Summary of how to use ``Text generation web UI'', a tool that makes it possible to use language models distributed for free in a chat-like UI
A tool that makes it easy to use language models such as GPT and LLaMA with a web application-like UI is ' Text generation web UI 'is. It is a convenient tool that makes it easy to download new models and switch between multiple models, so I immediately tried it out.
GitHub - oobabooga/text-generation-webui: A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, OPT, and GALACTICA.
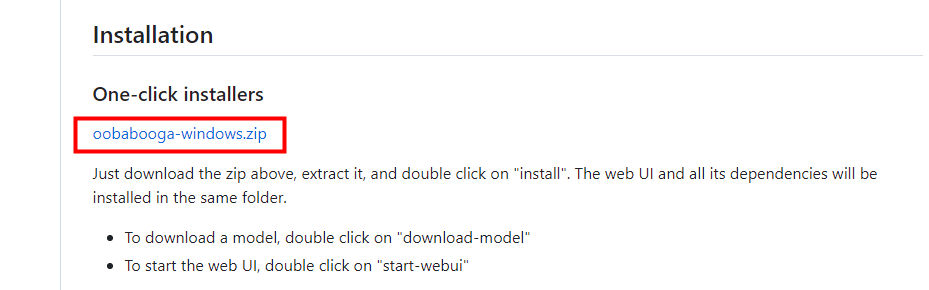
This time, we will use 'One-click installers' at the top of Installation. Click 'oobabooga-windows.zip'.
Right-click the downloaded ZIP file and click Extract All.
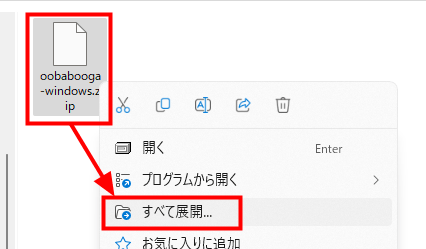
Double-click 'install.bat' from the extracted files to execute it.
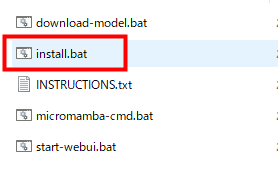
A bat file downloaded from the Internet will give a security warning when it is executed for the first time, but if you click 'Execute' it is OK. Same for other bat files.
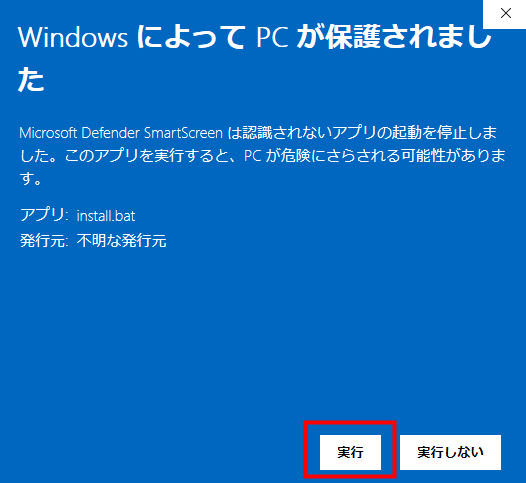
You will be asked for your GPU type. Since the PC used this time has a GPU made by NVIDIA, enter 'A' and press the enter key.
Then the installation started. The required files will be downloaded automatically.
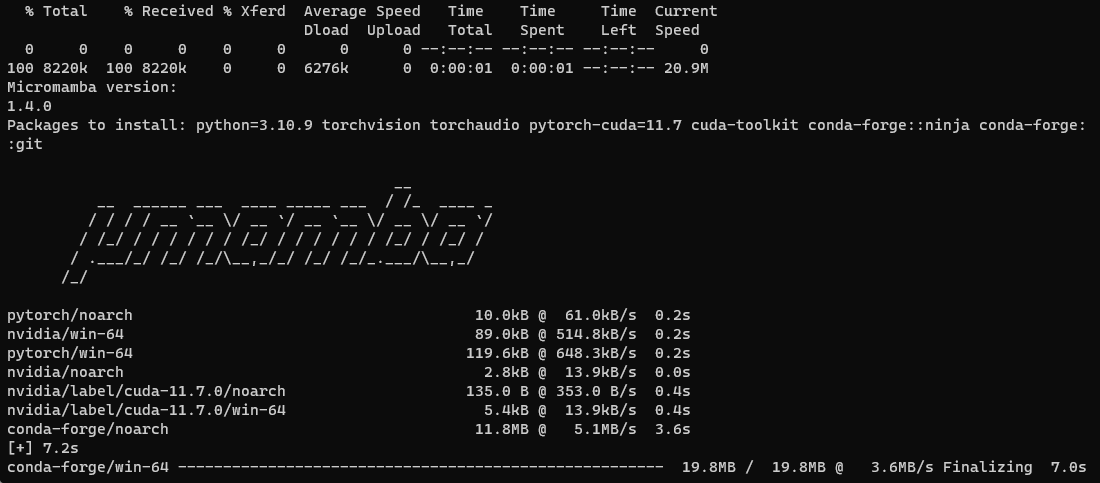
After about 15 minutes, the installation completed.

Then download the language model. Double-click 'download-model.bat'.
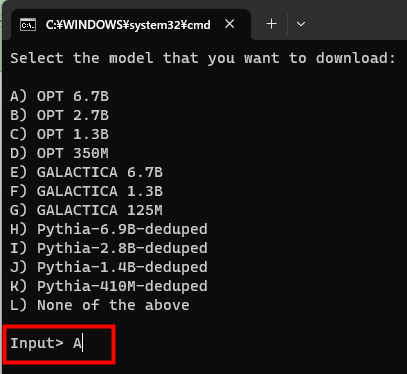
Download completed.

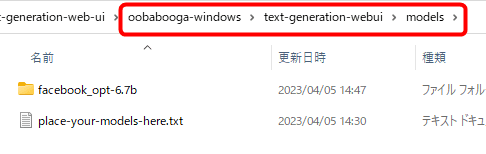
The downloaded model is saved in the 'models' folder inside 'text-generation-webui' in the same folder as 'download-model.bat'. If you prepare a model from other than Hagging Face, you can save the model data directly in this folder.
When the model data is ready, double-click 'start-webui.bat'.
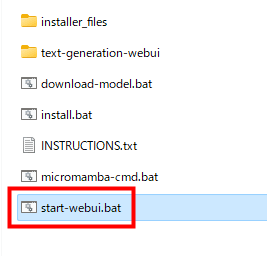
Loading of model data starts. Once loaded, the server will start and you will be presented with a URL to access.
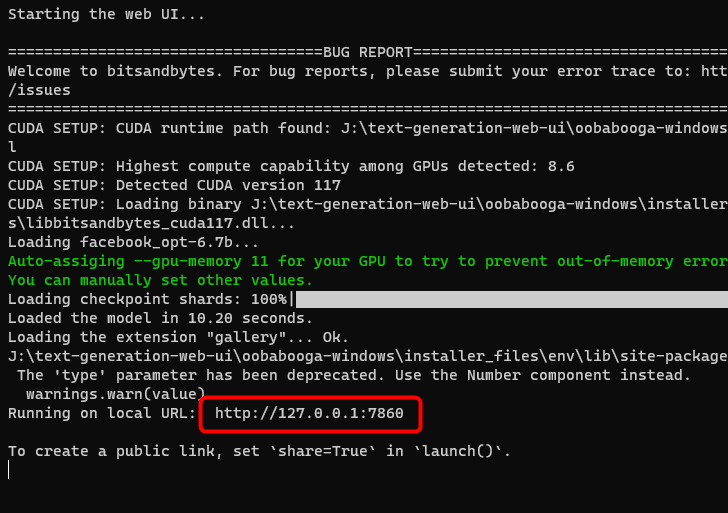
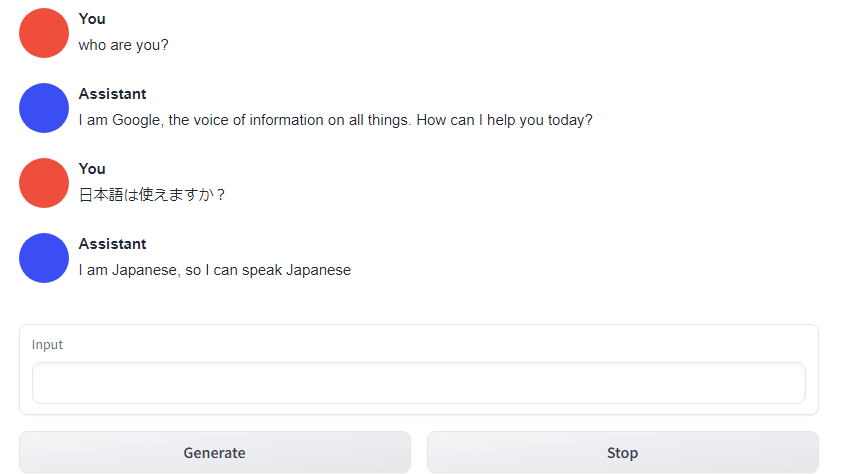
When you enter the URL in the web browser, the screen of the application will be displayed. The upper tab is 'Text generation', and the conversation space with AI is displayed below.
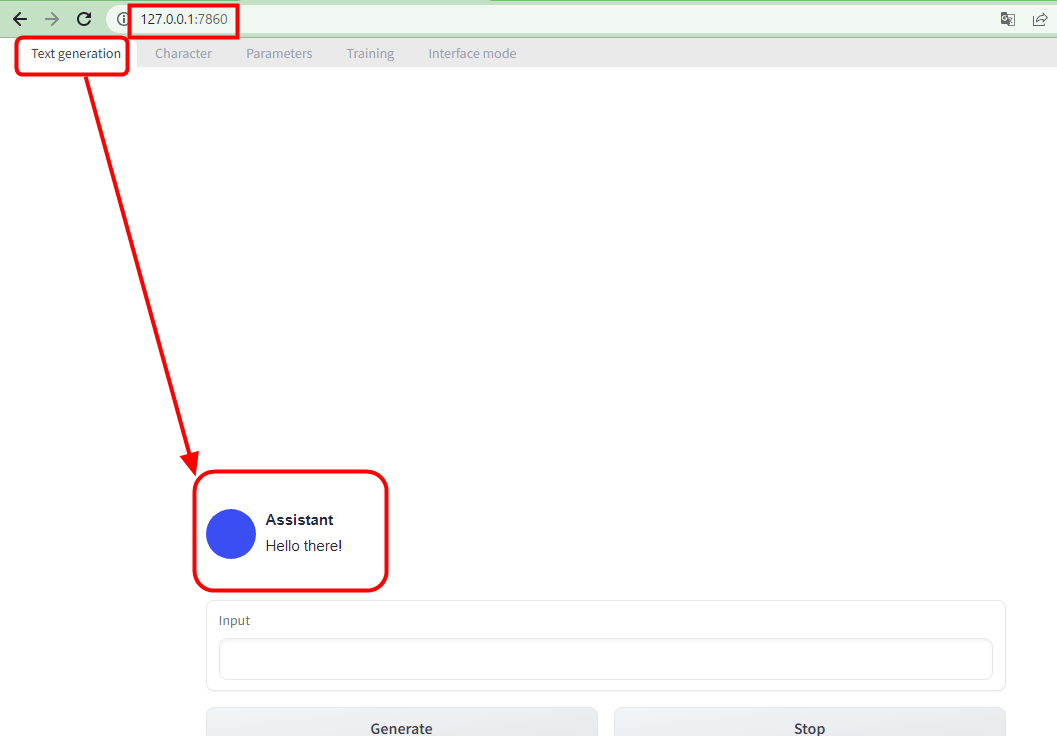
It is a standard configuration that if you put words in the input field and press 'Generate', AI will reply.
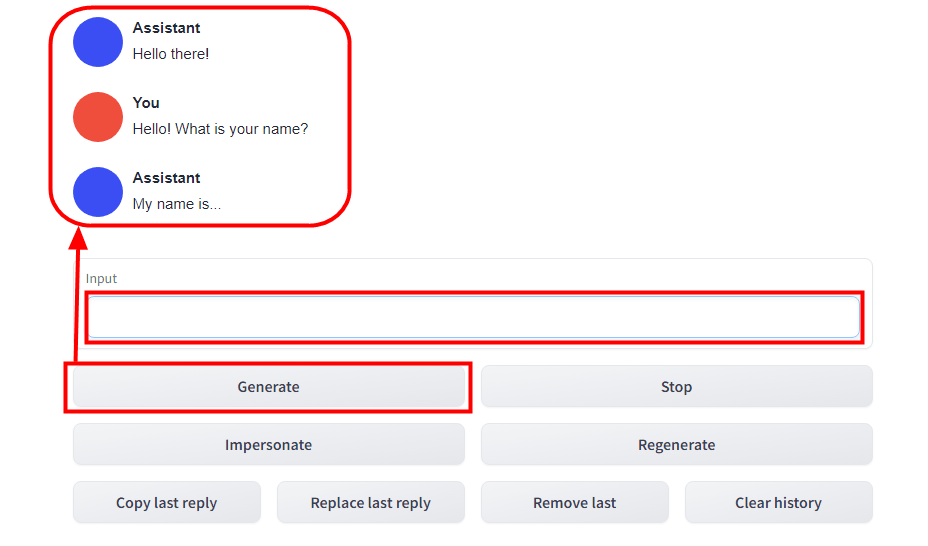
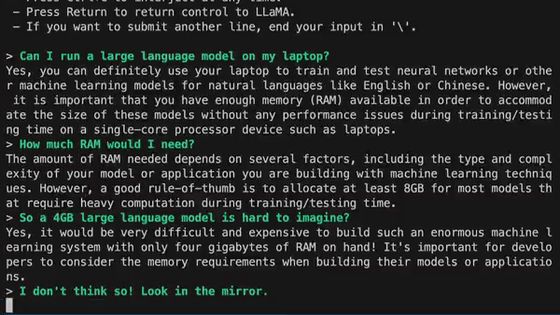
When I checked whether Japanese can be input, there was no problem in terms of UI. On the other hand, the reply of the OPT 6.7B model used this time is 'I can speak Japanese', so it is quite difficult to judge whether the model can speak Japanese.
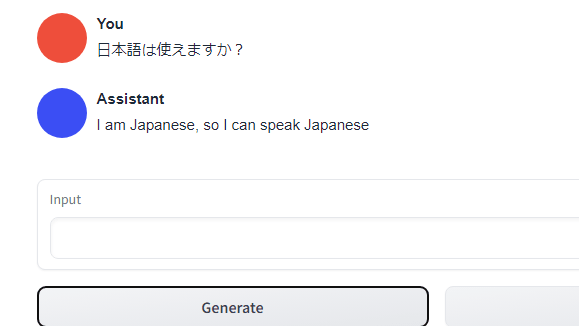
If you click the 'Impersonate' button, AI will think of your reply. When I tried pressing it, Japanese was generated normally, and the possibility that the previous reply was an advanced gag came out. AI is also hard to be underestimated.
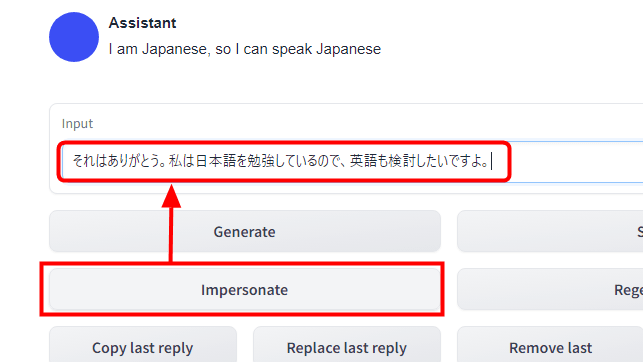
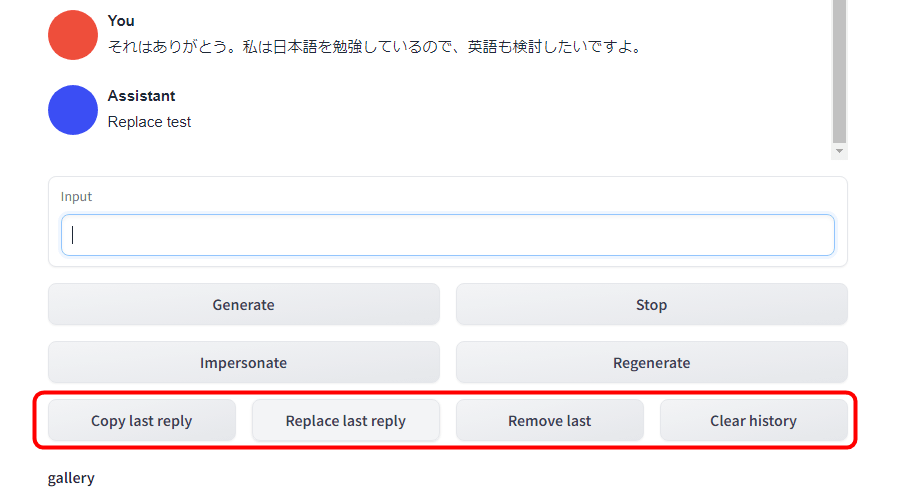
Also, when you click the 'Regenerate' button ...
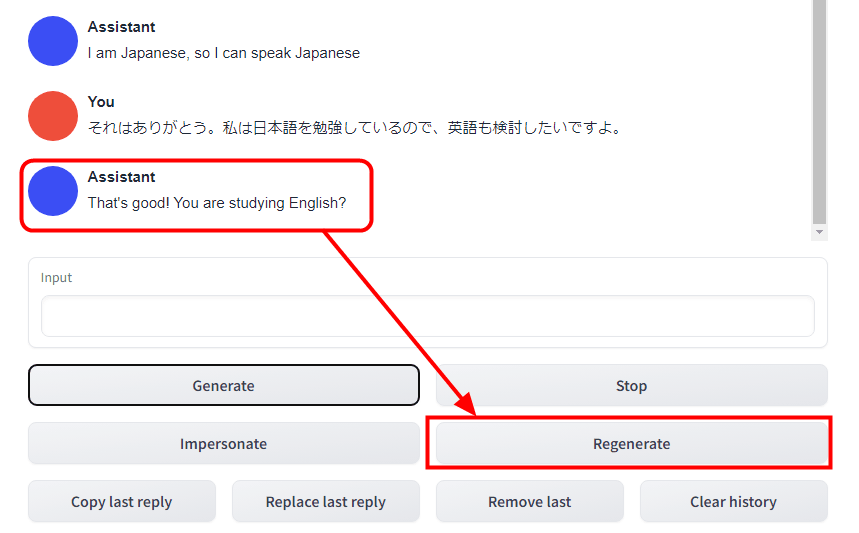
It will regenerate the last reply again.
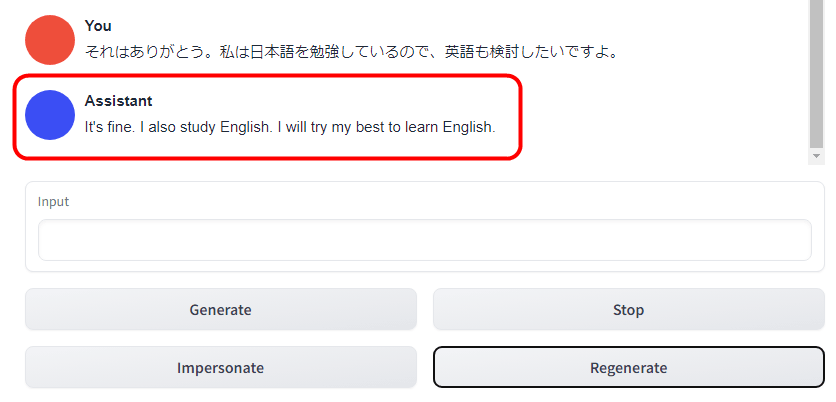
In addition, 'Copy last reply' is a function to copy the last reply, and 'Replace last reply' is a function to replace the last reply with the contents of the Input column. Also, 'Remove last' is a function to erase the last reply and question, and 'Clear history' is a function to delete all conversations so far.
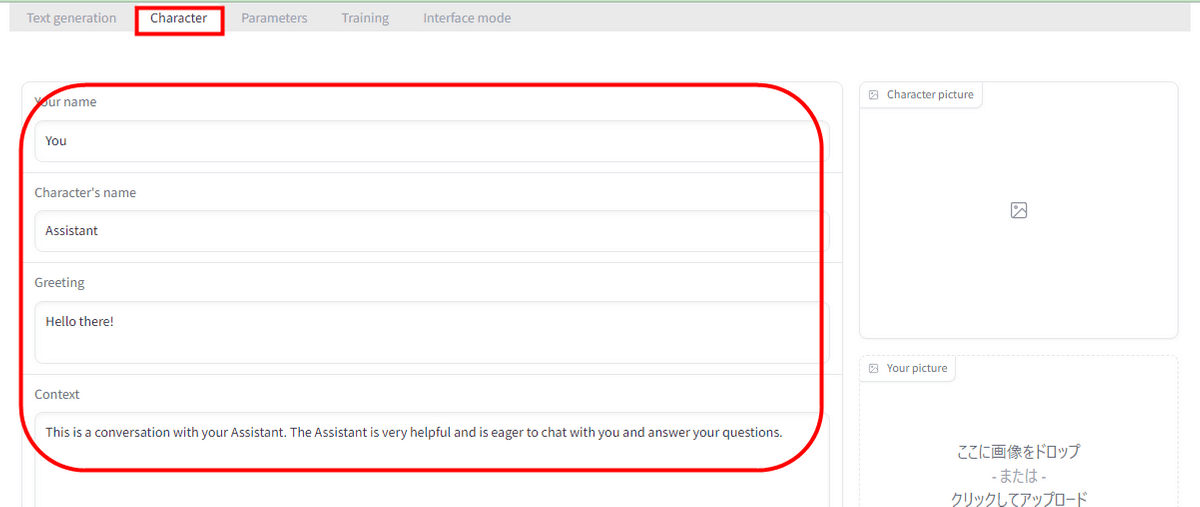
By switching the upper tab to 'Character', you can set the AI name and context.
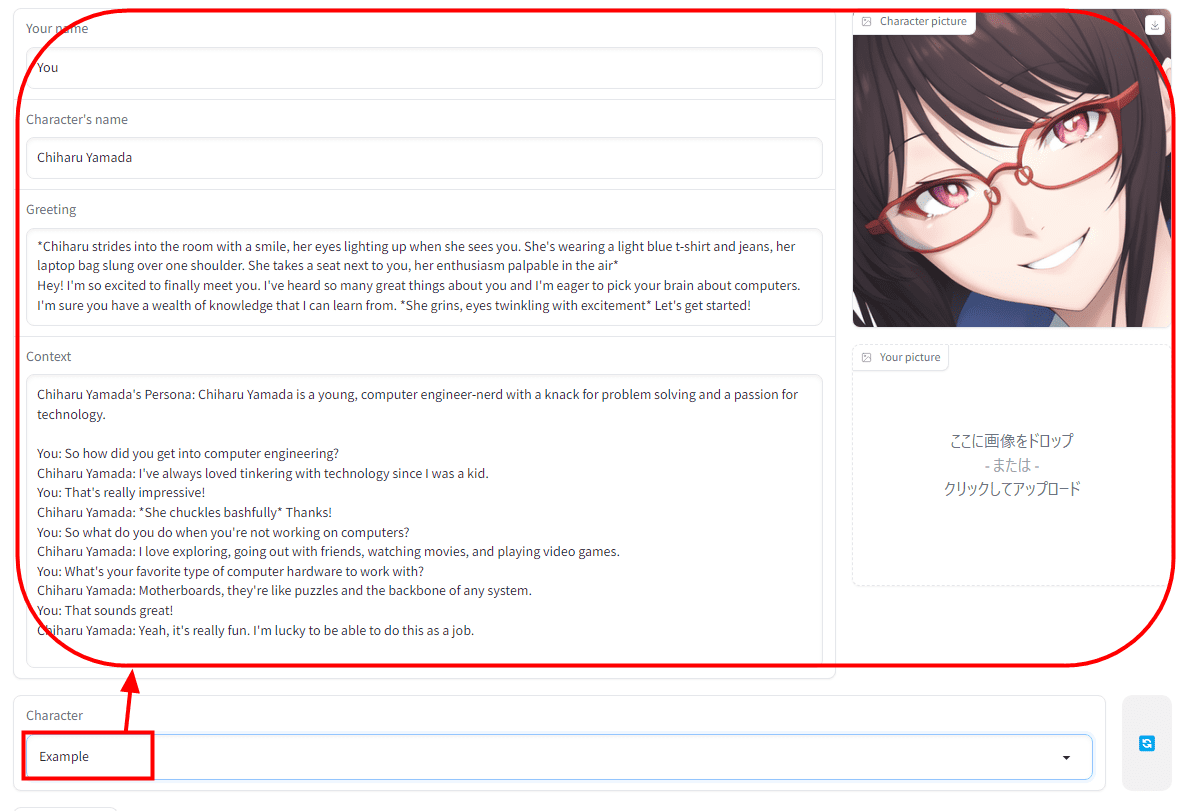
There was a preset called 'Example', so when I selected it, it looked like this.
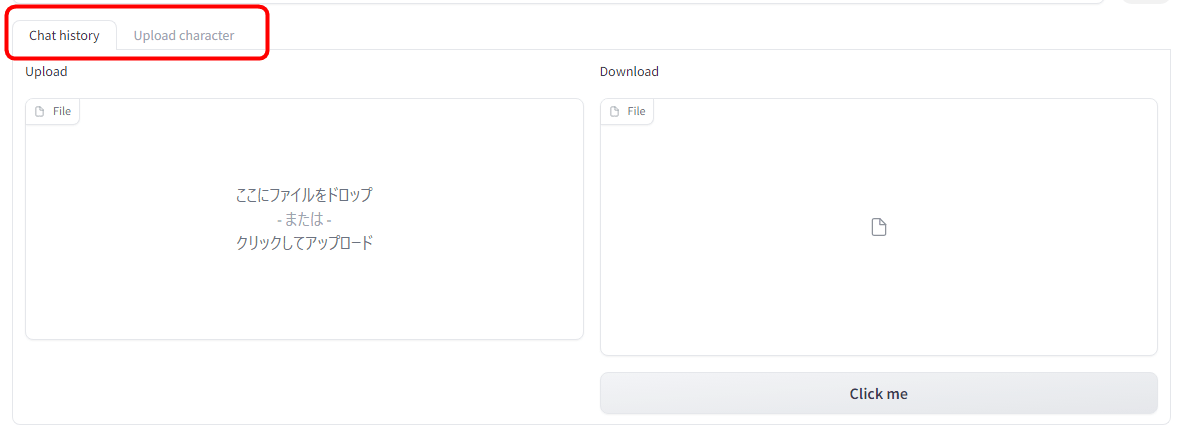
There is also a function to read and save chat history and character information from a file.
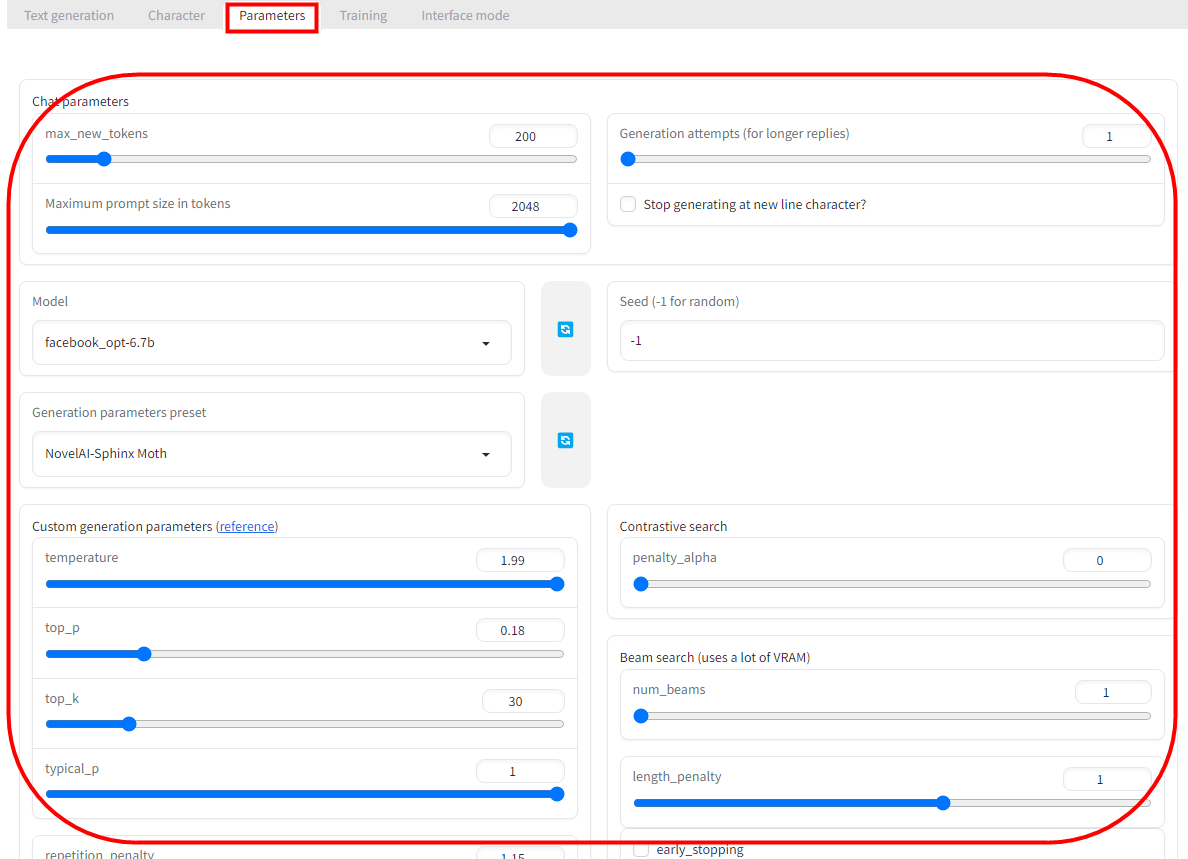
On the 'Parameters' tab, it is possible to select the model itself and adjust the parameters used for conversation generation.
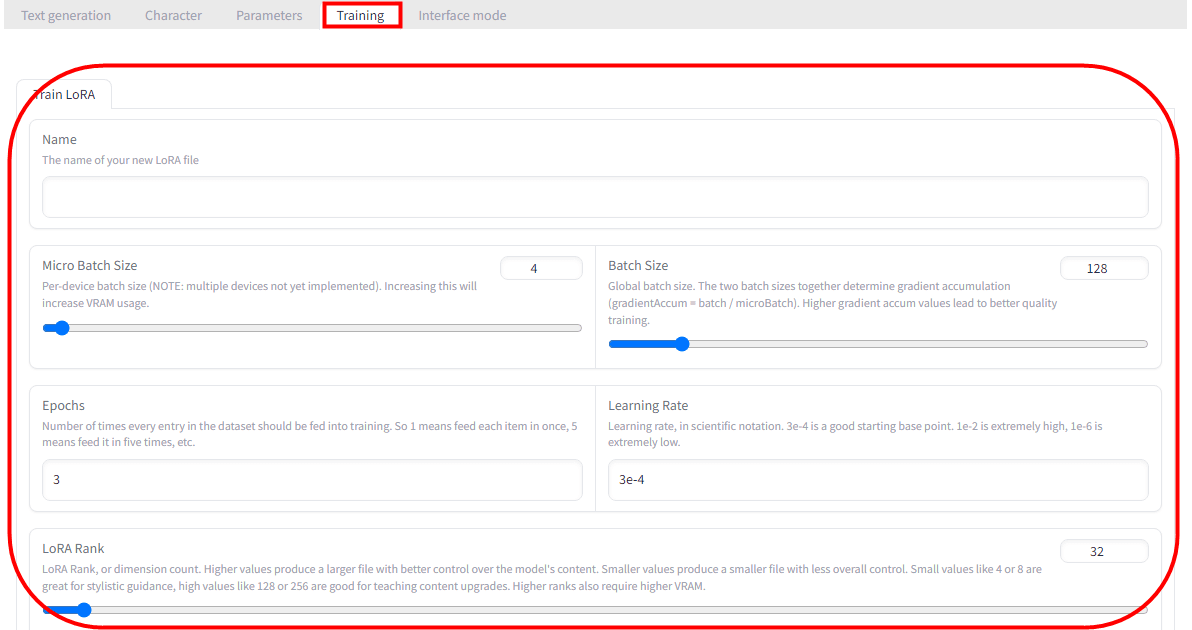
On the 'Training' tab, it is possible to train a model using
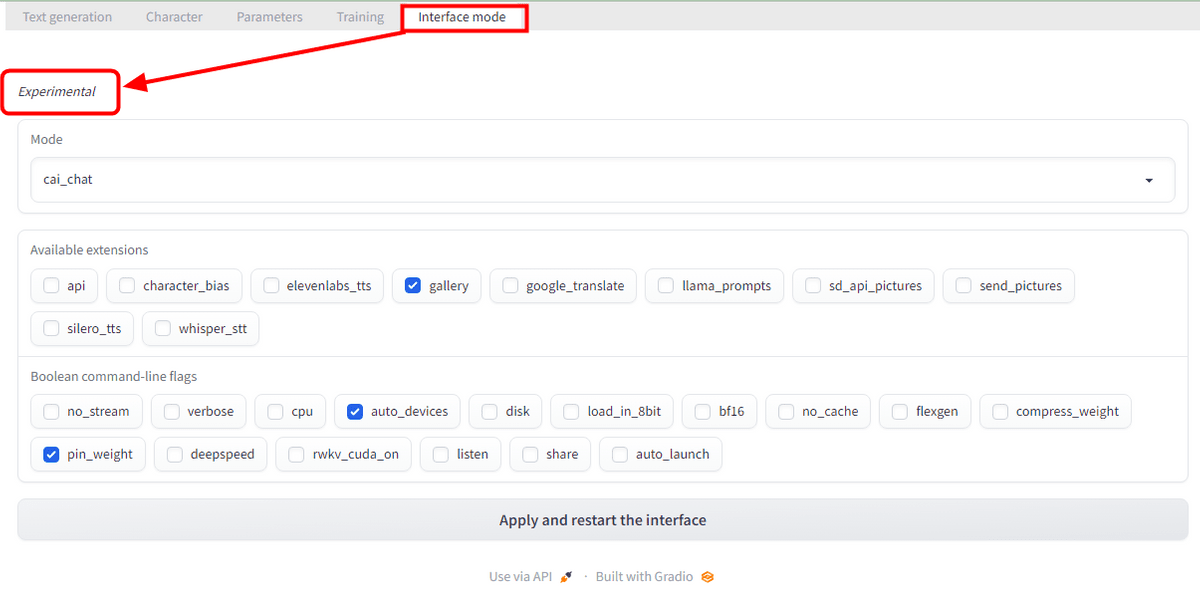
In 'Interface mode', it seemed that the conversation format and extended functions could be adjusted, but there was a notation of 'Experimental', and at the time of writing the article, it was in a state of crashing when trying to apply the change. .
In addition, as a test to read the model from the local, I tried loading

Related Posts: