Dell releases benchmark results using AMD's 64-core processor 'EPYC Rome' for servers

Dell
AMD Rome – is it for real? Architecture and initial HPC performance | Dell
https://www.dell.com/support/article/jp/en/jpbsd1/sln319015/amd-rome-is-it-for-real-architecture-and-initial-hpc-performance?lang=en
One of the major differences in architecture between AMD's 2nd generation EPYC CPU 'Rome' and the 1st generation EPYC CPU 'Naples' is the presence of I / O dies . Rome is designed as a multi-chip package with up to nine CPU dies called one I / O die and up to eight core cache dies (CCD).
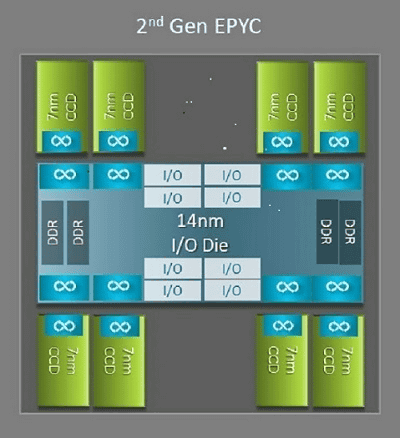
The 14nm I / O die is responsible for all I / O and memory functions such as memory controllers, interconnects between and within sockets with Infinity Fabric, and
The 7nm CCD that surrounds the I / O die has a Zen2 microarchitecture, an L2 cache, and a 32MB L3 cache CPU core. The CCD also has two core cache complexes (CCX), each CCX having up to 4 cores and an L3 cache with a capacity of 16MB. The Rome lineup has the same number of cores for each model, but is common in that there is an I / O die in the center.

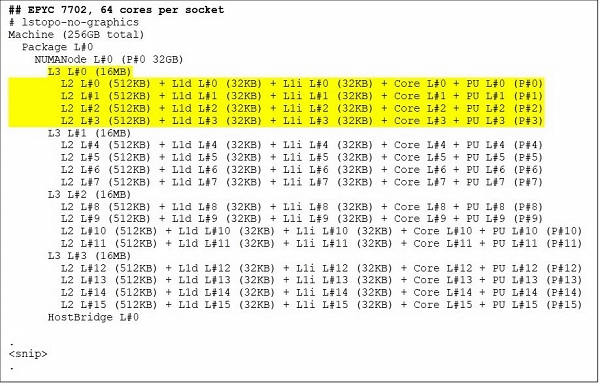
For EPYC 7702, which is a 64-core CPU model, looking at the output of the lstopo command, you can see that the processor has 16 CCXs per socket. Since each CCX has 4 cores, you can see that 64 cores are generated per socket. The processor has a total of 256MB L3 cache because there is 16MB L3 cache per CCX and 32MB L3 cache per CCD. Note that the 16MB L3 cache in each CCX is independent and is shared only by the CCX core, so the total 256MB L3 cache is not shared by all cores.
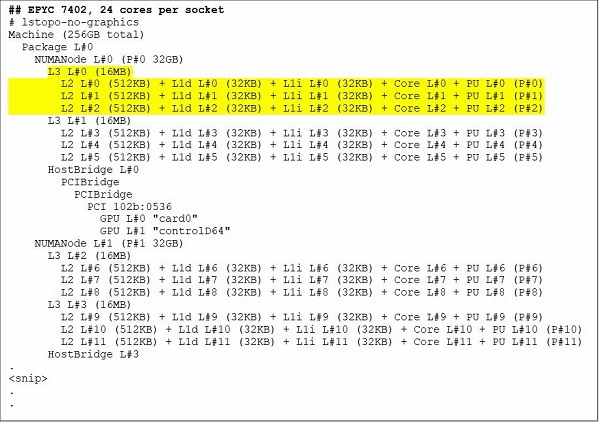
EPYC 7402, a 24-core CPU, has a 128MB L3 cache. If you look at the output of the lstopo command, you can see that this model has three cores per CCX and eight CCXs per socket.
Rome has an additional I / O die, which has the effect of improving memory latency. In addition, configuring the CPU as a single NUMA domain enables uniform memory access to all cores in the socket.
The CPU of the Rome processor can be divided into NUMA domains, and the characteristics of each NPS are as follows. Not all CPUs can support all the above NPS settings.
NPS1: Rome CPU becomes a single NUMA domain, including all cores, one NUMA domain, and all memory. Memory is interleaved across eight memory channels, and all PCIe devices belong to a single NUMA domain.
NPS2: Divides the CPU into two NUMA domains and distributes half of the core and memory channels to each NUMA domain socket. Memory is interleaved on four memory channels in each NUMA domain
NPS4: The CPU is divided into 4 NUMA domains. Each quadrant is here a NUMA domain, and the memory is interleaved into two memory channels in each NUMA domain. PCIe devices belong to one of the four NUMA domains on the socket, depending on the I / O die PCIe root.
Priority I / O devices, Rome-specific BIOS options, can adjust InfiniBand bandwidth and message rate to prioritize I / O device traffic. This option is available for single socket and dual socket platforms.
The figure below shows the results of Rome's memory bandwidth test performed on NPS4. A blue graph showing the results of using all the cores of the server on a dual-socket PowerEdge C6525 with four CPU models measured approximately 270-300GB / s of memory bandwidth. The orange graph, which shows when one core is used per CCX, is 9 to 17% higher in system memory bandwidth than measured across all cores. You can see that the Naples platform, which supports 8 memory channels per socket, runs at 2667MT / s, and the Rome platform offers approximately 5% to 19% higher memory bandwidth than Naples.
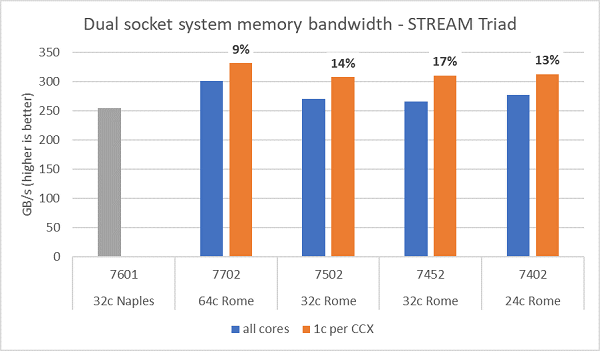
Compared to each NPS configuration, NPS4 had about 13% higher memory bandwidth than NPS1.

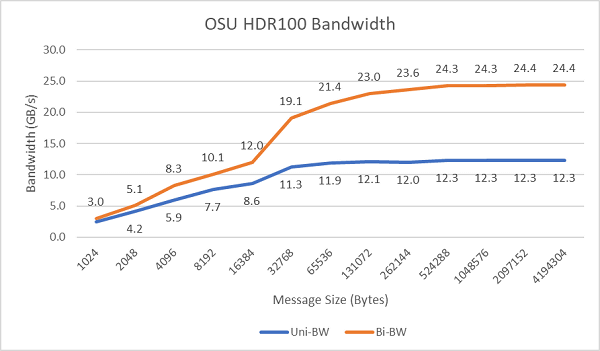
The following image plots unidirectional and bidirectional single-core InfiniBand bandwidths using HDR100 operating at 100Gbps. The graph shows the predicted value, where the blue line is the unidirectional bandwidth and the orange line is the bidirectional bandwidth.
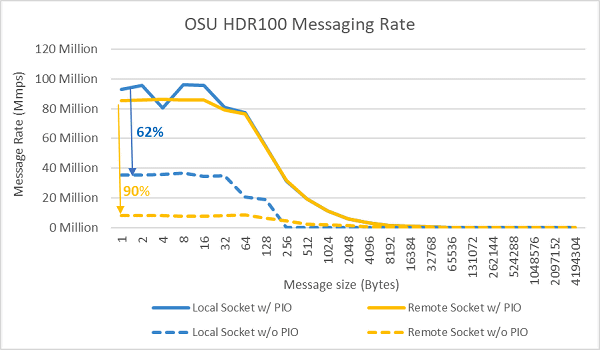
The following image shows the result of a message rate test using all cores on the sockets of two servers. The blue line with priority I / O enabled and the ConnectX-6 HDR100 adapter set as the priority device has a higher message rate than the yellow line without priority core enabled. The preferred core setting can be useful for tuning the scalability of HPC, especially multi-node applications.
Rome's microarchitecture is 16FLOP / cycle, about twice that of Naples' 8FLOPS / cycle. Theoretically, compared to Naples, Rome's FLOPS can be said to be 4 times, and the expanded floating-point computing power is 2 times. The following figure shows the

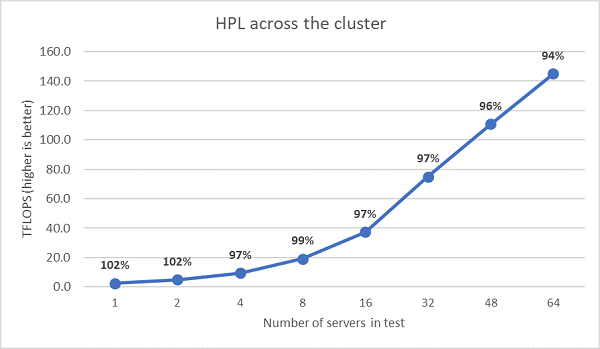
Next, the results of running a multi-node HPL test on EPYC 7452 are plotted in the following figure. HPL efficiency is over 90% on a 64 node scale, but efficiency drops from 102% to 97% and requires further evaluation.
An initial performance study of Rome-based servers showed the expected results. BIOS settings are important for best performance. For Dell Power Edge servers, it can be set in the BIOS HPC workload profile in the EMC System Management Utility.
Related Posts:








in Hardware, Posted by darkhorse_log