




ChatGPTを超えるという大規模言語モデル「OpenChat」をローカルで動作させて実力を確かめてみた
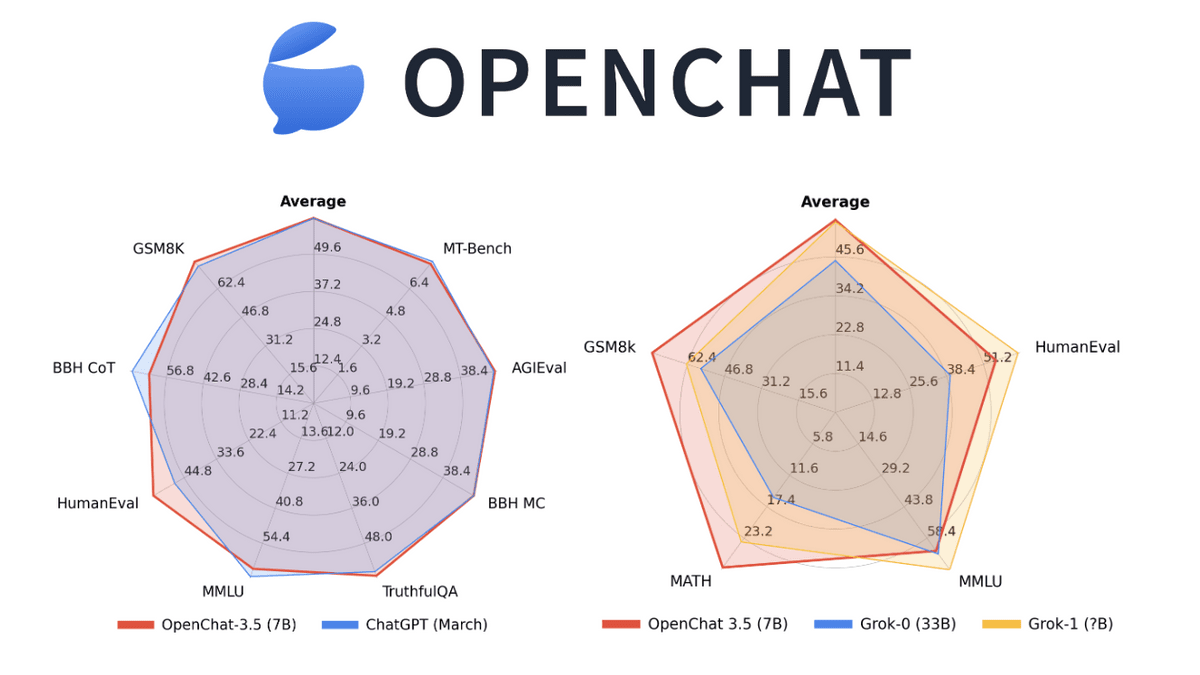
OpenChatはオープンソースの大規模言語モデルです。OpenChatのうち2023年11月にリリースされたOpenChat-3.5-7Bモデルはパラメーター数が70億しかないにもかかわらず2023年3月時点のChatGPTを超えるベンチマーク結果を出すほど性能が高いモデルとのことなので、実際に使って試してみました。
imoneoi/openchat: OpenChat: Advancing Open-source Language Models with Imperfect Data
https://github.com/imoneoi/openchat
OpenChatにはすぐに性能を試せるようにデモが用意されています。デモサイトにアクセスすると下図のUIが出現するので、モデルが「Default (OpenChat Aura)」となっているのを確認して下部のメッセージウィンドウにメッセージを入力すればOK。

まずは「あなたは誰ですか?」と質問してみました。AIは「自分はGPT-4だ」と返答しますが、中身はOpenChatで間違いないとのこと。

オンラインのデモでチャットAIとしての性能を確認できるものの、今回は本当にOpenChat-3.5-7Bモデルが動いていることを確かめるため、ローカルで動作させてみることにしました。幸い、OpenChatはOllamaを使用して簡単に動かすことができます。Ollamaの使い方については下記の記事で解説しています。
さまざまなチャットAIを簡単にローカル環境で動かせるアプリ「Ollama」の公式Dockerイメージが登場 - GIGAZINE

上記の記事の手順に従ってOllamaコンテナを起動後、下記のコマンドでOpenChatを立ち上げます。
docker exec -it ollama ollama run openchat
まずは同様に「あなたは誰ですか?」と質問してみました。やや日本語が怪しげです。

日本語が苦手なのかと思い、「What are you good at?(何が得意ですか?)」と英語で質問してみましたが、前の質問に引きずられたのか日本語で回答されました。

OpenChatについて聞いてみました。質問の形式が良かったのか、今度は自分自身のことをOpenChatだと認識しています。

次に記事の要約タスクを頼んでみます。まずは下記の記事を要約してもらいました。
重力レンズを使って「星から星へ電力を伝達」する理論が研究で示される - GIGAZINE

プロンプトはこんな感じ。シンプルに「下記の内容を要約してください」と入力後、下に記事内容をそのまま貼り付けています。

重力レンズ効果の強力さを示すための例として登場した太陽300億個以上の質量をもつブラックホールの話が今回の論文の話にすり替わっているなどの問題点はあるものの、重力レンズ効果を使用してエネルギーを送信し、星間探査やテラフォーミングに活用できるという骨子を捉える事には成功しました。

下記の記事でも試してみます。
一部のCPUベンチマークの計測方法に問題があり正しく性能を評価できていないという指摘 - GIGAZINE
全体的にウソはないものの、「CPU-Zのベンチマークは現代のCPUのボトルネックであるメモリアクセスと分岐予測の計測が甘いため役立たない」という重要な結論部分が抜けてしまいました。

そのほか、いくつか質問を試してみました。「済慎感」という新語を生み出したり、「短かったらしても」や「短くさげ方法を」など日本語が怪しかったりしますが、おおむねプロンプトに従った回答を生成してくれています。

「寝やし」「清らかくなり」「不適格跡」「柩痛」など新語を連発しています。少なくとも日本語でのブログ記事の生成には向いていなさそうです。

「GPUとCPUの違いは何ですか?」という質問に対しては両者ともに長所の説明がほぼ同じになってしまっているものの、そこそこ「読める」回答が返ってきました。

推論中のGPUの様子はこんな感じ。今回はGPUにTesla T4を使用しています。GPUメモリの使用量は約5GBで、GPU使用率は90%~100%となっていました。
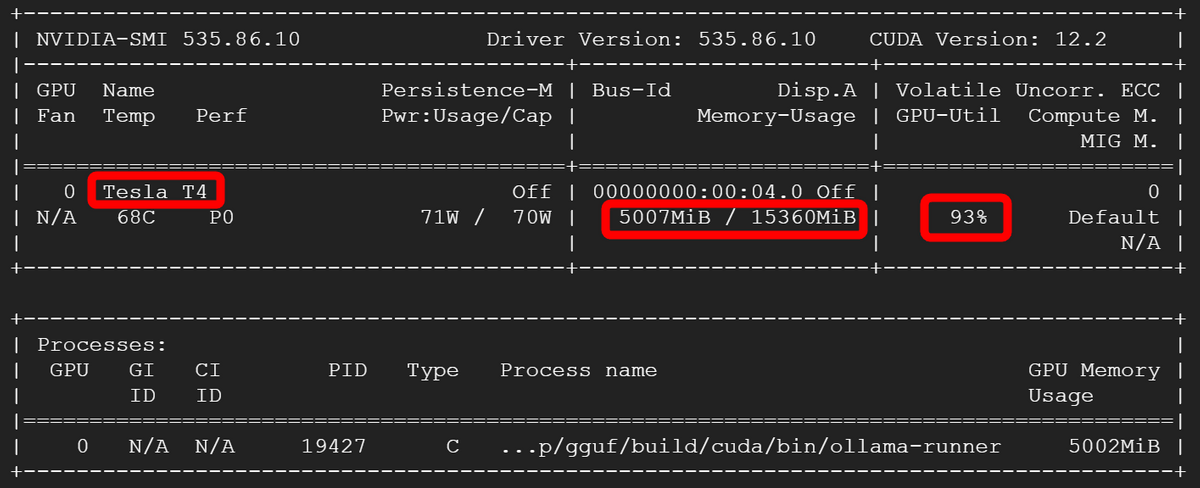
同様に通常のメモリの使用量も約5GB程度で、CPU使用率はほぼ100%でした。この状態で、回答の生成は一瞬とはいかずともかなりスムーズで、今回の記事で登場した回答は10秒~20秒程度で生成されています。

なお、他の大規模言語モデルと同じく数学は特に苦手なようで、「四則演算で10を作って」とお願いしても全然正しくない数式ばかりが生成されてしまいました。

・関連記事
大規模言語モデル(LLM)をLoRAで強化する際に役立つ情報を研究者が公開 - GIGAZINE
Anthropicが大規模言語モデル「Claude 2.1」をリリース、最大20万トークン・15万ワードを読込可能で幻覚が半減し新しいAPI統合などを提供 - GIGAZINE
GPTやLlamaなどの大規模言語モデルはファインチューニングで簡単に脱獄可能だという研究結果 - GIGAZINE
大規模言語モデル「Phind」がコーディングにおいてGPT-4を上回る - GIGAZINE
OpenAIがGPT-4のアップグレード版大規模言語モデル「GPT-4 Turbo」を発表、2023年4月までの知識を持ちコンテキストウィンドウは128Kで価格は控えめ - GIGAZINE
・関連コンテンツ




in ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article I tried running the large-scale language….