任天堂やNetflixに影響を与えたAWSの大規模障害について公式が説明

現地時間の2021年12月7日、Amazonが提供するクラウドコンピューティングサービスであるAWS(Amazon Web Services)で大規模障害が発生し、動画配信サービスのAmazon Prime Video・Netflix・Disney+や暗号資産取引所のCoinbase、コミュニケーションツールのSlack、株取引アプリのRobinhood、任天堂のネットワークサービスなどが影響を受けました。この障害が発生した経緯やオペレーターの対応について、AWSが公式ウェブサイト上で説明しています。
Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region
https://aws.amazon.com/message/12721/
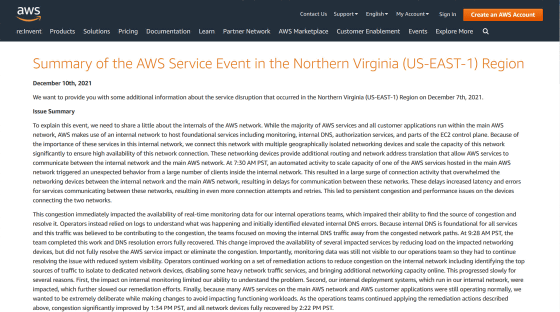
AWSの大規模障害は現地時間の2021年12月7日(日本時間の12月8日)、バージニア州北部地域で発生しました。この障害によってAWSを利用する外部サービスがさまざまな影響を受けたほか、Amazonの社内ツールや倉庫でも問題が発生したことが報じられています。
AWSで大規模障害が発生しAmazonの荷物配達にも影響 - GIGAZINE

AWSのネットワークは、大半のAWSサービスや全ての顧客アプリケーションを提供するメインのAWSネットワークと、システムのモニタリング・内部DNS・認証サービスなどをホストする内部ネットワークに分けられており、これら2つのネットワークが通信してAWSを構成しています。
12月7日7時30分(太平洋標準時/PST)、メインのAWSネットワークがホストするAWSサービスの容量を拡張する自動化されたアクティビティにより、内部ネットワーク内の多数のクライアントにおいて予期しない動作が発生したとのこと。これによって内部ネットワークとメインネットワーク間の接続アクティビティが急増し、ネットワーキングデバイスが圧倒されて通信遅延が発生。サービスの遅延とエラーが増加し、さらに接続の試行および再試行が繰り返されることにより、2つのネットワークを接続するデバイスで永続的な混雑とパフォーマンスの問題が発生したとAWSは説明しています。
AWSのオペレーターは問題の解決に乗り出しましたが、この問題が内部運用チームによるリアルタイム監視データの可用性にも影響を与えたため、オペレーターはログを頼りに問題を特定・解決せざるを得ませんでした。オペレーターは混雑の原因となった内部DNSエラーを特定し、9時28分にエラーを解決したそうですが、これだけではAWSへの影響を完全に解消することはできなかったとのこと。
その後もオペレーターは、専用ネットワークデバイスに分離するトラフィックの上位ソース特定、一部のネットワークトラフィックサービスの無効化、ネットワーク容量の追加といった修復作業に取り組みました。しかし、依然としてリアルタイム監視データが得られないままであり、内部ネットワークで展開する社内システムも影響を受けていたことに加え、正常に動作しているAWSサービスが影響を受けないように慎重に作業したことから、一連の問題を解決するには時間がかかったそうです。
結局、オペレーターによってネットワークの混雑が大幅に解消されたのは13時34分のことであり、全てのネットワークデバイスが回復したのは14時22分でした。今回の大規模障害は多くのAWSサービスに影響を及ぼし、AWSコンソールへのログインエラーが完全に回復したのは14時22分、認証に使用されるAmazon Secure Token Service(STS)の完全回復は16時28分、API管理サービスを呼び出すために使われるAPI Gatewayが大部分で回復したのは16時37分、コンテナを実行するAWS Fargateのエラー率が正常に戻ったのは17時、コンタクトセンターサービスのAmazon Connectが通常の操作に戻ったのは16時41分だったとAWSは述べています。

AWSは今回の大規模障害を受けて、原因となったAWSサービスの容量を拡張する自動化されたアクティビティを無効化し、全ての修復を展開するまで再開しないとしています。また、今回の障害ではこれまで観察されていなかった動作が発生したため、システム回復のために設計されたバックオフ動作がうまくいかなかったとのことで、今後2週間にわたってこの問題に対する修正プログラムを展開するとのこと。さらに、同様のイベントが再発したとしても、影響を受けるネットワークデバイスを保護する追加のネットワーク構成も導入したと説明しています。
今回の大規模障害においては、リアルタイム監視システムが影響を受けたために障害についての理解が遅れた上に、ネットワークの混雑によってカスタマー用のサービスヘルスダッシュボードが待機状態となってしまいました。AWSは、「このような障害は何が起こっているのかについての情報が入手できない場合、より影響が大きく、イライラすることを理解しています」と述べており、この点を改善した新しいバージョンのサービスヘルスダッシュボードを2022年初頭にリリースする予定だと述べました。
・関連記事
AWSで大規模障害が発生しAmazonの荷物配達にも影響 - GIGAZINE
AWSで大規模な障害が発生中、多数のサービスがあおりを受ける事態に - GIGAZINE
年初早々発生したSlackの大規模障害は「仕事始め」が原因だった - GIGAZINE
「FF14 暁月のフィナーレ」のログインエラーは世界的な半導体不足により十分なサーバーが調達できなかったため - GIGAZINE
なぜ複雑なシステムでは障害が発生しやすいのか - GIGAZINE
Microsoftのシステム障害で「Skype」や「Xbox Live」などのサービスが約4時間にわたり停止 - GIGAZINE
Facebook・Instagram・Oculus・WhatsAppが世界的にダウン、その原因とは? - GIGAZINE
・関連コンテンツ