




Slackが2020年5月に起こした大規模障害の原因は何だったのか?

ウェブサービスにおいて最も起こってはならないのが「サービスの停止」ですが、GoogleやCloudflareといった大手のインターネット企業でも、時にはそうした障害を引き起こします。2020年5月に発生したSlackのサービス障害について、SlackのエンジニアであるLaura Nolan氏が原因を説明しています。
A Terrible, Horrible, No-Good, Very Bad Day at Slack
https://slack.engineering/a-terrible-horrible-no-good-very-bad-day-at-slack-dfe05b485f82
2020年5月にSlackで発生した障害について、実際にSlackユーザーに影響を及ぼし始めたのは太平洋標準時の5月12日16時45分からですが、それよりも前の8時30分から障害は始まっていたとのこと。ネットワークのトラフィックを監視するトラフィックチームが一部のAPIリクエストに失敗しているというアラートを受けると同時に、データベースの信頼性向上を目指すDBREチームがデータベース基盤の負荷が大幅に増加しているというアラートを受けました。データベースの負荷上昇は設定の変更によるものだったので、すぐさま設定をロールバックして障害を解決。この時点では、ユーザーにほとんど影響はなかったとNolan氏は語っています。

Slackは新型コロナウイルスに起因するロックダウンや自宅待機によるユーザー増加に対応するため、ウェブアプリ層のクラウドインスタンスを大幅に増やしていたとのこと。クラスタ内のワーカーの処理能力を使い切ってしまった場合はすぐにオートスケールするようになっていますが、今回はワーカーが一部のデータベースリクエストの完了を待機していたため、利用率が増加してオートスケールが作動した結果、インスタンス数が75%も増加。これが8時30分に発生したアラートの原因で、Slack史上最高数のウェブアプリ層上でホストとして動作するインスタンスを停止させたとのこと。
最初の障害に対処して8時間後、通常よりもSlackが返すHTTPの503エラーが増加しているというアラートが発生。オンコールのエンジニアが手動でウェブアプリ層をスケールアップしたものの、障害解決には至らず。ウェブアプリ層の一部のみが高負荷になっていることに気付き、ウェブアプリのパフォーマンスとロードバランサー層の両方を調査した結果、原因を特定したとNolan氏は説明しています。
SlackではL4ロードバランサーの背後に、ウェブアプリ層にリクエストを振り分けるHAProxyインスタンスを複数設置しているとのこと。サービスディスカバリとしてConsulとConsul Templateを使用し、ウェブアプリ層の死活監視を行ってHAProxyがリクエストを振り分けることができるインスタンスをリスト化していました。
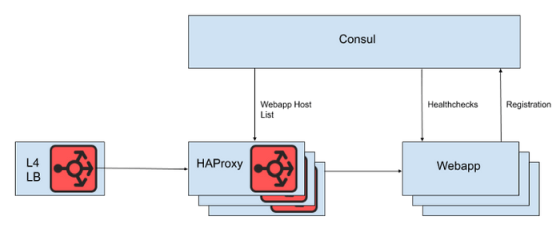
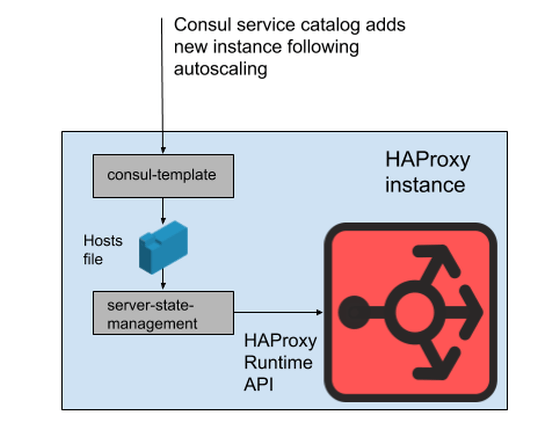
動作しているインスタンスのリストはHAProxyの設定ファイルに直接反映させるのではなく、HAProxy Runtime APIを利用して、Consulの作成したリストをSlack独自プログラムの「server-state-management」が読み込み、HAProxyインスタンスを間接的に操作していたとのこと。APIの利用により、HAProxyプロセスを再起動させることなく設定を反映することが可能な構成になっています。
SlackのHAProxyでは、サーバーテンプレートでウェブアプリのバックエンドが占有できる「スロット」が定義されています。HAProxyのインスタンス数をM、スロット数をNとすると、合計でM×N個のウェブアプリ層インスタンスへリクエストを中継できることになりますが、8時30分の障害におけるインスタンスの急増後、M×N個以上のインスタンスが起動していた状態だったとNolan氏。HAProxyが持つスロットが足りなくなっているため、リクエストが中継できないインスタンスが発生します。
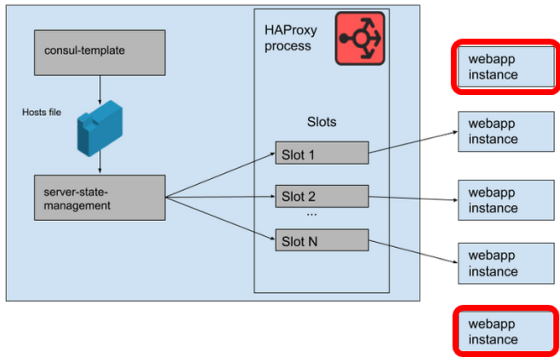
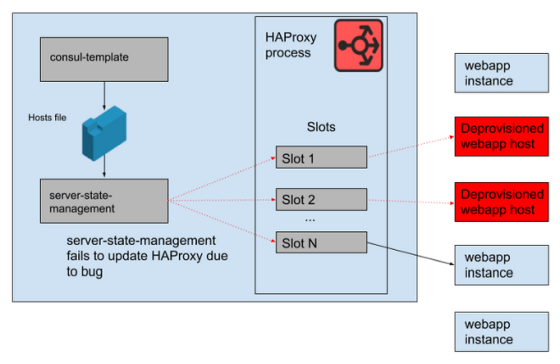
server-state-managementは起動していないインスタンスが保持しているHAProxy内のスロットを解放する前に、新しいインスタンスに割り当てるスロットを検索するようにプログラムされていたため、HAProxyの持つスロットが足りなくなった場合は、新しいインスタンスにスロットを割り当てることができません。つまり、server-state-managementにはHAProxyのスロットが不足していた場合は、利用可能なホストのリストをHAProxyに反映することができないというバグがあったというわけです。
こうして16時45分、HAProxyは古いホスト情報をもとに既に停止しているインスタンスにリクエストを流すようになり、ユーザーがSlackを利用できない障害が発生。トラフィックの低下にあわせてウェブアプリ層のスケールダウンを行う時間帯と障害が重なり、営業日の終わりにサービス停止が発生してしまったとNolan氏は語っています。
最終的に障害はHAProxyの再起動によって解決。アラートが機能しなかった原因についてNolan氏は「壊れた監視システムは長い間『ただ動いていた』だけで、変更を加える必要がなかったこともあり、壊れていることに誰も気づかなかった」と指摘。HAProxyのデプロイも比較的静的なものであるため、監視システムとアラートを気にかけるエンジニアが少なかったと語っています。
記事作成時点において、SlackはHAProxyからEnvoy ProxyとxDSによる環境に移行中であるとのこと。Nolan氏はSlackの高い可用性と信頼性を保つよう努力していますが、今回のケースでは失敗したとし、障害で学んだことを今後のシステムとプロセスの改善に生かしていくと語っています。
・関連記事
Gmail・Googleドライブ・Googleフォトが一時使用不能になった件についてGoogleが詳細な原因を説明 - GIGAZINE
AppleのiCloudで大規模なシステム障害が発生、GoogleやFacebookに引き続き - GIGAZINE
Googleの徹底的なシステム障害への対応「SRE」の中身とは? - GIGAZINE
Slackはスピードと信頼性を両立したソフトウェア開発をどのように実現しているのか? - GIGAZINE
・関連コンテンツ







in ソフトウェア, ネットサービス, Posted by darkhorse_log
You can read the machine translated English article What caused Slack's massive outage i….