




AMDのサーバー向け64コアプロセッサ「EPYC Rome」を使用したベンチマーク結果をDellが公開

AMDのサーバー向けプロセッサである「EPYC Rome」の仕様および、DellのPower Edgeサーバーで前世代である「EPYC Naples」と比較した結果がDellから報告されています。
AMD Rome – is it for real? Architecture and initial HPC performance | Dell
https://www.dell.com/support/article/jp/ja/jpbsd1/sln319015/amd-rome-is-it-for-real-architecture-and-initial-hpc-performance?lang=en
AMDの第2世代EPYC CPUである「Rome」と、第1世代のEPYC CPU「Naples」のアーキテクチャ上における大きな違いの1つはI/Oダイの存在です。Romeは1個のI/Oダイと最大8個のコアキャッシュダイ(CCD)と呼ばれるCPUダイで構成された最大9個のマルチチップパッケージとして設計されています。
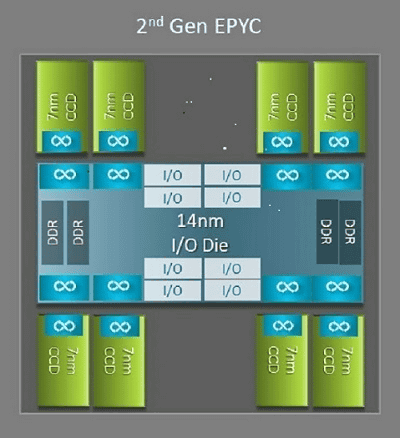
14nmのI/Oダイは、メモリコントローラ、ソケット間およびソケット内のInfinity Fabricによる相互接続、PCIeなど、すべてのI/Oおよびメモリ機能を担っています。ソケットごとに8つのメモリコントローラを持ち、メモリチャネルはDDR4を3200MT/sで実行可能です。シングルソケットシステムの場合はPCIe Gen4レーンを最大130までサポートでき、デュアルソケットシステムの場合はPCIe Gen4レーンを最大160までサポート可能です。
I/Oダイを囲む7nmのCCDには、Zen2マイクロアーキテクチャ、L2キャッシュ、容量32MBのL3キャッシュのCPUコアがあります。また、CCDには2つのコアキャッシュコンプレックス(CCX)があり、各CCXは最大4つのコアと容量16MBのL3キャッシュを持ちます。Romeのラインナップは各モデルごとにコアの数が異なりますが、中央にI/Oダイがあるという点で共通しています。

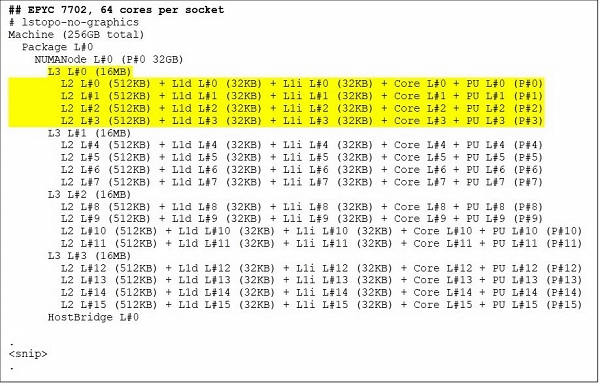
64コアCPUモデルであるEPYC 7702の場合、lstopoコマンドの出力を参照すると、プロセッサがソケットごとにCCXを16個備えていることがわかります。各CCXは4コアを備えているため、ソケットごとに64コア生成されていることが分かります。CCXあたり16MBのL3キャッシュを持っており、CCDあたり32MBのL3キャッシュがあるので、プロセッサには合計256MB L3キャッシュがあります。なお、各CCXにある16MBのL3キャッシュは独立しており、CCXのコアでのみ共有されるため、合計256MBのL3キャッシュはすべてのコアで共有されるわけではありません。
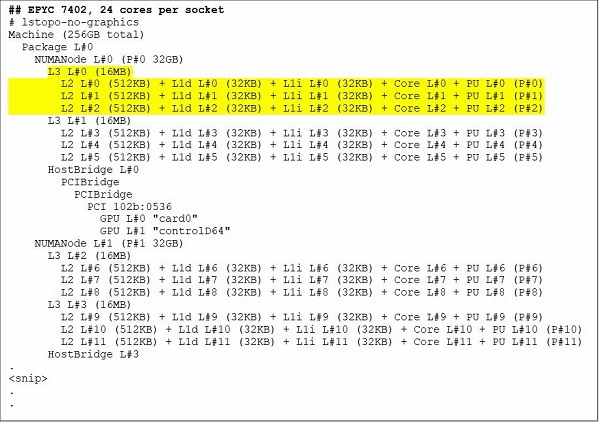
24コアCPUであるEPYC 7402には128MBのL3キャッシュがあります。lstopoコマンドの出力を参照すると、このモデルにはCCXごとに3つのコアがあり、ソケットごとに8つのCCXがあることがわかります。
RomeがI/Oダイを別に設けたことにより、メモリのレイテンシを改善する効果があります。さらに、CPUを単一のNUMAドメインとして構成することで、ソケット内のすべてのコアに対して均一なメモリアクセスが可能になります。
RomeプロセッサのCPUはNUMAドメインとして分割することができ、各NPSの特徴は以下の通りです。なお、すべてのCPUで上記すべてのNPS設定がサポートできるわけではありません。
NPS1:Rome CPUが単一のNUMAドメインとなり、すべてのコアと1つのNUMAドメイン、すべてのメモリが含まれます。メモリは8つのメモリチャネルにわたってインターリーブされ、PCIeデバイスはすべて単一のNUMAドメインに属します。
NPS2:CPUを2つのNUMAドメインに分割し、各NUMAドメインのソケットにコアとメモリチャネルの半分を分配します。メモリは各NUMAドメインの4つのメモリチャネルにインターリーブされます
NPS4:CPUを4つのNUMAドメインに分割します。各象限はここではNUMAドメインであり、メモリは各NUMAドメインの2つのメモリチャネルにインターリーブされます。PCIeデバイスはI/OダイのPCIeルートに応じて、ソケット上の4つのNUMAドメインのいずれかに属します。
Rome固有のBIOSオプションである優先I/Oデバイスは、InfiniBandの帯域幅とメッセージレートの調整を行い、I/Oデバイスのトラフィックに優先順位を付けることができます。このオプションはシングルソケットとデュアルソケットのプラットフォームで使用可能です。
以下の図はNPS4で実行したRomeのメモリ帯域幅テストの結果です。デュアルソケットPowerEdge C6525で、4つのCPUモデルでサーバーのすべてのコアを使用した結果を示す青いグラフは約270〜300GB/sのメモリ帯域幅を測定しました。CCXごとに1つのコアが使用される場合を示すオレンジのグラフは、システムメモリの帯域幅をすべてのコアで測定した帯域幅よりも9〜17%高くなっています。ソケットあたり8つのメモリチャネルをサポートしてるNaplesプラットフォームのメモリ帯域幅は2667MT/sで実行され、Romeプラットフォームは、Naplesよりもおよそ5%〜19%高いメモリ帯域幅を提供していることがわかります
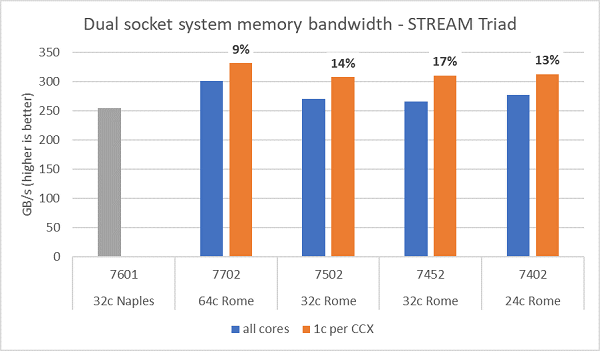
NPS構成ごとに比較すると、NPS1と比べてNPS4は約13%メモリ帯域幅が高くなっていました。

100Gbpsで動作するHDR100を使用して、単方向および双方向のシングルコアのInfiniBand帯域幅をプロットしたのが以下の画像です。グラフは予測値を表しており、青い線が単方向、オレンジの線が双方向の帯域幅です。
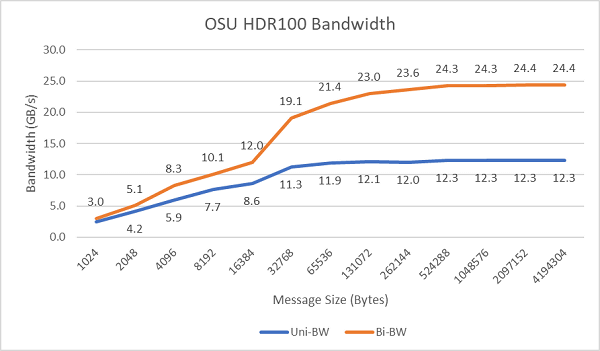
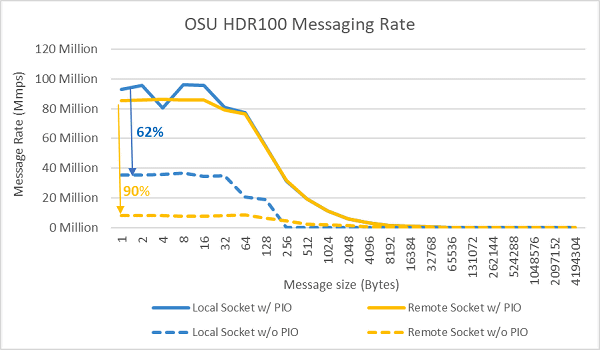
2台のサーバーのソケット上のすべてのコアを使用して、メッセージレートのテストを実施した結果が以下の画像です。優先I/Oを有効にし、優先デバイスとしてConnectX-6 HDR100アダプターを設定した青い線は、優先コアを有効にしていない黄色の線よりもメッセージレートが高くなっています。優先コアの設定は、HPC、特にマルチノードアプリケーションのスケーラビリティを調整する場合に有効であると考えられます。
Romeのマイクロアーキテクチャは16FLOP/cycleで、Naplesの8FLOPS/cycleの約2倍となっています。理論上、Naplesと比較してRomeのFLOPSは4倍、拡張浮動小数点演算能力が2倍と言えます。NPS4のRomeCPUモデルにおけるHPLの測定結果とNaplesの測定結果を示したのが以下の図です。

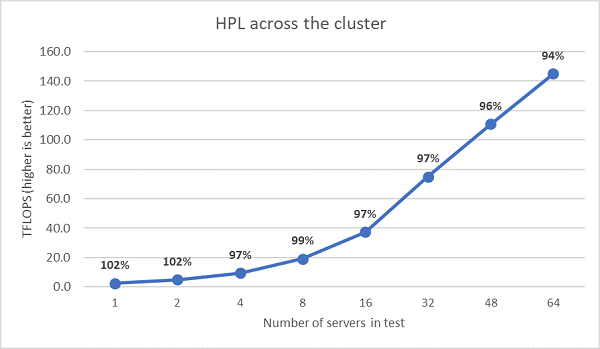
次にEPYC 7452でマルチノードHPLテストを実行した結果を以下の図にプロットしています。HPL効率は64ノードスケールで90%を超えていますが、効率が102%から97%に低下するため、さらなる評価が必要です。
Romeベースのサーバーの初期パフォーマンス調査は、期待通りの結果が示されました。 最高のパフォーマンスを実現するためにはBIOSの設定が重要です。DellのPower Edgeサーバーの場合は、EMCシステム管理ユーティリティのBIOS HPCワークロードプロファイルで設定できます。
・関連記事
64コア/128スレッドのAMDのモンスタープロセッサ「AMD EPYC 7742」が驚異のベンチマーク結果を達成 - GIGAZINE
AMDのサーバー向けプロセッサ「EPYC Rome」発売を「歴史的なこと」と専門家が絶賛 - GIGAZINE
ハイエンドPC向けの高級CPUで上手にパンケーキを焼けるのはIntelとAMDのどちらなのか? - GIGAZINE
NVIDIAがゲーミングブランドからAMDを締め出そうとしている「GeForce Partner Program」問題とは? - GIGAZINE
90年代にすい星のごとく現れGPUトップ企業に上り詰めるも爆速で消えていった「3dfx Interactive」 - GIGAZINE
・関連コンテンツ








in ハードウェア, Posted by darkhorse_log
You can read the machine translated English article Dell releases benchmark results using AM….