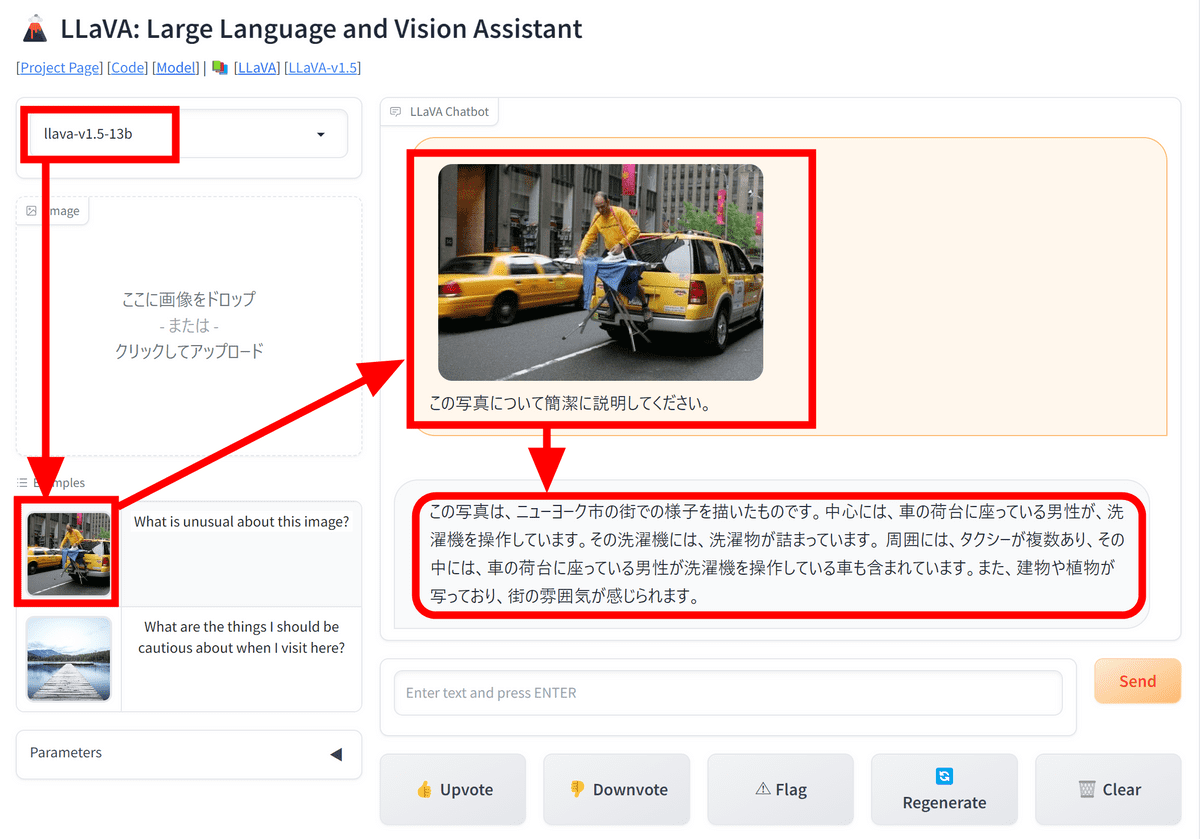
GCP上で動作させてみる前に、一度デモで性能を確認してみます。左上のバージョン選択欄で「llava-v1.5-13b」を選び、サンプル画像を送信して「この写真について簡潔に説明してください」とメッセージを送信するとLLaVAが画像の様子を細かく説明してくれます。旧バージョンでは返答が英語のみとなっていましたが、LLaVA-1.5では日本語で返事してくれる模様です。
「10文字程度で」と注文をつけると大幅に短くまとまりましたが、さらに文体や形式を指定してみても返答は変化しませんでした。あまり細かく注文をつけても対応できないようです。

動作のイメージがつかめたので、早速環境を構築していきます。今回はGCPで構築を行うので、コンソールにアクセスして「VMを作成」をクリック。
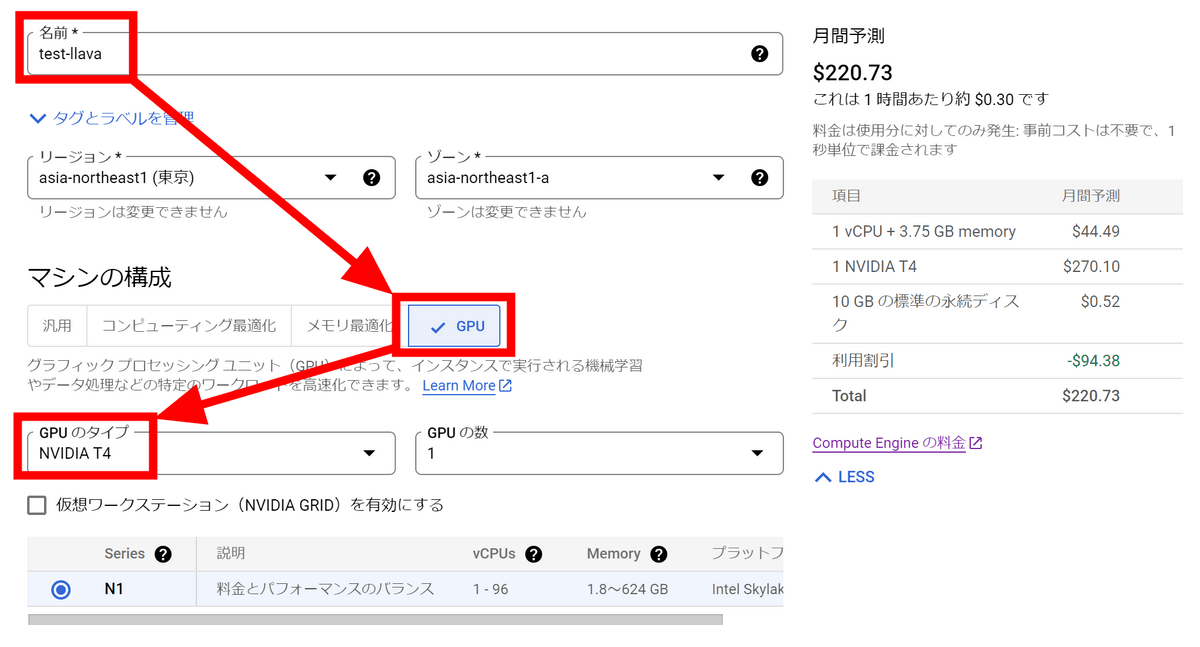
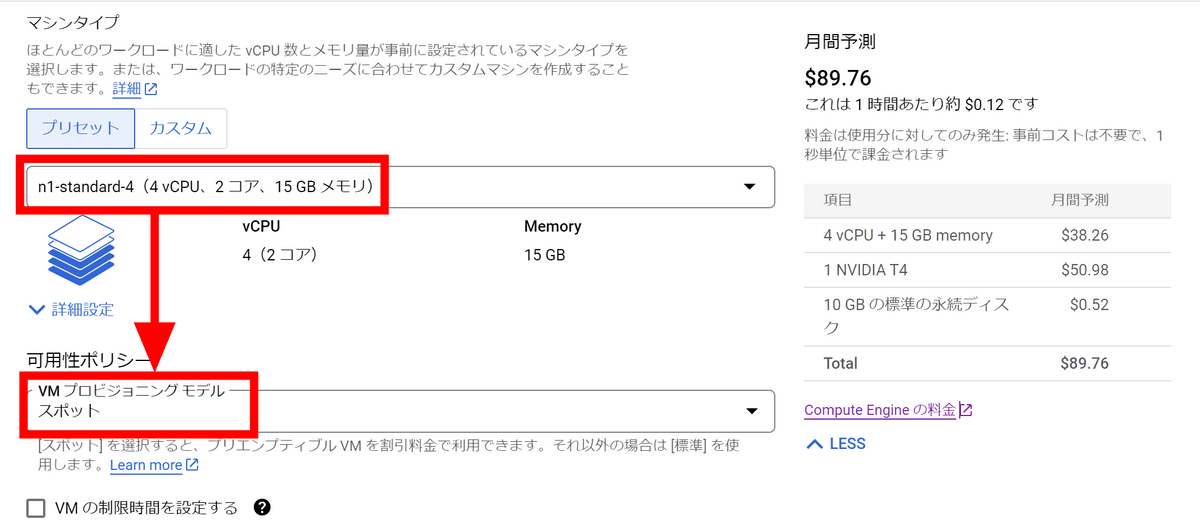
名前欄に「test-llava」と入力し、マシンの構成でGPUを選択します。今回は16GBのVRAMを搭載しているNVIDIA T4を使用することにしました。
マシンタイプは「n1-standard-4」を選択。今回はテスト用ということで、VMプロビジョニングモデルは「スポット」にしました。GCPの都合で突然インスタンスが止まる可能性があるものの、料金を安く抑えることができます。
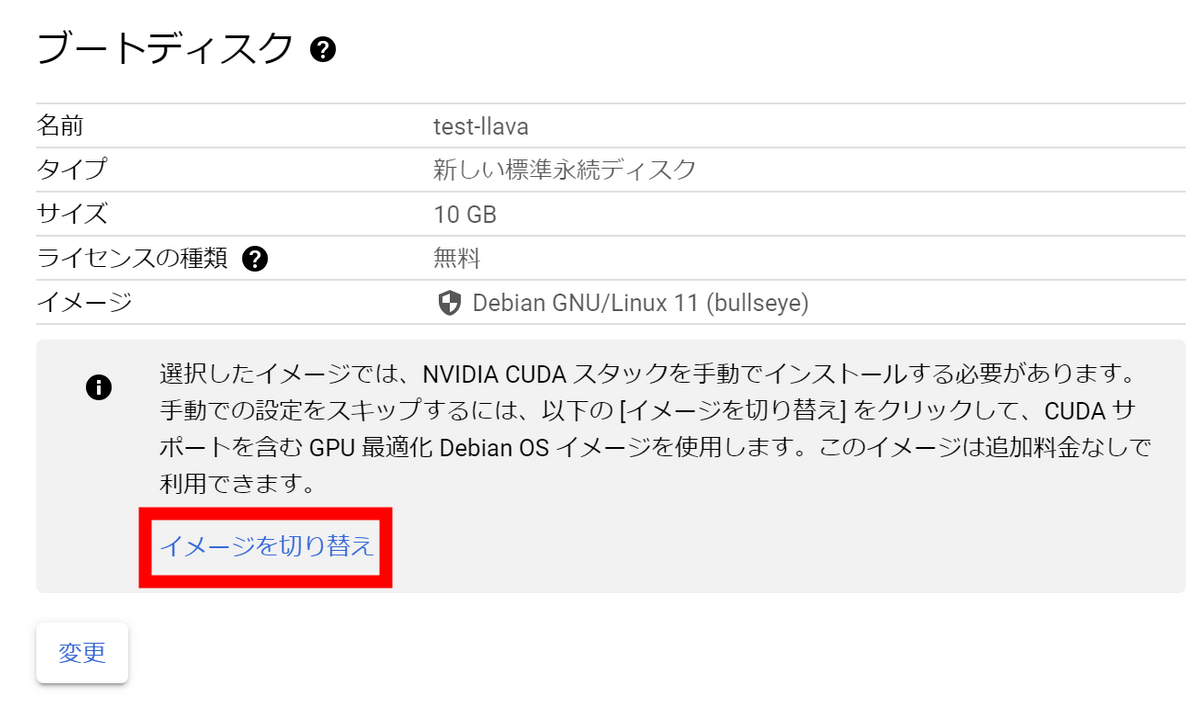
NVIDIA CUDAスタックを手動でインストールする代わりにインストール済みのイメージを使用してブートするので、「イメージを切り替え」をクリックします。
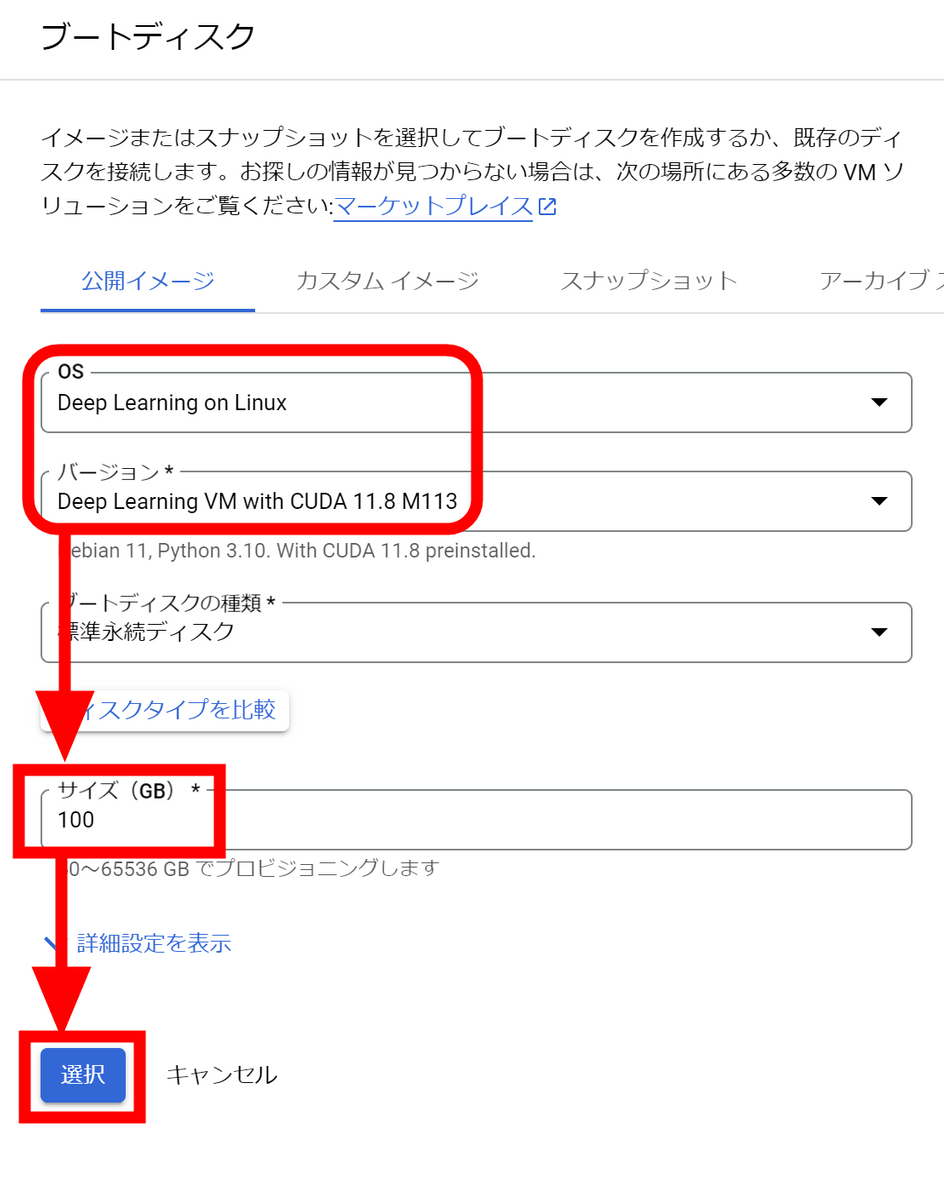
CUDAがプリインストールされているイメージが選択されているので、ディスクのサイズを決めて「選択」をクリック。
画面下部の「作成」ボタンをクリックしてインスタンスを作成します。

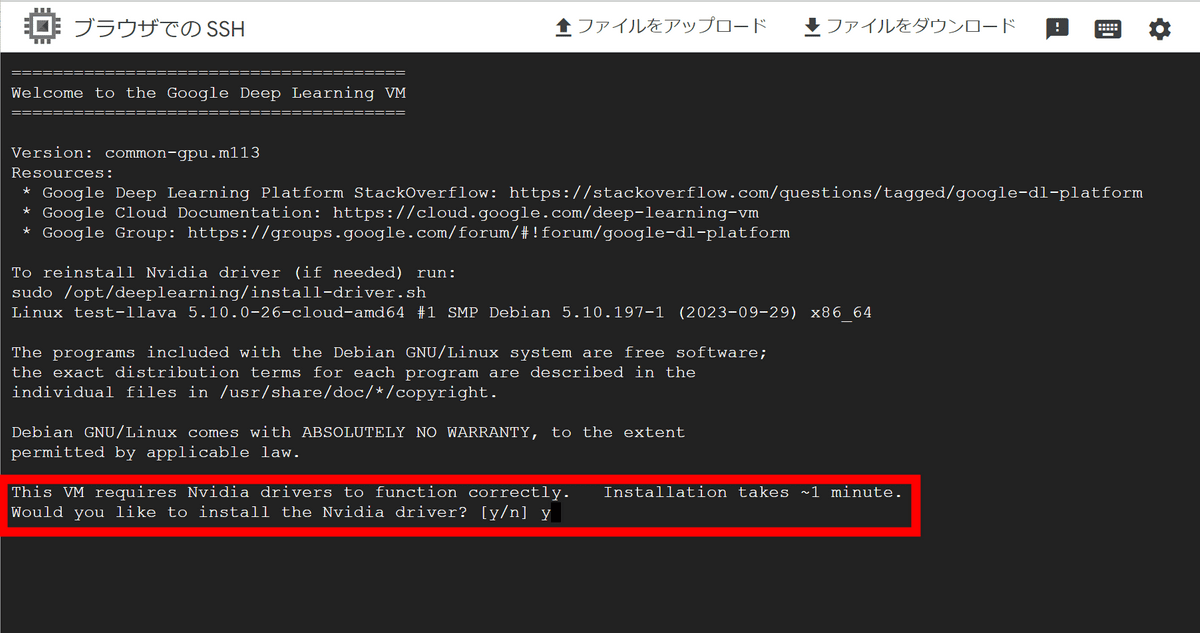
インスタンスが起動したら「SSH」ボタンをクリック。

別ウィンドウが開き、インスタンスにSSHで接続できました。最初にNvidiaのドライバをインストールするか聞かれるので「y」と入力してエンターキーを押します。
続いてLLaVAをインストールします。まずは下記のコマンドを実行してGitHubからリポジトリをクローン。
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
続いて下記のコマンドで必要なライブラリをインストールします。
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
LLaVAのモデル一覧ページでCheckpointのパスを確認します。今回使用したいのはLLaVA-1.5の13Bモデルなのでパスは「liuhaotian/llava-v1.5-13b」とのこと。
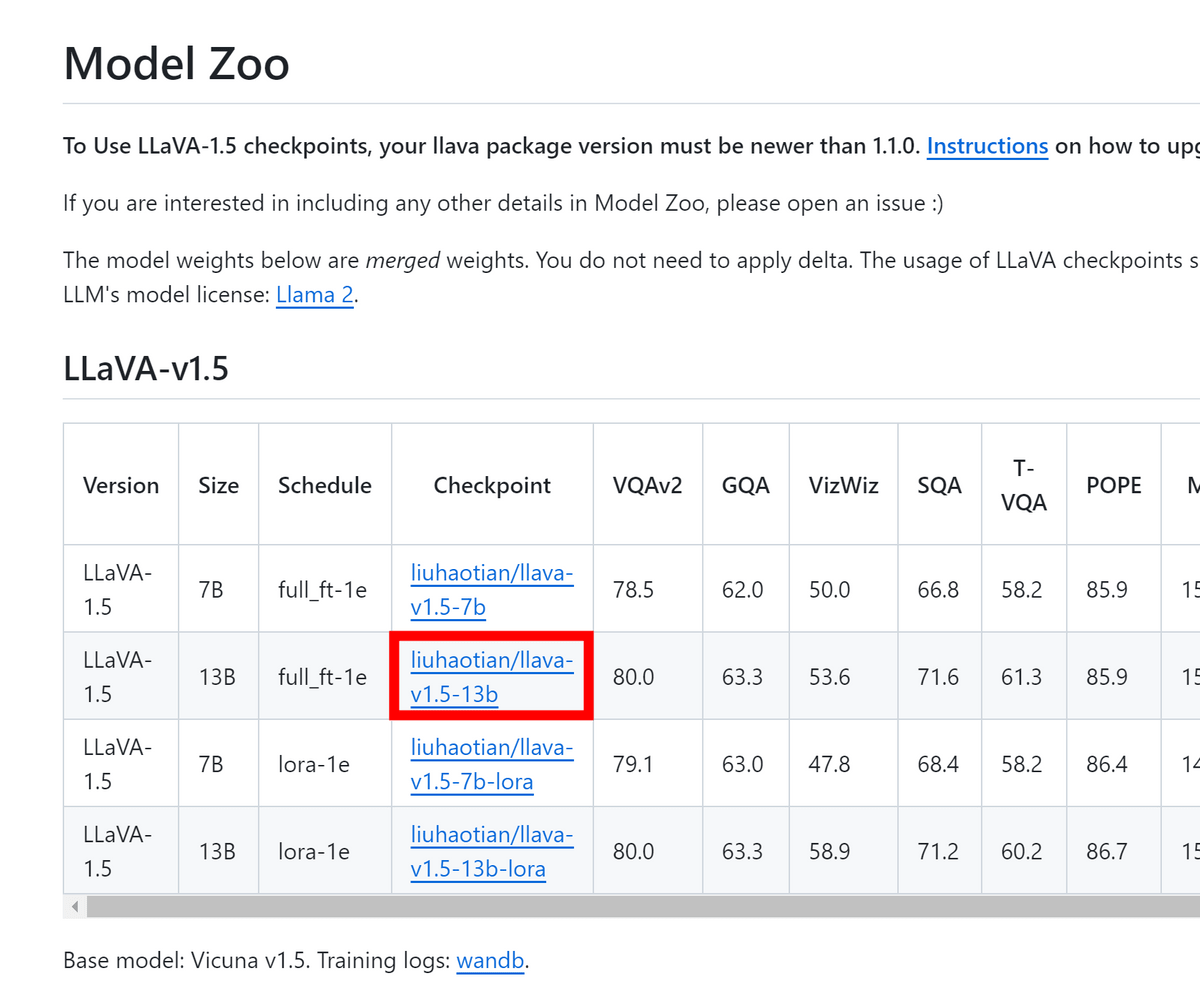
LLaVAを実行するためのコマンドは下記の通り。モデルを「--model-path ~」の形式で指定し、読み込ませたい画像を「--image-file ~」の形式で指定します。画像の指定はインターネット上のパスでもOK。また、フルサイズのモデルをロードするにはVRAMが少なくとも24GB必要とのことなので、「--load-8bit」をつけてメモリの必要量を軽減します。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-13b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-8bit
コードを実行すると自動でモデルのダウンロードが始まりました。
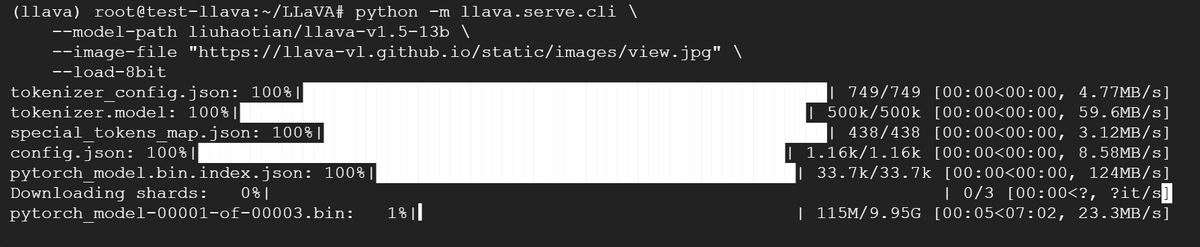
約1時間後、モデルの準備が整い「USER:」と表示されました。早速「画像について10文字程度で簡潔に説明して下さい」とプロンプトを入力します。

しかし「CUDA out of memory」とエラーがでて動作が止まってしまいました。8bit量子化を行っても15GBのVRAMでは足りなかった模様。

今度は「--load-4bit」をつけて4bit量子化を行い、さらにVRAMの必要量を削減します。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-13b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-4bit
30分程度待機するとモデルの準備が完了しました。先ほどと同じプロンプトを送信します。

LLaVAの返答は「A wooden pier over a lake with mountains in the background(背景に山のある湖に浮かぶ木の桟橋)」というものでした。4bit量子化を行ったためか、日本語では回答してもらえませんでしたが、適切に画像について説明できています。

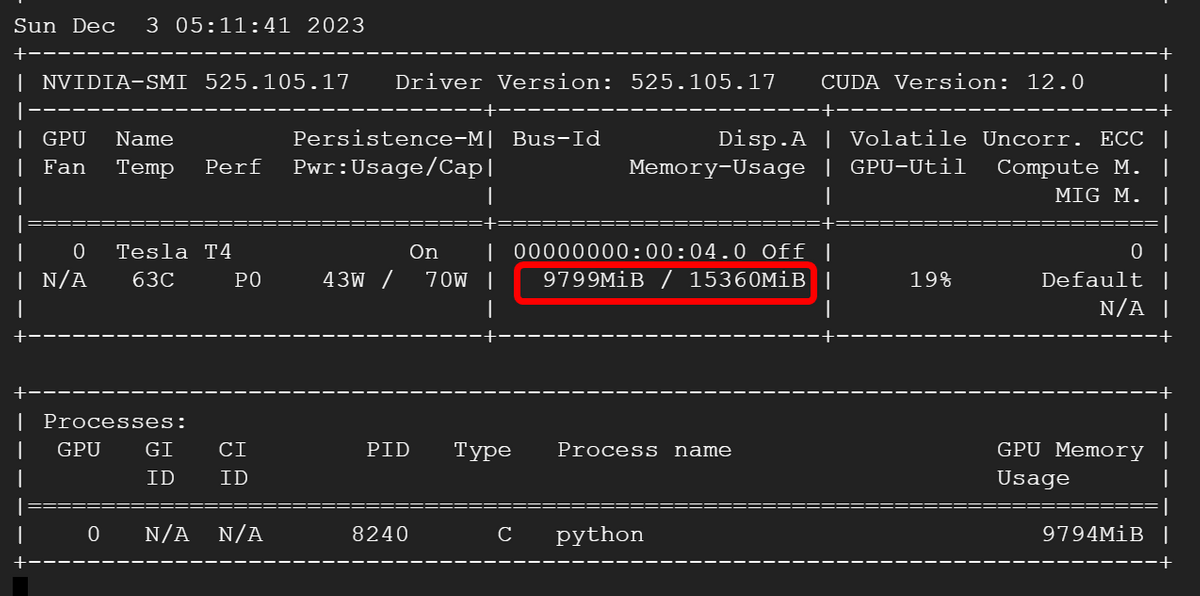
なお、4bit量子化を行ったときのLLaVA-1.5-13BモデルのVRAM消費量は約10GBでした。
・関連記事
さまざまなチャットAIを簡単にローカル環境で動かせるアプリ「Ollama」の公式Dockerイメージが登場 - GIGAZINE
チャット形式でプログラミングが可能なローカルで動作するオープンソースなAIツール「Open Interpreter」を使ってみた - GIGAZINE
ChatGPTを超えるという大規模言語モデル「OpenChat」をローカルで動作させて実力を確かめてみた - GIGAZINE
テキストや画像から動画を生成するAI「Stable Video Diffusion」をStability AIが公開へ - GIGAZINE
大規模言語モデルの「検閲」を解除した無修正モデルが作成されている、その利点とは? - GIGAZINE
・関連コンテンツ





in ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article I tried running the open source GPT-4 le….