




月間アクティブユーザー1億人超の「Roblox」が4日間におよぶ障害を発生させた原因をレポート

ゲームを作成したり、他人が作成したゲームをプレイしたりできるオンラインゲーミングプラットフォームの「Roblox」は、2021年の10月28日から31日までの4日間、障害によってサービスがダウンしていました。いったい何が原因でどのように復旧したのかについて、Robloxが公式ブログにてレポートにまとめています。
Roblox Return to Service 10/28-10/31 2021 - Roblox Blog
https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021/
どんな障害だったのかを簡単にまとめると下記の通りとのこと。
・サービス停止時間は73時間
・根本的な原因は2つ
1:Consulの新たな機能を高負荷環境下で有効にしたことでパフォーマンスが悪化
2:特定の負荷状況によってBoltDBのパフォーマンスが劇的に悪化
・サービス停止が長期におよんだ理由は別の原因を調査していて根本的な原因にたどり着くのが遅れたため
・停止の原因をよりよく把握できる重要な監視システムがサービス停止の影響を受けてしまった
・さらにサービスが完全に停止した状態から立ち上げるのにも時間がかかった
Robloxのサービスは独自のハードウェアに独自のシステムが構築されているRobloxデータセンターで実行されており、サーバーの台数は1万8000台以上、コンテナ数は17万にも及びます。この規模のシステムを管理するためにRobloxではHashiCorpの「Nomad」「Consul」「Vault」という3つのサービスを組み合わせた「HashiStack」を利用しているとのこと。
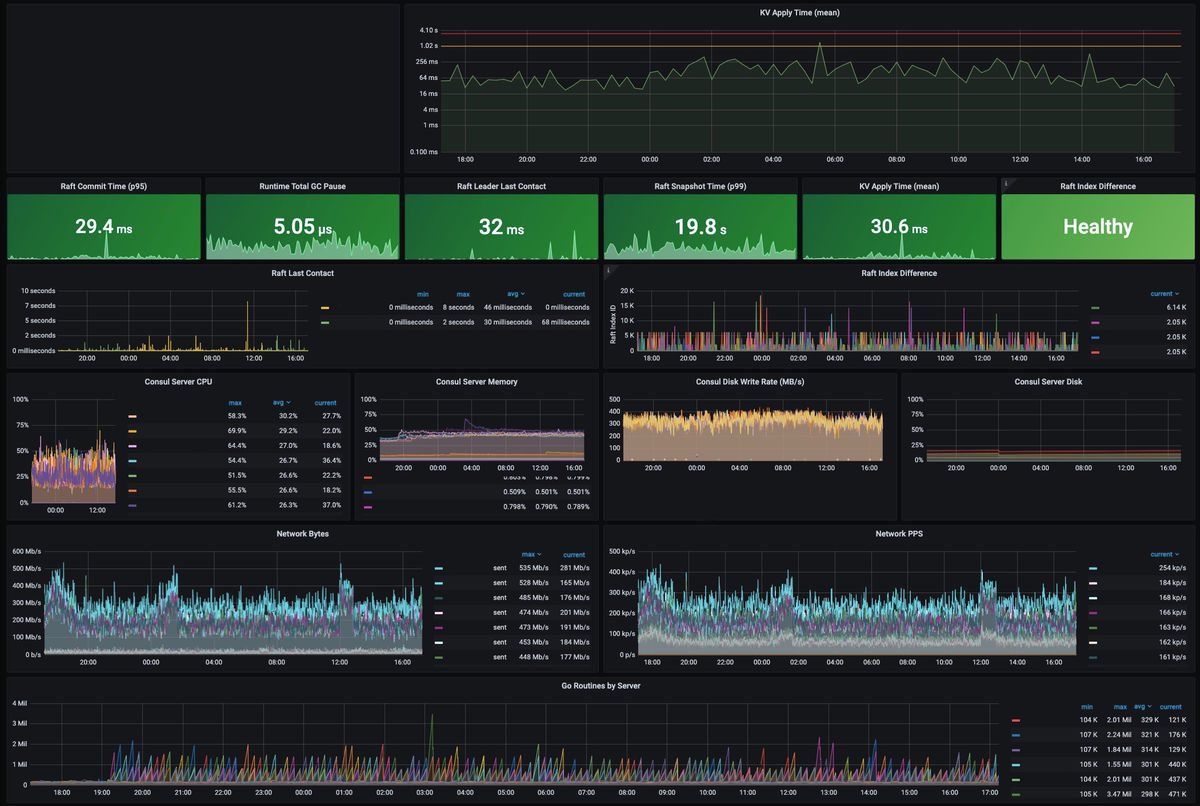
Nomadはどのコンテナをどのノードのどのポートで実行するかを決めるスケジューリング担当のツールで、Consulはサービスディスカバリやヘルスチェック、セッションロック、KVストアなどの用途で利用されるツールです。Consulは10台のマシンから成り立っており、そのうち5台は読み取り専用のリードレプリカで、残りの5台のうち1台がRaftアルゴリズムによってリーダーに選出され、同期を管理しています。Consulの通常時のダッシュボードはこんな感じ。
Robloxは大規模障害が発生するまでの数か月の間に、Consulをアップグレードして新たにCPUとネットワークの帯域幅を大きく削減できるストリーミング機能を追加したとのこと。そして10月28日の午後に、機密データを保存するサービスであるVaultのCPU負荷が高まり、エンジニアによる調査が始まりました。
最初の調査では、通常300ミリ秒未満であるべきConsulのKVストアへの書き込みレイテンシが2秒まで伸びていることが発見されました。Robloxの規模だとハードウェアの障害は珍しくないため、エンジニアチームはConsulのクラスターノードを交換して対応しましたが、パフォーマンスの低下が止まらず、16時35分にはプレイヤー数が通常時に比べて半減し、最終的にはシステムが完全に停止してしまいます。
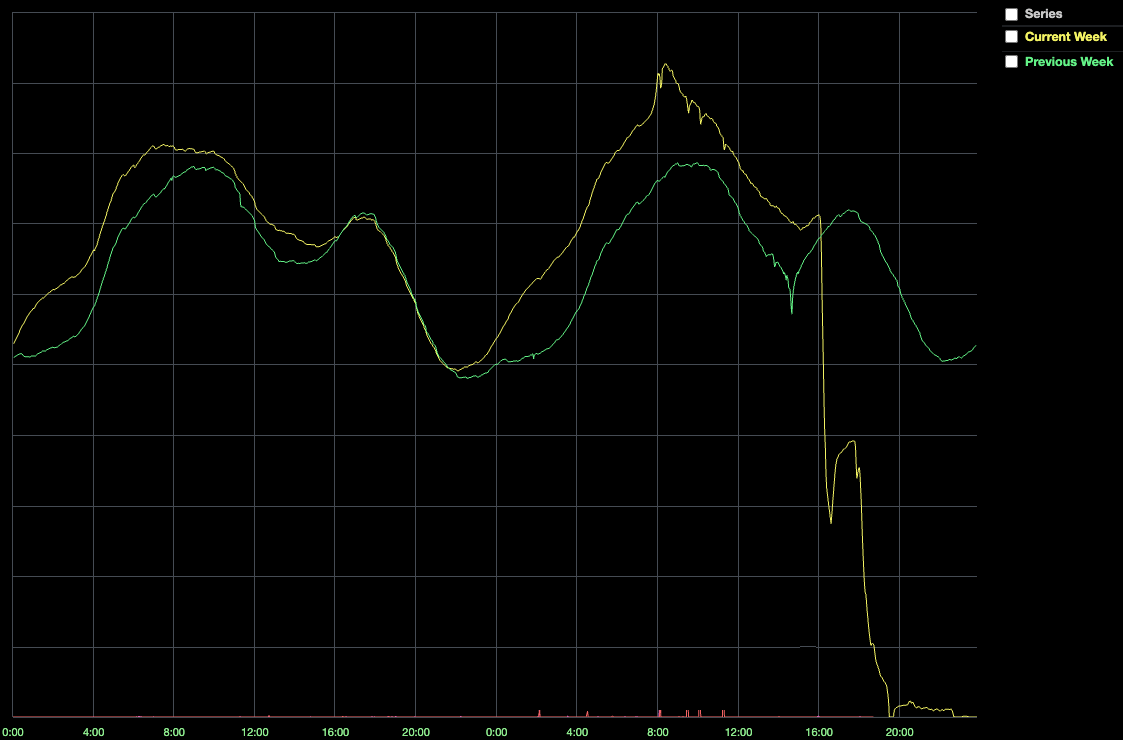
Robloxのシステムではサービスが別のサービスと通信したい場合、どこに接続すれば良いのかをConsulに聞く必要があるため、Consulが単一障害点となってしまっていました。エンジニアチームはサービスが完全に停止してしまうという事態を重く受け止め、Consulクラスターの全ノードをより強力なマシンに置き換えましたが、事態は改善しませんでした。
次にチームはConsulクラスターを停止前のスナップショットにロールバックすることを決定しました。システムの構成データが少し失われるものの、ユーザーデータは無事で、失った構成データは手動で復元できるため問題ないと判断したとのこと。リセットした直後は問題なく動作しましたが、Consulのパフォーマンスは再び低下を始め、2時間後には元の状態に戻ってしまいました。この時点で障害発生から14時間が経過していましたが、判明したのはConsulに何かが負荷を与えているということだけでした。
障害の根本原因を探るため、エンジニアチームはできる限り規模を小さくしてシステムを再構成してみたとのこと。通常時は数百インスタンスで実行されているRobloxサービスを1桁に縮小し、必須ではない要素を全て無効にしてシステムを立ち上げました。変更内容が多種多様だったため、この作業は数時間かかり、障害発生から24時間経過後の10月29日16時にシステムを再度起動。しかし、10月30日の午前2時ごろ、再びConsulのパフォーマンスが低下してしまいます。この事態を経て、チームは「何かがConsulに負荷を与えている」のではなく、Consulそのものに原因があることを疑い始めました。
デバッグログとOSの指標を調べると、ConsulのKVストアで競合が発生しており、書き込みが長時間ブロックされていることが示されていました。この競合について調べていくと、数か月前に導入されていたConsulのストリーミング機能が原因だという証拠が登場。すべてのConsulシステムのストリーミング機能を無効にしてみると、ConsulのKVストアへの書き込みレイテンシが一気に低下したとのこと。
障害発生から54時間後、システムが安定したためエンジニアチームはサービスの復帰へと集中できるようになりました。Robloxはバックエンドに一般的なマイクロサービスのパターンを採用しており、最下層にデータベースとキャッシュが存在しています。データベースは障害の影響を受けなかったものの、キャッシュシステムには問題が発生していたとのこと。しかしキャッシュなので、エンジニアチームは再度デプロイすることで正常な状態に戻すことを決定しました。
しかし、キャッシュのシステムが「一からキャッシュを展開する」ことではなく「既に大規模なトラフィックを処理しているシステムに段階的に投入する」ことに重きを置いた構築だったため、キャッシュの展開にかなりの時間を取られたとのこと。障害発生から61時間後にConsulクラスターとキャッシュシステムが正常になり、その他のシステム全体の復帰作業へと移行しました。
いきなり大量のトラフィックを処理することでシステムが不安定になってしまうことを避けるため、DNSステアリングを利用してユーザー数を調整し、一日かけて段階的に復帰作業を進めたとのこと。ユーザー全員がサービスにアクセスできるようになったのは障害発生から73時間後でした。
システムが正常化された後も、RobloxとHashiCorpのエンジニアチームは根本的な原因究明と再発防止のための改善を続けたとのこと。Consulのストリーミングプロトコルが修正されたほか、重要な改善策として次のことが述べられています。
・Consulを監視するためのツールがConsulに依存する「循環依存」を排除
Consulを監視するツールがConsulに依存していたため、Consulの障害発生時には原因究明のためのデータが不足してしまっていました。
・バックエンドサービスの冗長化
Consulクラスター1個ですべてのRobloxバックエンドサービスを実行していたため、今回のような長期的な障害が発生してしまいました。これを避けるために別のデータセンターやアベイラビリティーゾーンへの拡張が行われているとのこと。
・Consulの負荷低減
重要なサービスを別の専用クラスターに分割することで、中央のConsulクラスターへの負荷を低減したとのこと。また、廃止されたKVストアが大量に残っていたのを削除することでもパフォーマンスを向上できたとのことです。
・システムの立ち上げ手順の改善
キャッシュの展開やウォーミングアップなどの要因で、Robloxのサービスを提供するのが遅くなってしまったとのこと。こうした立ち上げプロセスを自動化する取り組みを実行していると述べられています。
・関連記事
任天堂やNetflixに影響を与えたAWSの大規模障害について公式が説明 - GIGAZINE
年初早々発生したSlackの大規模障害は「仕事始め」が原因だった - GIGAZINE
なぜFacebookが6時間もダウンしたのかをFacebook幹部が専門家でなくても分かるように説明 - GIGAZINE
Facebook・Instagram・Oculus・WhatsAppが世界的にダウン、その原因とは? - GIGAZINE
Googleのサービスが45分間にわたり利用できなくなる大規模障害が発生、原因は認証サービスのストレージ問題 - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Report on why Roblox, with more than 100….