




「日本語のくずし字をAIで活字に直す試み」の活発化に海外の研究者らも注目

by Peter Roan
日本の古典籍や古文書で用いられている「くずし字」を現代日本語の文字に変換する作業を「翻刻」と呼びます。多くの現代日本人はくずし字を読むことができないので、変換は誰にでもできるものではありません。そこで注目が集まっているのが、機械学習を利用して翻刻する試みです。モントリオール大学の博士課程で機械学習の研究を行うアレックス・ラム氏が、くずし字の活字化を取り巻く事情をまとめています。
How Machine Learning Can Help Unlock the World of Ancient Japan
https://thegradient.pub/machine-learning-ancient-japan/
過去の人々が残した膨大な書物や文書は、歴史や文化を考える上で非常に重要な資料となります。しかし、言語や記法は時間と共に変化していくものであり、古い文書の多くは一部の専門家以外には理解できない状態になっています。たとえば古代メソポタミア周辺で文字を記すために用いられた粘土板には、主に楔形文字によって文字が刻まれていますが、これを解読できるのは特別な訓練を受けた一部の研究者だけです。
これと同様のことが、日本のくずし字においても起こっているとラム氏は指摘。くずし字はおおむね9世紀から明治ごろまで使用されてきましたが、現代の教育課程には含まれず、日本人の圧倒的多数はくずし字を読めません。その一方で、くずし字によって記された書物の量は膨大であり、手紙や個人の日記まで含めると、実に10億ページを超える文章が存在すると推定されています。
くずし字を理解できる人がほとんどいないため、くずし字で記された膨大な情報を読み解くには非常に長い時間と多くの資金が必要となります。日本文化におけるくずし字の重要性を考えると、くずし字を認識するためにコンピューターを利用することは重要だとのこと。
by Stuart Rankin
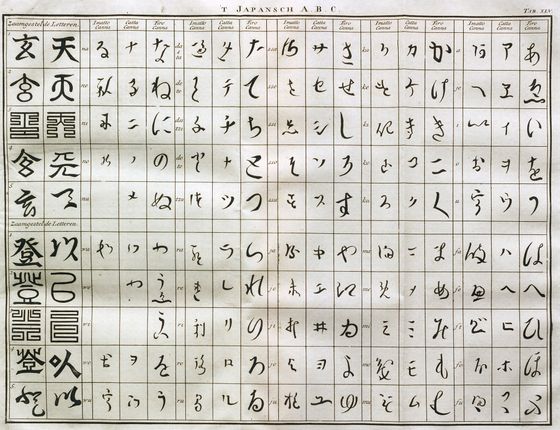
以前から機械学習を用いたくずし字認識AIの開発は模索されていましたが、高クオリティのくずし字データベースが不足しているといった問題から、なかなか高いパフォーマンスが達成できませんでした。そこで、国文学研究資料館は人文学オープンデータ共同利用センターによって精選されたくずし字データセットを作成し、2016年11月に公開。データセットは更新を重ね、2019年11月11日のアップデート時点で4328の文字種と100万点を超える文字画像が用意されています。
包括的な高品質データセットの提供は、くずし字認識AIの開発に大きく寄与しました。それでもなお、ラム氏はコンピューターによるくずし字の認識が困難なものであると指摘。「一部の文字は文脈に依存した方法で記述されているケースもある」「文字の種類が4000種類を超えるため、データセットの中で数回または1回しか登場しない文字も多数ある」「現代では1つのひらがなで表される文字でも、変体仮名によって複数の文字タイプを持つ」といった問題や……

「くずし字のテキストは時にイラストや背景と共に書かれており、テキストとイラストを区別しにくい場合もある」「個人の手紙や句などでは、散らし書きといった行や文字の大きさを統一しないで書く記法も存在しており、必ずしも『右から左に読む』といった順序が定まらない場合もある」などの問題が、くずし字認識AIの開発に立ちはだかっているそうです。

そんな中、ラム氏は人文学オープンデータ共同利用センターの研究者であるTarin Clanuwat氏や北本朝展氏らと共同で、KuroNetというくずし字認識モデルを開発しました。KuroNetは文字の依存関係をとらえ、テキストのページ全体を一緒に処理するというアイデアに基づいています。
KuroNetは1ページあたりなんと1.2秒ものスピードで全体を活字に直すことができるそうで、特に17世紀~19世紀の活版印刷書籍において高いパフォーマンスを発揮するとのこと。もっとも、書籍間でパフォーマンスには大きな差が存在するそうで、多くの特殊な文字を含む辞書や、イラストが多くレイアウトも特殊な料理本においては、パフォーマンスが特に低いという結果になりました。
KuroNetでは、以下のようにくずし字をそれぞれ現代の活字に直すことが可能となります。なお、あくまでも記事作成時点ではくずし字を現代の活字に直すだけであり、現代語に翻訳する作業は人間が行う必要があります。

KuroNetは開発された時点で最先端の結果を達成しましたが、くずし字を活字化するAI開発の分野をさらに刺激するため、Kaggleというプラットフォームにおいて、「数千枚の画像に書かれたくずし字をどれだけ正確に認識できるか」を競うコンペも開催されました。最終的に293チームが参加したコンペでは、なんと95%もの精度を達成したチームも現れました。同じ設定でKuroNetを調査したところ精度は90%で、順位的には全体の12位だったことから、KuroNetを上回る精度のAIが多数開発されたことになります。
今回の結果から、既存のオブジェクト検出アルゴリズムの一部は、そのままくずし字認識においてうまく機能するケースが確認されるなど、いくつかの重要な教訓が学べたとラム氏は述べています。
AIで“くずし字”の解読に挑む | NHKニュース
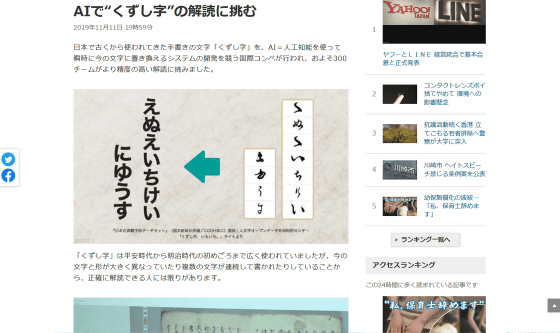
人文学オープンデータ共同利用センターが行ったデータセット作成により、くずし字を活字化するAIの開発は大幅に進歩したものの、依然として未解決の問題は多いとラム氏は指摘。たとえば、訓練データの多くが17世紀~19世紀の書物から選ばれていますが、くずし字の歴史はもっと長く、手書きの文書もあれば印刷されたものもあります。また、書籍の題名など一部のスタイルには非常に珍しいスタイルが使われていることも多いほか、石に彫られたくずし字ではまた違った形になる場合もあるとのこと。
そして、さらに魅力的な未解決の問題は、活字にされた文章をさらに現代語に翻訳するAIの開発です。くずし字が古文の状態になるだけでも、現代人にとって読みやすさが大幅に向上するのは確かですが、それでも単語や文法の違いは大きいもの。AIによって解読だけでなく翻訳も可能となれば、古典籍研究の上で大きな進歩となります。これらの問題を解決するためには、歴史的文書を調査する研究者や機械学習の研究者などが双方の知識を組み合わせる、学際的な取り組みが必要だとラム氏は主張しました。
・関連記事
GoogleのAIは古代ギリシャの碑文解読をものの数秒で行うことができるように - GIGAZINE
100年以上も解読されなかったヴォイニッチ手稿が「古いトルコ語で書かれている」とする説が登場 - GIGAZINE
1300年前の文書を近世に作られた本の装丁から発見、文字の解読にも成功 - GIGAZINE
バチカン図書館が貴重な4000冊もの古代写本をデジタル化して無料公開中 - GIGAZINE
文字を持たなかったインカ帝国で記録用に使われた結び目つきのひも「キープ」の解読に大学生が成功 - GIGAZINE
おばあちゃんが最期に残し20年間も未解決だった謎の暗号がネットの集合知によって爆速で解明へ - GIGAZINE
2世紀に建てられた巨大図書館の遺跡が発見される - GIGAZINE
「レンタル奴隷」などについて書かれた古代都市の契約書が発見される - GIGAZINE
古代ローマの遺跡から発見されたペンに彫られていた「ジョーク」とは? - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1h_ik
You can read the machine translated English article Researchers from overseas are also payin….