




画像生成AI「Stable Diffusion」にたった数枚のイラストから絵柄や画風を追加学習できる「Dream Booth」が簡単に使える「Dreambooth Gui」レビュー
画像生成AI「Stable Diffusion」はあらかじめ学習したデータセットを基にして、プロンプトあるいは呪文と呼ばれる入力文字列に沿った画像を自動で生成します。そのStable DiffusionのAIモデルに画像を追加で学習させる「Dream Booth」という手法があるのですが、コマンド入力による操作が必要で、演算処理に何十GBものVRAMを必要としました。しかし、Dream BoothをGUIで、しかもNVIDIA製グラボであれば10GB程度の環境でも使える「Dreambooth Gui」がリリースされたので、実際に使ってみました。
GitHub - smy20011/dreambooth-gui
https://github.com/smy20011/dreambooth-gui
Dreambooth Guiを使うためにはDockerとWSL2のインストールが必要となります。
Dockerのインストーラーは以下のサイトでダウンロードできます。
Docker: Accelerated, Containerized Application Development
https://www.docker.com/
上記サイトの「Download Docker Desktop」をクリックすると、EXE形式のインストーラーがダウンロードできます。ファイルサイズは537MBです。
インストーラーを起動します。「Okをクリックすると、インストールが始まります。
インストールが終わったら表示される「Close and restart」をクリックすると、OSが再起動します。
再起動後、Dockerのデスクトップアプリが起動し、サービス規約への同意が表示されるので「Accept」をクリック。
これでインストールは終了。右上の「×」をクリックしてウィンドウを閉じます。
WSL2のインストールについては、Microsoftが以下にまとめています。
WSL のインストール | Microsoft Learn
https://learn.microsoft.com/ja-jp/windows/wsl/install
次に、Dreambooth Guiのインストーラーをダウンロードします。インストーラーのダウンロードリンクは以下のGitHubページにあります。
Releases · smy20011/dreambooth-gui · GitHub
https://github.com/smy20011/dreambooth-gui/releases
「dreambooth-gui_0.1.7_x64_en-US.msi」をクリックしてダウンロードします。ファイルサイズは3.18MBです。
インストーラーを起動して、「Next」をクリック。

「Next」をクリックします。
「Install」をクリック。
インストールが終わったら、「Launch dreambooth-gui」のチェックを入れて、「Finish」をクリック。
Dreambooth Guiが起動するとこんな感じ。中央に表示されている「Select Training Image Folder」をクリックします。
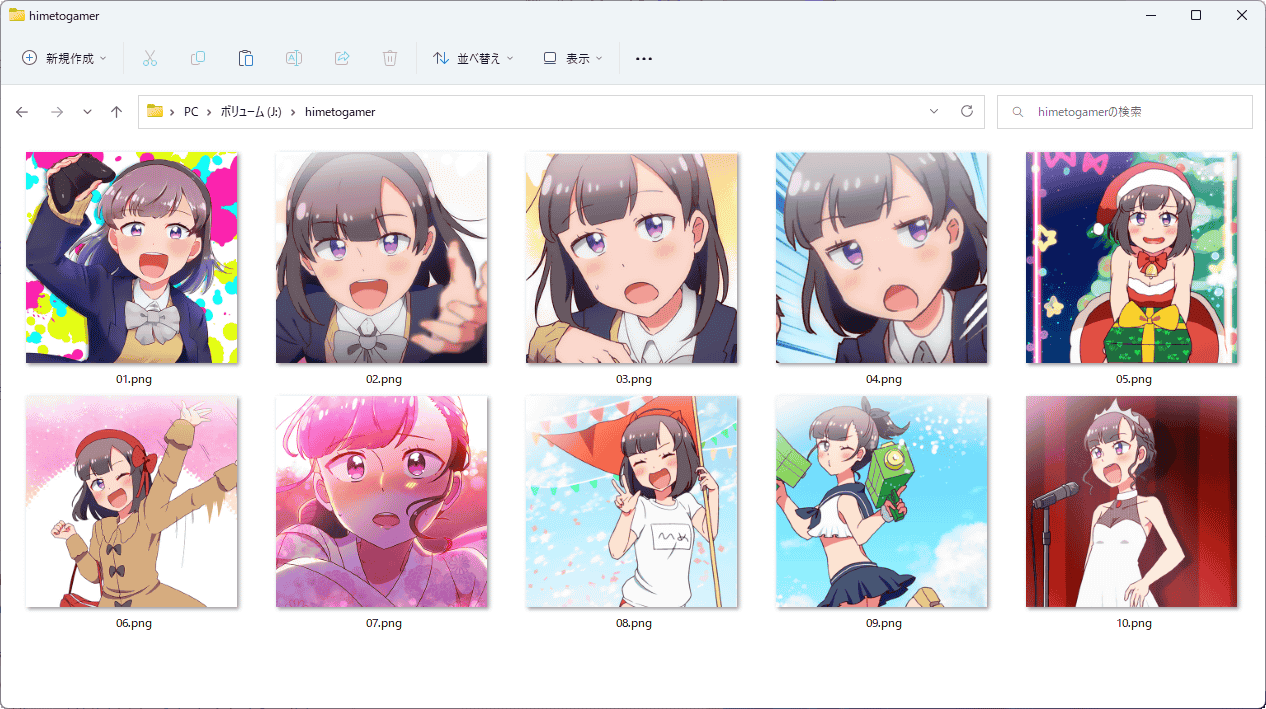
追加学習させたい画像を入れたフォルダを選択します。今回はマンガ「姫とゲーマー」の主人公である姫宮ありかの画像10枚を入れたフォルダを選択しました。
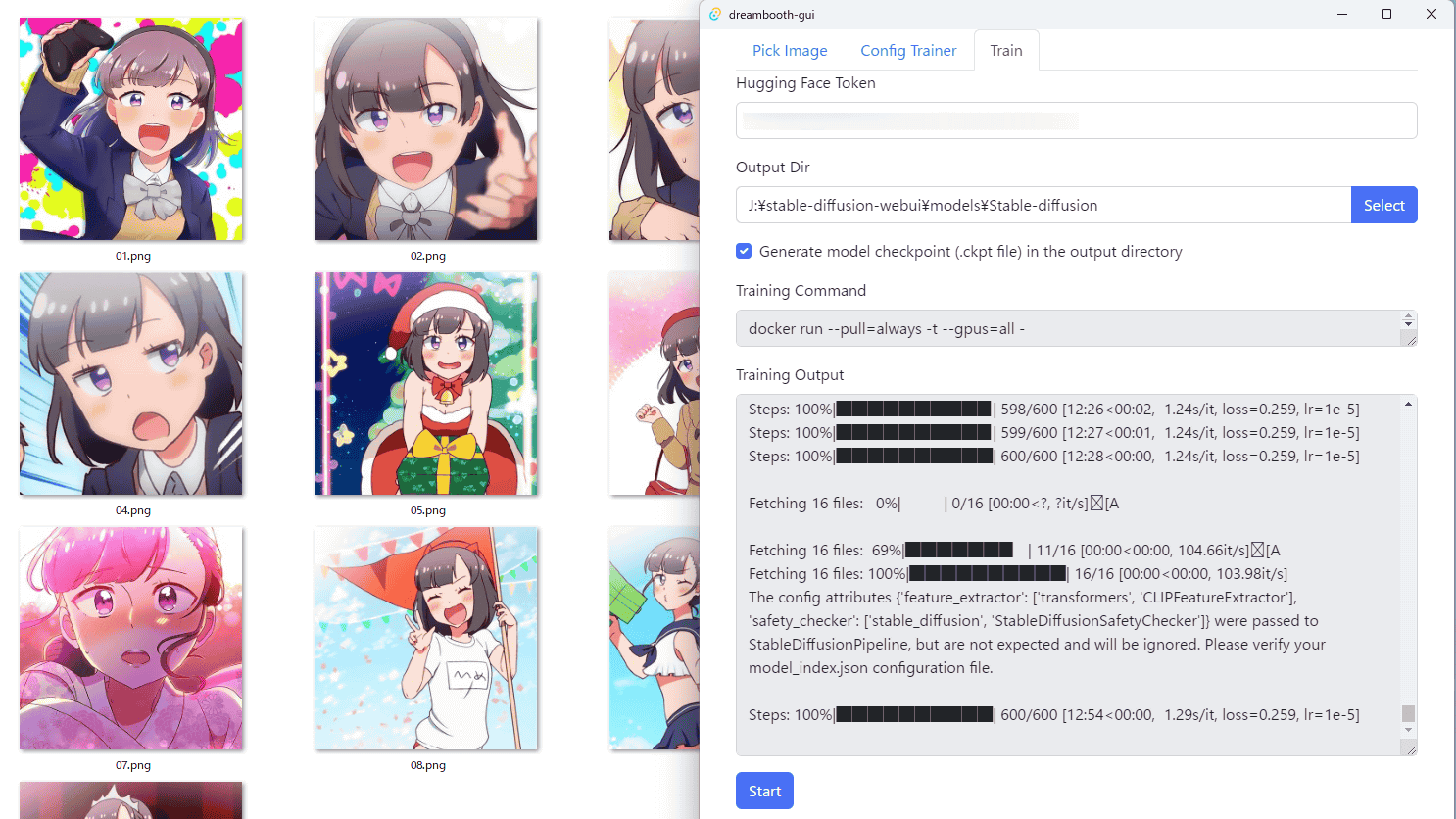
フォルダを選択すると、学習設定の画面に移行します。「Model」は追加学習させるモデルを指定でき、デフォルトではHugging FaceのリポジトリからStable Diffusion v1.4のモデルをダウンロードする設定となっています。「Instance prompt」は、画像生成時に追加学習させたデータを呼び出すためのプロンプト。Class promptでは、追加学習させるデータにクラスを設定するプロンプトになります。Training Stepsは学習のステップ数で、デフォルトは「600」と「1e-5」に設定されています。

学習設定を終えたら、「Train」のタブをクリックします。追加学習させるモデルにHugging Faceのリポジトリを指定した場合は、Hugging Faceのアクセストークンを発行し、「Hugging Face Token」に入力します。「Output Dir」には、追加学習済みのモデルの出力先ディレクトリを入力します。今回はAUTOMATIC1111版Stable Diffusion web UIで読み込ませるため、「stable-diffusion-webui/models/Stable-diffusion」に指定しました。最後に「Start」をクリックすると、モデルの追加学習がスタート。

VRAM12GB搭載のNVIDIA製GPUで、10枚の画像を600回追加学習させると、完了までおよそ1時間10分ほどかかりました。追加学習が終わると「Finished!」と表示されるので、「OK」をクリック。
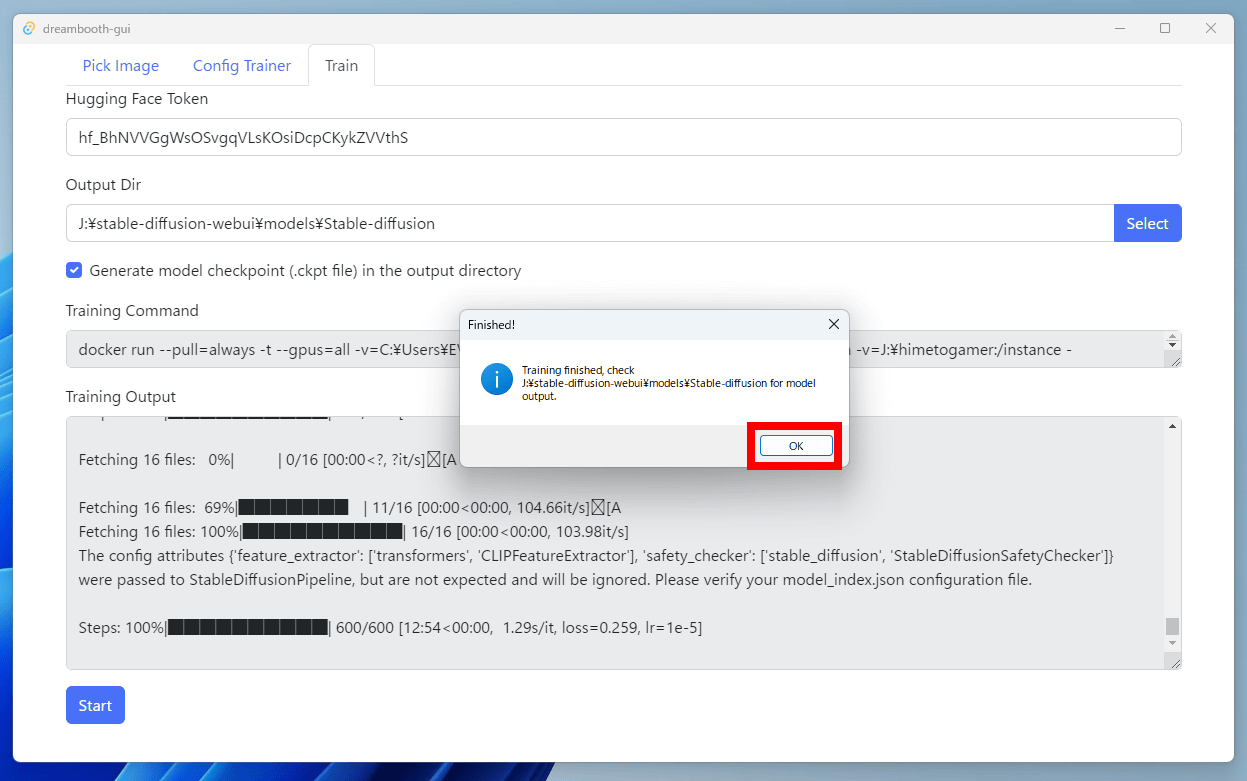
GUIには、追加学習のログが表示されていました。
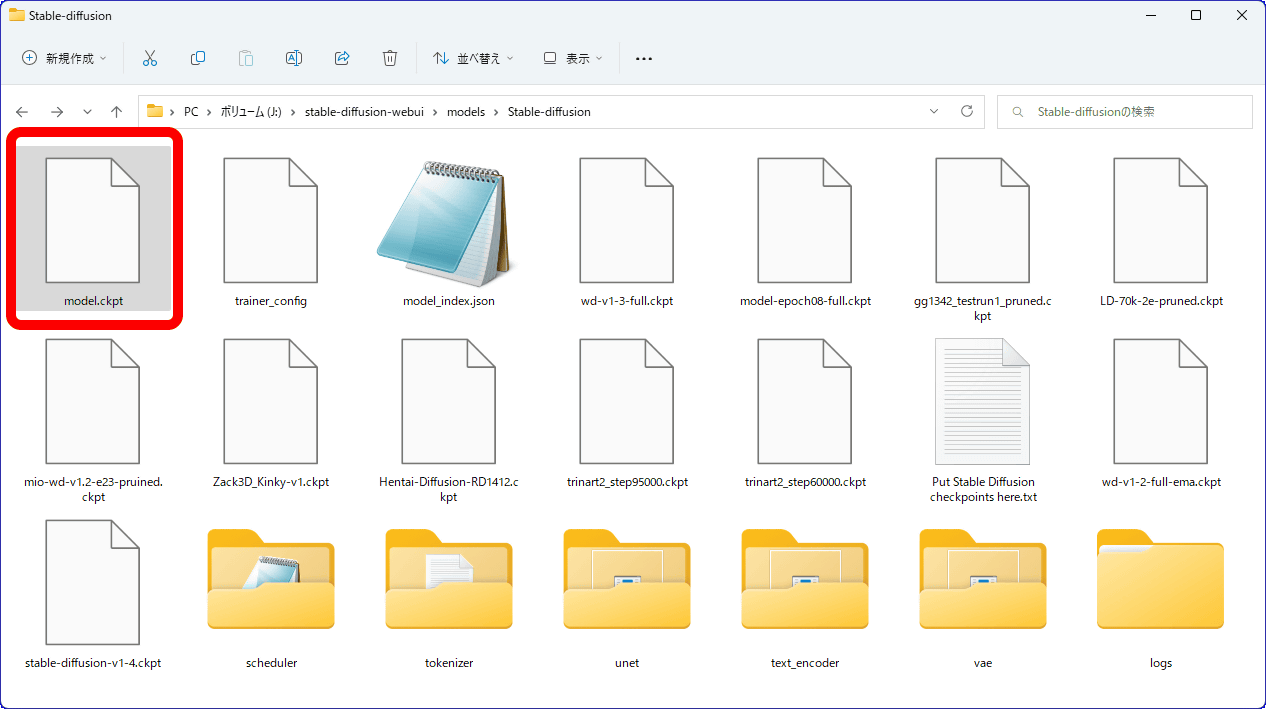
出力先ディレクトリを見ると、「model.ckpt」という形で追加学習済みのモデルが出力されていました。
さっそく、実際にAIにイラストを自動生成してもらいました。プロンプトは「little chinese girl with flowers in hair wearing an white dress, sks himetogamer, highly detailed, anime, manga」、生成ステップ数は30 生成サンプラーはEuler a、CFGスケールは7、シード値は675338939です。プロンプト中の「sks himetogamer」が今回追加学習した要素を指定する部分です。
AUTOMATIC1111版Stable Diffusion web UIを起動します。
まずは、通常のStable Diffusion v1.4で自動生成してみたイラストが以下。中国っぽい髪型と花の髪飾り、白いドレスと指定した通りのイラストとなっています。

次に、追加学習済みのモデルに同じプロンプトと設定で出力してもらいました。AUTOMATIC1111版Stable Diffusion web UIでモデルを切り替えるには、右上の「Stable Diffusion checkpoint」をクリック。
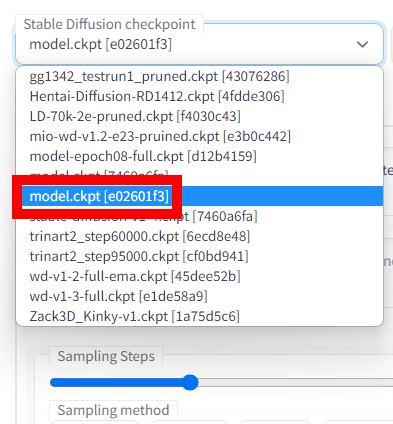
このプルダウンメニューには「stable-diffusion-webui/models/Stable-diffusion」ディレクトリにあるAIモデルが表示されます。今回追加学習したモデル「model.ckpt[e02601f3]」を選択します。
同じプロンプトと設定で、追加学習済みモデルに自動生成してもらったイラストが以下。追加学習した画像はわずか10枚なので、絵柄の再現度はそこまで高くありませんが、髪の色や塗り方、口を開ける表情など、追加学習用のデータを思わせる特徴がはっきりとイラストに出ています。もっと画像の枚数を増やせば、より高い精度で絵柄や画風の再現が期待できます。

・関連記事
超高精度なイラストを生成できると話題の「NovelAI」は本家Stable Diffusionにどんな改善を加えたのか? - GIGAZINE
画像生成AI「Stable Diffusion」AUTOMATIC1111版でイラストの画風・絵柄を学習&適用できる「Aesthetic Gradients」使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」のデイリーアクティブユーザーが1000万人に到達、「DreamStudio」のユーザーは150万人超え - GIGAZINE
NVIDIAのグラボのメモリ容量を無理矢理アップグレードする方法 - GIGAZINE
・関連コンテンツ


in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article ``Dream Booth Gui'' review that ….