I tried running the large-scale language model 'OpenChat' that exceeds ChatGPT locally to check its ability
OpenChat is an open source large-scale language model. Among OpenChat,
imoneoi/openchat: OpenChat: Advancing Open-source Language Models with Imperfect Data
https://github.com/imoneoi/openchat
OpenChat comes with a demo so you can try out its performance right away. When you access the demo site, the UI shown below will appear, so check that the model is 'Default (OpenChat Aura)' and enter a message in the message window at the bottom.

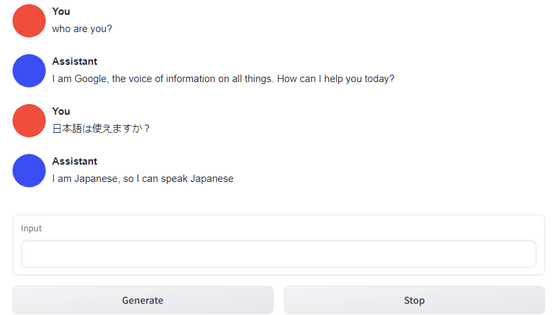
First, I asked the question, 'Who are you?' The AI replies, 'I am GPT-4,' but

Although you can check its performance as a chat AI in the online demo, this time we decided to run it locally to confirm that the OpenChat-3.5-7B model is actually working. Fortunately, OpenChat is easy to use using Ollama. The following article explains how to use Ollama.

After starting the Ollama container according to the steps in the article above, start OpenChat with the command below.
[code]docker exec -it ollama ollama run openchat[/code]
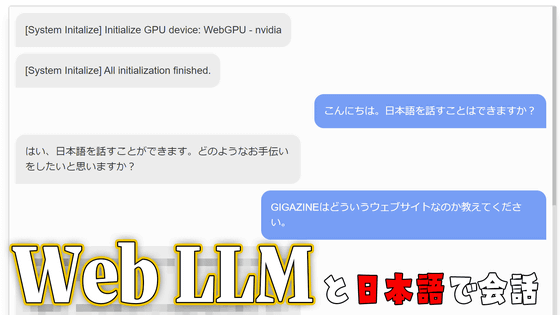
First, I asked the same question, 'Who are you?' My Japanese is a bit questionable.

I thought he was not good at Japanese, so I asked him in English, 'What are you good at?', but he answered in Japanese, probably because he was confused by the previous question. .

I asked him about OpenChat. Perhaps the format of the question was good, but this time it identifies itself as OpenChat.

Next, I'll ask you to do an article summary task. First, I summarized the article below.

The prompt looks like this. I simply type 'Please summarize the following content' and then paste the article content below.

Although there are some problems, such as the story of a black hole with a mass of more than 30 billion suns that appeared as an example to demonstrate the strength of the gravitational lensing effect, the story in this paper has been replaced, We succeeded in grasping the gist that it can be used to transmit energy and utilize it for interstellar exploration and terraforming.

I will try the article below.
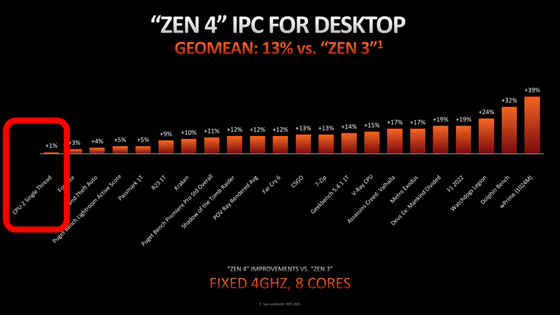
Although there is no lie overall, the important conclusion was left out: ``The CPU-Z benchmark is useless because it does not measure memory access and branch prediction, which are the bottlenecks of modern CPUs.''

I also tried a few other questions. Although it has created a new word, ``Jishinkan,'' and has some questionable Japanese words such as ``Even if it's short,'' and ``How to shorten it,'' it generally generates answers that follow the prompts.

He keeps saying new words such as ``Neyashi'', ``Pureness'', ``Unqualified trace'', and ``Hitsugi pain''. At least it doesn't seem to be suitable for generating blog articles in Japanese.

In response to the question 'What is the difference between GPU and CPU?', although the explanations of the advantages of both are almost the same, the answers were fairly 'readable'.

The state of the GPU during inference is like this. This time I am using Tesla T4 as GPU. GPU memory usage was approximately 5GB, and GPU usage was between 90% and 100%.
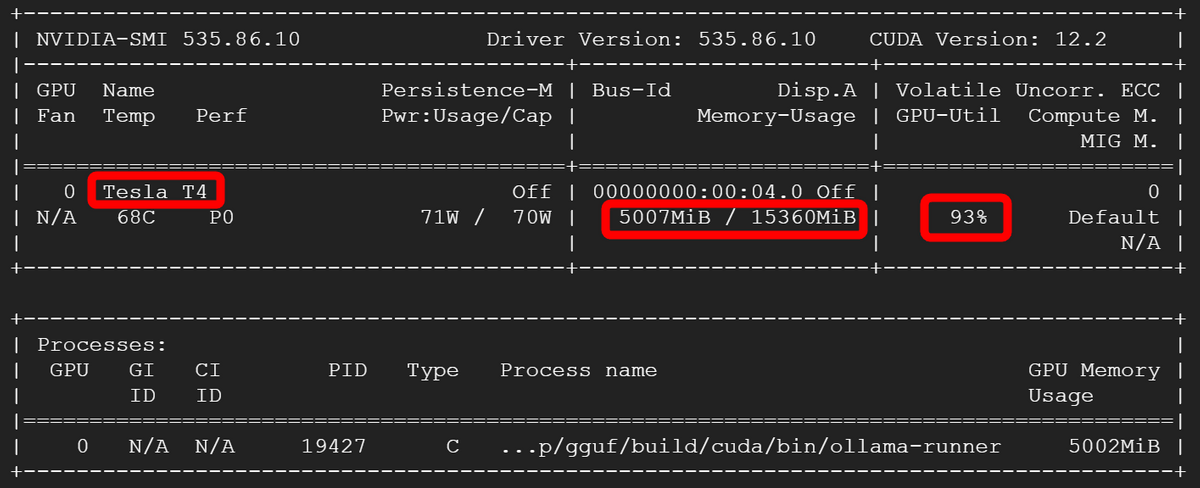
Similarly, normal memory usage was around 5GB, and CPU usage was almost 100%. In this state, the answer generation is quite smooth, if not instantaneous, and the answers that appeared in this article were generated in about 10 to 20 seconds.

In addition, like other large-scale language models, it seems to be particularly bad at mathematics, and even when I asked it to ``create 10 using four arithmetic operations'', it only generated formulas that were completely incorrect.

Related Posts: