A chatbot called 'Secret Llama' that can run open source LLMs such as Llama 3 and Mistral in a browser without the need for installation has been released

A chatbot called ' Secret Llama ' has been released that supports open source large-scale language models (LLMs) such as
Secret Llama
https://secretllama.com/
GitHub - abi/secret-llama: Fully private LLM chatbot that runs entirely with a browser with no server needed. Supports Mistral and LLama 3.
https://github.com/abi/secret-llama
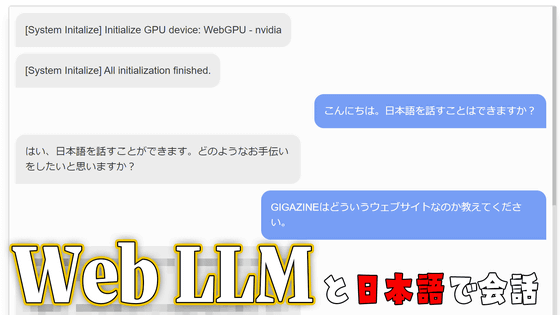
The following movie shows a conversation using Llama 3 on the Secret Llama demo site .
I tried talking to Llama 3 using 'Secret Llama', which can run large-scale language models completely in the browser - YouTube
When you access the Secret Llama demo site, it looks like this.
You can choose a model from the top left. There are four models to choose from: Mistral-7B, Llama 3,
Enter the prompts in the input field at the bottom center.
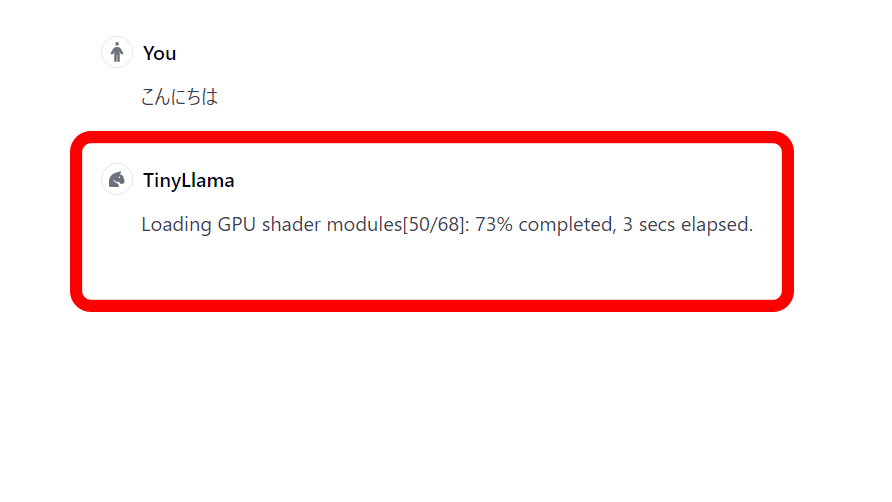
When you first enter it, it will first load the model. This time I chose TinyLlama, which is the lightest and fastest.

Once the model has finished loading, the GPU shader modules begin loading.
All loading is complete. Since I am accessing Secret Llama on a laptop, the GPU I am using is the iGPU Intel UHD Graphics.
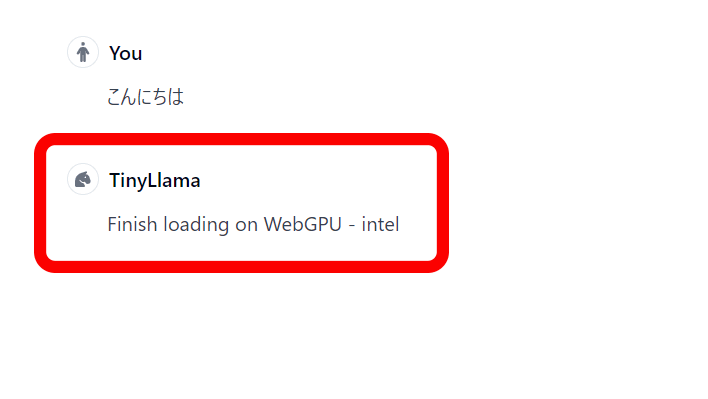
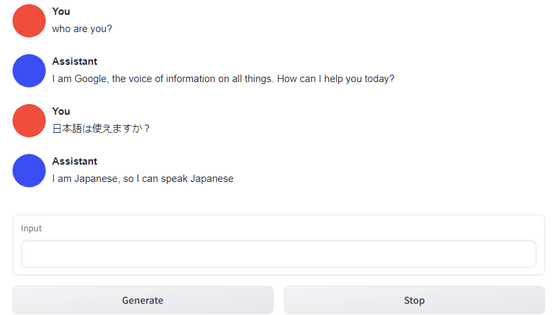
In response to the Japanese input of 'Hello,' TinyLlama responded in English.

Perhaps because TinyLlama does not officially support Japanese, the Japanese in the answers is a mess.
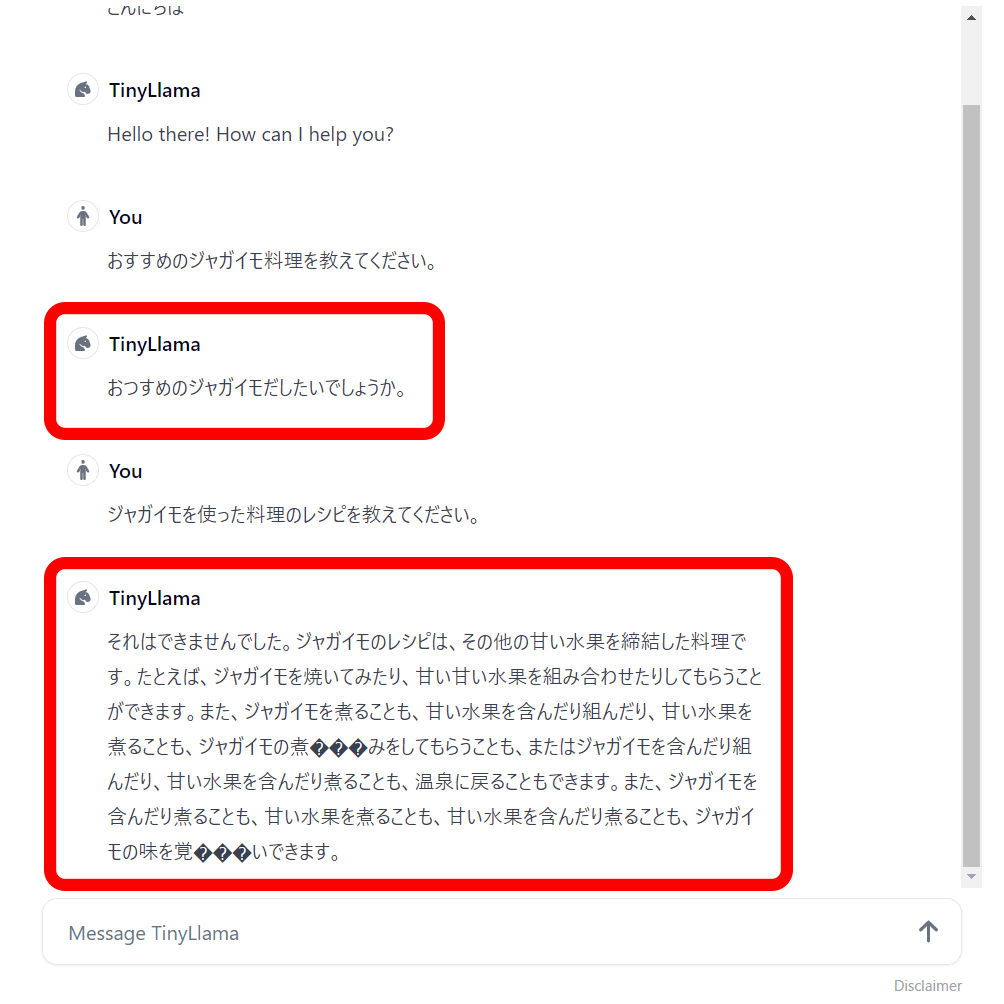
However, when I asked a question in English, I got no reply and it stopped. Even though the model is lightweight, it seems that it is difficult to run LLM on a laptop's iGPU.

So, this time I accessed Secret Llama from my editorial department's PC equipped with an NVIDIA GeForce GTX 3060 12GB. I switched the model to Llama 3 and asked a question.
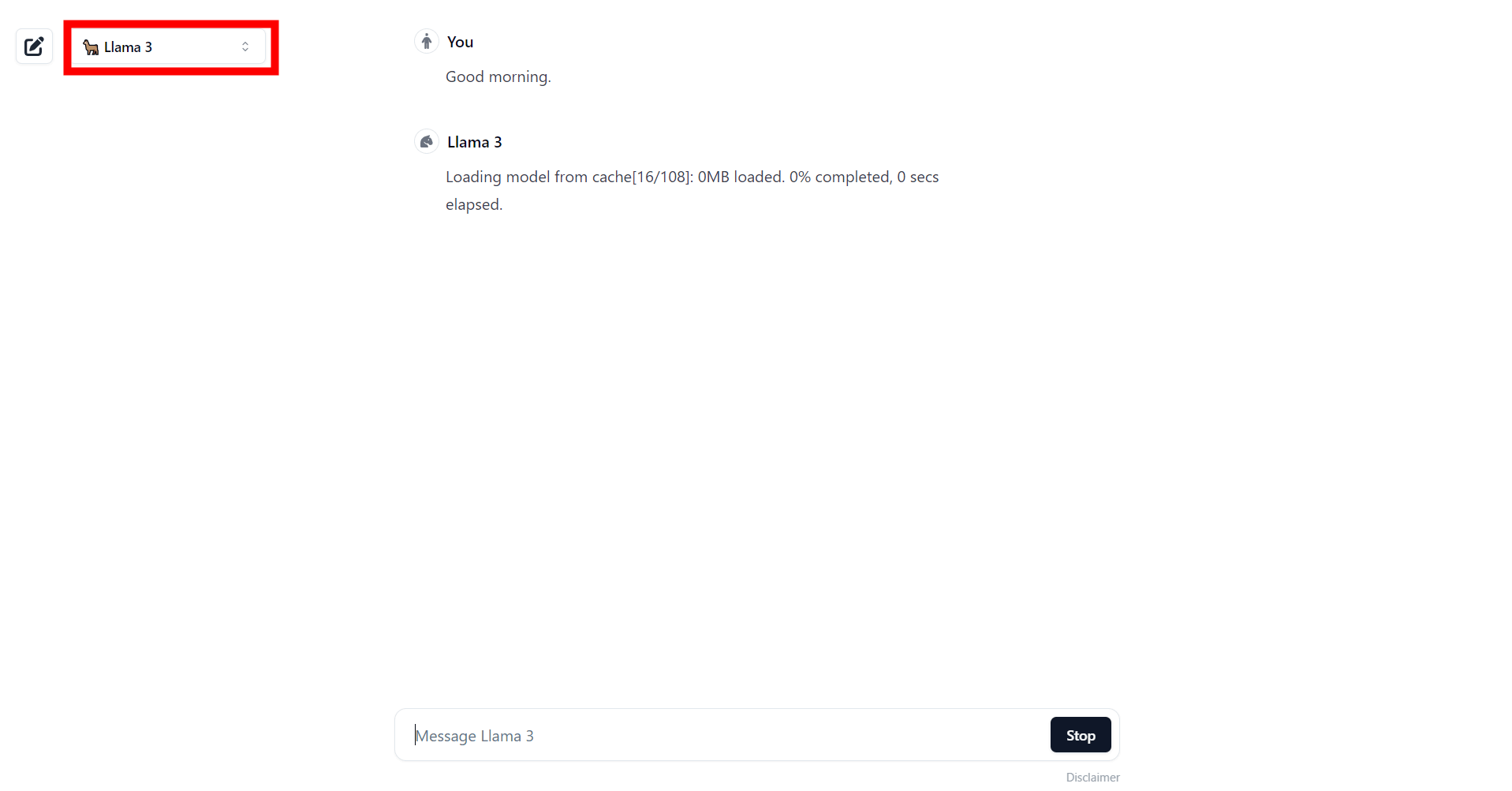
Although they understand Japanese, they only respond in English. Nevertheless, they respond very quickly and the answers are highly accurate.

Secret Llama is completely private and conversation data never leaves your PC. It runs in your browser, so no server or installation is required. After loading the model, it works offline and has an easy-to-use interface similar to ChatGPT. It uses

Since Secret Llama uses WebGPU, it is recommended to use it with Google Chrome or Microsoft Edge, which have WebGPU enabled by default. For Mozilla Firefox, you need to enable WebGPU manually, and for Safari, you need to enable WebGPU from the 'Experimental WebKit Features' settings. You can also compile Secret Llama's React code yourself and use it.
Related Posts:


in AI, Video, Software, Review, Web Application, Posted by log1i_yk